上周五晚上,我在给 ai-notepad 项目加一个功能:让 AI Agent 能自动发现并安装这个项目的 Skill。写完 SKILL.md、落地页、版本同步脚本后,我突然意识到一件事——这套流程已经不是「锦上添花」,而是应用交付的新底线。
如果你今天做一个应用,却没有提供 CLI 和 Skill,就像 2010 年做一个 Web 服务却没有 API 一样——用户(包括 AI Agent)根本用不了你。
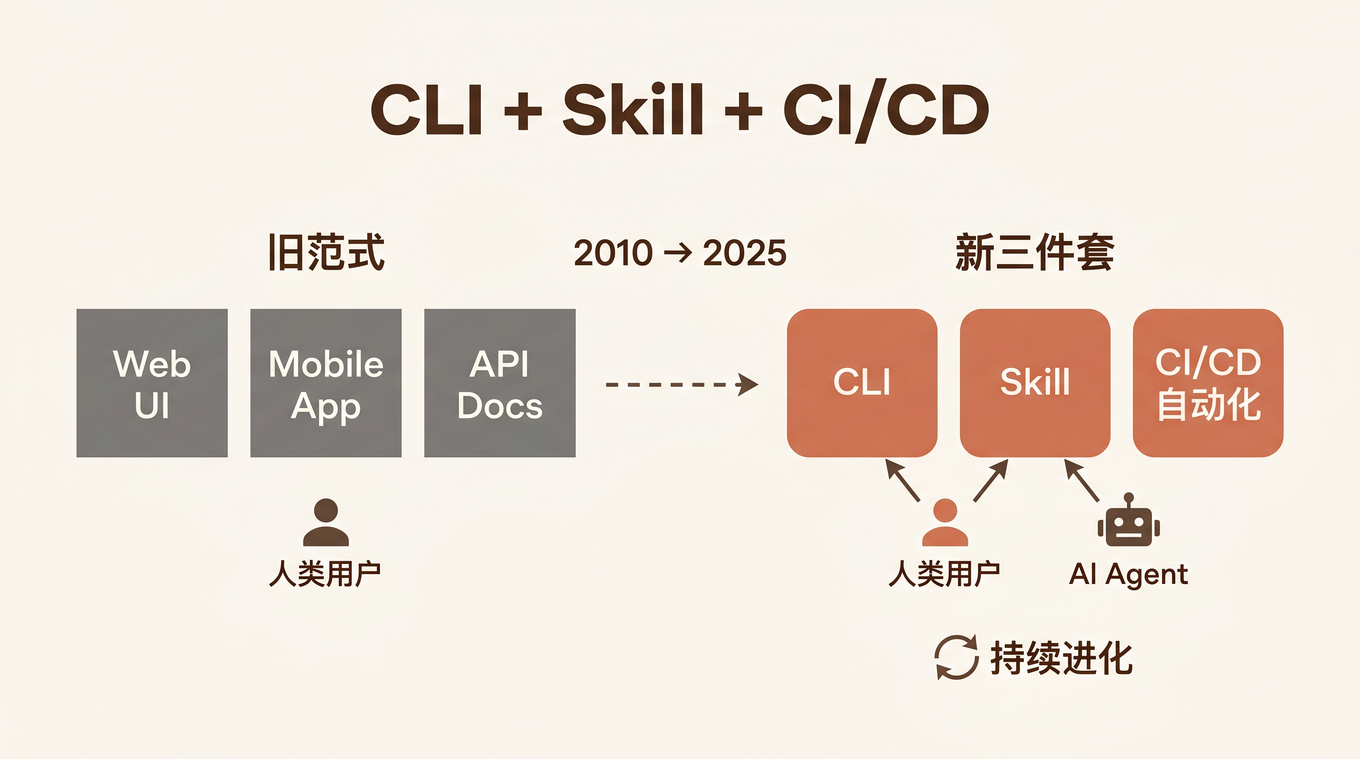
为什么是「新三件套」
在 API、MCP 和 Skills:三个概念的本质区别 中,我用餐厅的比喻解释了三者的区别。但知道区别是一回事,把它们做进产品里是另一回事。
传统应用的交付物是什么?一个 Web UI,一个移动端 App,也许再加一套 API 文档。但在 AI Agent 时代,这个清单需要更新:
传统三件套 新三件套
┌─────────────┐ ┌─────────────┐
│ Web UI │ │ CLI │ ← 人 + Agent 都能用
│ Mobile App │ │ Skill │ ← Agent 专用入口
│ API Docs │ │ CI/CD 自动化│ ← 保持三者同步
└─────────────┘ └─────────────┘
区别在哪里?
CLI 是人和 Agent 的公共入口。 人类在终端敲命令,Agent 通过工具调用执行——同一个 CLI,两种用户。而 Web UI 只有人类能用,API 只有程序能调,CLI 是唯一同时服务两种用户的接口。
Skill 是 Agent 的「使用说明书」。 它不是给人看的 README,而是结构化的 Markdown(带 YAML frontmatter),让 Agent 能机器解析、自动加载、直接执行。
CI/CD 自动化是保持三者同步的粘合剂。 版本号在 package.json、SKILL.md、落地页三处不一致?Agent 拿到的 Skill 是旧版?这些坑只有自动化能根治。
一个贯穿案例:ai-notepad
我不打算泛泛而谈。接下来用一个真实项目——ai-notepad(我的笔记应用)——来走完整条链路。
第一步:写 SKILL.md
SKILL.md 是 Skill 的本体。Agent 安装时读取它的全部内容,作为系统提示的一部分。结构很简单:
---
name: ai-notepad
description: "Manage Hugo's Notebook notes from terminal — list, read, create, update, delete, search, publish."
version: '1.2.7'
author: hugozhu
license: MIT
metadata:
hermes:
tags: [notes, notepad, writing, supabase, cli]
---
# AI Notepad CLI
Manage notes in Hugo's Notebook (hugozhu.site/notes) from the terminal.
## Auth
...
## Commands
...
# generated by hugo AI
这个文件看起来就是一个普通的 Markdown 文件,但它和普通 README 有三个本质区别:
- YAML frontmatter —— Agent 可以机器解析 name、version、tags,决定要不要加载
- 结构化的命令文档 —— Agent 读完就知道怎么调用 CLI
- 版本声明 —— Agent 可以检查自己持有的版本是否过期
第二步:一行 curl 安装
Skill 的价值不在于写出来,在于 装上去。各主流 AI Agent 的安装方式都是一行命令:
# Claude Code
curl -o .claude/skills/ai-notepad.md https://hugozhu.site/skills/ai-notepad/SKILL.md
# Cursor
curl -o .cursor/rules/ai-notepad.mdc https://hugozhu.site/skills/ai-notepad/SKILL.md
# OpenCode
curl -o .opencode/skills/ai-notepad.md https://hugozhu.site/skills/ai-notepad/SKILL.md
# generated by hugo AI
更进一步,Agent 还可以 自发现 可用 Skill:
curl -s https://hugozhu.site/.well-known/agent-skills.json
# generated by hugo AI
这就像 2010 年代的 API 发现机制(Swagger/OpenAPI),但面向的用户从开发者变成了 Agent。
第三步:版本同步自动化
这是最容易遗漏、也是最关键的一环。项目里有多处版本号:
| 文件 | 用途 |
|---|---|
package.json | npm 版本号 |
index.html | 页脚展示 |
skills/ai-notepad/SKILL.md | Skill frontmatter |
skills/ai-notepad/index.html | 落地页(CI 构建生成) |
手动同步必然出错。我在实践中踩过三个坑:
坑一:husky 只 add 了部分文件。 version-bump.sh 改了 SKILL.md,但 .husky/pre-commit 只 git add 了 package.json index.html js/i18n.js,导致 SKILL.md 的版本变更没进提交。提交后 package.json 是 v1.2.6,SKILL.md 还是 v1.2.5。
坑二:pre-commit 里调 build-skill-docs.js 导致冲突。 这个脚本会重新生成整个 skills/ai-notepad/index.html(内容变化大),和 lint-staged 的 stash/restore 机制冲突。修复方案:pre-commit 只负责 SKILL.md 的版本 bump,CI 构建时再生成落地页。
坑三:多次 bump 导致版本号跳跃。 反复尝试修复的过程中,版本号从 1.2.1 一路蹦到了 1.2.7。每次 commit 都会触发 pre-commit 再 bump 一次。教训:先把自动化链路跑通再发布。
最终的分工很清晰:
#!/bin/bash
# scripts/version-bump.sh
# pre-commit hook 调用,自动 bump patch 版本号
VERSION=$(node -p "require('./package.json').version")
NEW_VERSION=$(node -p "
const [m,n,p] = '$VERSION'.split('.');
\`\${m}.\${n}.\${parseInt(p)+1}\`
")
# 同步更新所有版本号
npm version patch --no-git-tag-version --silent
sed -i "s/version: '$VERSION'/version: '$NEW_VERSION'/" \
skills/ai-notepad/SKILL.md
echo "Bumped $VERSION → $NEW_VERSION"
# generated by hugo AI
pre-commit hook CI 构建(deploy.yml)
┌──────────────────┐ ┌──────────────────────┐
│ version-bump.sh │ │ build-skill-docs.js │
│ bump 版本号 │ │ 从 SKILL.md 生成 │
│ git add 所有文件 │────→│ 落地页 index.html │
│ │ │ docker build + push │
└──────────────────┘ └──────────────────────┘
hook 只管 bump 和 stage,CI 只管构建和部署。职责不交叉,版本号永远一致。
「README 就够了」是个错觉
最常见的反对意见是:「Skill 不就是 Markdown 吗?我的 README 已经写得很好了,Agent 直接读不就行?」
这就像 2010 年有人说「我的 HTML 页面已经写得很好了,为什么还要做 API?」
README 和 Skill 的本质区别在于三点:
1. 结构化元数据。 YAML frontmatter 让 Agent 能机器解析——name、version、tags 都是可计算字段。README 是给人看的散文,Skill 是给 Agent 读的结构化数据。
2. 版本同步自动化。 README 的版本号?没人管。Skill 的版本号由 pre-commit hook + CI 自动同步,Agent 拿到的永远是最新版。
3. 自发现机制。 .well-known/agent-skills.json 让 Agent 主动找到并安装 Skill,不需要人类手动拷贝 URL。README 没有这个能力。
| 维度 | README | Skill |
|---|---|---|
| 目标读者 | 人类开发者 | AI Agent |
| 元数据 | 无结构化声明 | YAML frontmatter |
| 版本管理 | 手动更新 | 自动化同步 |
| 发现机制 | GitHub search | .well-known 自发现 |
| 安装方式 | 拷贝粘贴 | 一行 curl |
AI coding 不是锦上添花,是效率杠杆
现在回到观点的另一半: 这套流程应该通过 AI coding 来完成。
为什么?因为三件套的工程量和维护成本,对个人开发者或小团队来说,纯手工做不起。
以 ai-notepad 为例,整个过程包括:
- 写 SKILL.md(Markdown + YAML,本身不复杂)
- 写
build-skill-docs.js(从 SKILL.md 生成落地页,带深色/浅色模式自适应) - 写
version-bump.sh(多文件版本号同步) - 配置
.husky/pre-commit(hook 链路) - 配置
.github/workflows/deploy.yml(CI 构建 + 部署) - 配置
.well-known/agent-skills.json(自发现) - 踩坑、修复、迭代
这些工作单独看都不难,但加起来是一个完整的工程链路。 用 AI coding(Hermes Agent)来做,从写第一个 SKILL.md 到跑通整条 CI/CD 流水线,一个晚上搞定。 如果纯手工,光调试 pre-commit 和 lint-staged 的冲突就可能耗掉一整天。
AI coding 的价值不仅是加速,更是 降低全链路工程的门槛。一个擅长写产品的开发者,不需要精通 husky、lint-staged、GitHub Actions 的每个细节——告诉 Agent 你要什么,让它来踩坑。正如我在 Claude Code 的自动纠错 Agent Loop 中记录的,AI coding 的核心价值不是「写代码更快」,而是「让不可能的工程变得可能」。
持续进化:Skill 不是一次性交付
最后一点,也是最容易被忽略的: Skill 不是写完就完了,它需要持续进化。
ai-notepad 的 Skill 从 v1.2.1 到 v1.2.7,经历了多次迭代:
- 补全了认证流程的详细文档(auto-auth flow for DingTalk users)
- 增加了 annotations 功能的命令说明
- 修复了 shell glob expansion 的坑(密码里的特殊字符)
- 增加了 JWT token truncation 的警告
每次迭代,开发者只需要修改 SKILL.md,commit 一下——pre-commit hook 自动 bump 版本号,CI 自动重新生成落地页,自动部署。 用户侧的 Agent 下次拉取时自动拿到最新版。
这就是「持续进化」的含义:不是一次性交付一个完美的 Skill,而是建立一个 让 Skill 随应用一起生长的机制。
修改 SKILL.md → git commit → pre-commit bump → CI build → deploy
↑ ↓
└──── 发现问题 / 新增功能 ←── Agent 使用反馈 ←──┘
总结
如果你今天在做一个新的应用或工具,我建议你把这三件事当作交付的底线:
- CLI —— 让人和 Agent 都能用你的工具
- Skill —— 让 Agent 能发现、安装、理解你的工具
- CI/CD 自动化 —— 让版本永远同步,让 Skill 持续进化
这三件事的工作量,用 AI coding 来做,一个晚上可以搞定。不用 AI coding,同样的工程链路需要更多的调试和踩坑时间。
2010 年,没有 API 的应用是半成品。2025 年,没有 CLI + Skill 的应用也是半成品。
区别只是,2010 年的用户是人类开发者,2025 年的用户是 AI Agent。
你在实际项目中给 Agent 做过 Skill 吗?踩过什么坑?欢迎留言讨论。