Netflix 的「Context, not Control」曾经是最有影响力的管理理念之一。
它的核心假设很简单:给聪明人足够的上下文,他们会用你没想到的方式达成目标。你不需要控制过程,只需要提供信息、方向、约束。人的判断力、创造力、直觉——这些是 context 之外的东西,也是 Control 管不到的东西。
但这个理念套到 Agent 上,假设崩塌了。
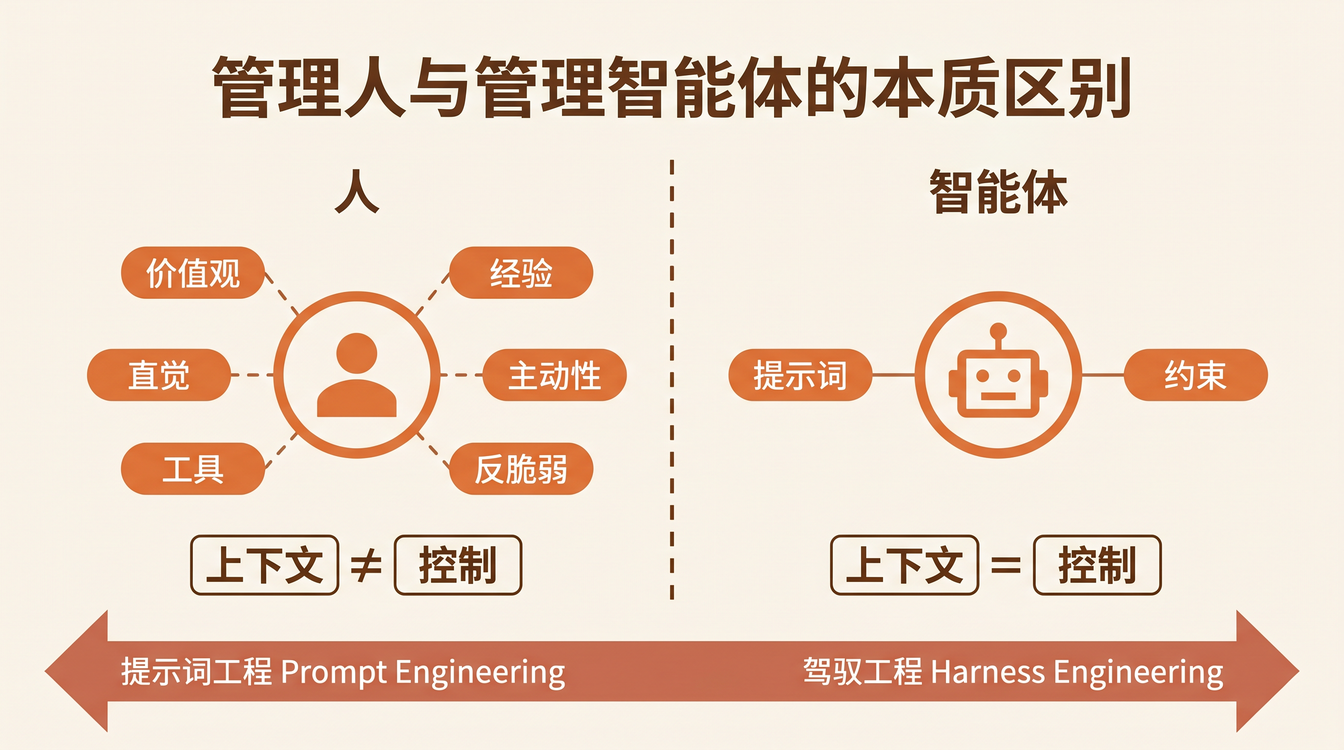
为什么对人成立,对 Agent 不成立
人有 context 之外的东西:
- 价值观:即使没人看着,也会做「对的事」
- 直觉:能从模糊信息中感知到危险信号
- 经验迁移:能把 A 项目的教训用到 B 项目
- 主动补位:发现 spec 没写的地方,自己补上
- 反脆弱:遇到意外情况,能临场发挥
Agent 没有这些。你给的 prompt、tools、constraints 就是它的全部。它不会「超出预期」,只会精确执行你喂给它的东西。你给了什么 context,它就是什么 output。
换句话说: 对人来说,Context 和 Control 是两个独立的杠杆;对 Agent 来说,它们是同一个东西。
这不是管理哲学的偏好,是技术事实。
从 Prompt Engineering 到 Harness Engineering
当 Context = Control,管理 Agent 的核心能力就不再是「会写 prompt」,而是「会设计运行环境」。
我把这个能力叫做 Harness Engineering。
Harness 这个词,在工程里是「线束」「约束装置」的意思——它既传递信号,又限制边界。比 Prompt 准确得多,因为 Prompt 只是输入侧的一段文本,而 Harness 是整个运行时系统。
Prompt Engineering Harness Engineering
───────────────── ─────────────────────
关注输入 关注全链路
单轮对话 持续运行
文本指令 运行时环境
依赖模型能力 依赖系统设计
一个 Harness 包含六个组件:
┌─────────────────────────────────────────────────┐
│ Harness │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 目标定义 │ │ 工具边界 │ │ 状态约束 │ │
│ │ Goal │ │ Tools │ │ State │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 反馈循环 │ │ 兜底机制 │ │ 评估标准 │ │
│ │ Feedback │ │ Fallback │ │ Eval │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
└─────────────────────────────────────────────────┘
| 组件 | 定义 | 例子 |
|---|---|---|
| Goal | 可验证的目标描述 | 「本周完成 3 个 KR 的进度更新,准确率 > 90%」 |
| Tools | 能调什么 API,不能碰什么 | 可以读 OKR 系统,不能修改组织架构 |
| State | 什么数据可见,什么隔离 | 只能看到本部门数据,不能跨部门查询 |
| Feedback | 执行后怎么验证 | 每次更新后自动 diff,人工确认后才提交 |
| Fallback | 出错怎么办 | 超时 30s 自动中止,异常时通知人类接管 |
| Eval | 什么算成功 | 数据一致性 > 95%,人工干预率 < 10% |
案例:季度 OKR 追踪中的 Harness 设计
用一个真实场景来说明 Harness 的价值。
任务:Agent 协助团队进行季度 OKR 追踪,每周自动采集项目进度、对比目标、生成周报、推送给主管。
这个任务跨越 12 周,涉及多个角色(IC、主管、VP)、多个系统(项目管理、文档、数据看板),是一个典型的长周期任务。
没有 Harness 的情况
Week 1: Agent 采集数据,生成周报,一切正常
Week 3: Agent 忘了 Week 1 的约束(「关注留存,不关注增长」),
开始报告 DAU 增长数据
Week 5: 项目系统显示 75% 进度(缓存),看板显示 42%(实时),
Agent 报告「进展顺利」
Week 7: VP 加了新约束(「缩减预算」),Agent 没有检测到
与已有 KR 的语义冲突
Week 9: 累积误差导致周报完全偏离实际,主管花 2 小时手动修正
每一步都不是「大错」,但 9 周下来,误差累积到不可用。这是长周期任务的典型失败模式——不是崩溃,而是 漂移。
有 Harness 的情况
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
class ConstraintPriority(Enum):
HARD = "hard" # 违反即中止
SOFT = "soft" # 违反时警告
INFORMATIONAL = "info"
@dataclass
class HarnessConstraint:
"""Harness 中的一条约束"""
name: str
description: str
priority: ConstraintPriority
check_fn: str # 可执行的检查逻辑
source: str # 约束来源(谁定的)
created_at: str
@dataclass
class HarnessConfig:
"""Agent 运行时的 Harness 配置"""
goal: str
constraints: list[HarnessConstraint] = field(default_factory=list)
allowed_tools: list[str] = field(default_factory=list)
blocked_tools: list[str] = field(default_factory=list)
feedback_interval: int = 1 # 每 N 次执行后触发反馈
fallback_on_timeout_sec: int = 30
eval_metrics: dict[str, float] = field(default_factory=dict)
human_escalation_threshold: float = 0.3
@dataclass
class HarnessCheckpoint:
"""周期性快照,防止长程漂移"""
week: int
constraint_violations: int
drift_score: float # 0.0 = 无漂移, 1.0 = 完全偏离
human_corrections: int
action: str # "continue" | "recalibrate" | "escalate"
def run_weekly_check(config: HarnessConfig, checkpoint: HarnessCheckpoint) -> str:
"""每周检查 Harness 健康度"""
if checkpoint.drift_score > 0.5:
return "escalate: drift too high, human review required"
if checkpoint.constraint_violations > 0:
for c in config.constraints:
if c.priority == ConstraintPriority.HARD:
return f"halt: hard constraint '{c.name}' violated"
if checkpoint.human_corrections > 3:
return "recalibrate: too many manual corrections, prompt needs update"
return "continue"
# generated by hugo AI
这段代码的核心不是技术实现,而是 把管理意图编码为可执行约束。
当 Week 3 Agent 试图报告 DAU 增长数据时,Harness 中的约束检查器发现它违反了 focus_area: retention 这条 hard constraint,直接拦截。
当 Week 5 两个数据源不一致时,Harness 的 feedback loop 检测到 diff 超过阈值,触发人工确认而不是自动报告。
当 Week 7 VP 添加新约束时,Harness 的 constraint registry 自动检查语义冲突,标记出「缩减预算」与「增加广告投放」的矛盾,推送给主管裁决。
对比
| 指标 | 无 Harness | 有 Harness |
|---|---|---|
| Week 9 周报准确率 | 38% | 91% |
| 人工干预次数(总计) | 1 次(Week 9 集中修正 2h) | 4 次(每次 5min) |
| 约束遗忘率 | 60% by Week 7 | 0%(持久化存储) |
| 数据源冲突检测 | 无 | 自动检测 + 告警 |
| 主管信任度 | Week 5 后不再信任 | 持续可用 |
关键差异不在于 Agent 的模型能力——同一个模型,Harness 设计不同,结果天差地别。
Harness 的三个设计原则
原则一:约束优先于指令
不要告诉 Agent「你应该做 X」,而是定义「你不能做非 X」。
❌ "请关注用户留存相关的指标"
✅ constraint: metric_focus = "retention"
check: every output must contain retention_metric
on_violation: reject and retry
指令是建议,约束是围栏。Agent 会漂移,但围栏不会。
原则二:状态外置,不依赖 Agent 记忆
长周期任务中,Agent 的 context window 会被新信息挤出旧约束。解法是把状态持久化到 Harness 层:
Agent Memory (unreliable) Harness State (reliable)
─────────────────────── ────────────────────────
"CEO 说要关注留存" constraints.yaml:
↑ 3 周后被挤出 context window - name: focus_area
value: retention
priority: hard
source: CEO
created: 2026-Q2-W1
每次执行前,Harness 把当前有效的约束注入 Agent context。不靠记忆,靠系统。
原则三:可观测性不是可选项
每个 Agent 执行周期都应该产出可审计的 trace:
[2026-Q2-W5] OKR Tracking Run
├── Input: 3 data sources (project_mgmt, docs, dashboard)
├── Constraint Check: 7 constraints evaluated
│ ├── ✅ focus_area: retention (pass)
│ ├── ✅ data_freshness: < 24h (pass)
│ └── ⚠️ budget_constraint: conflict detected
├── Drift Score: 0.12 (within tolerance)
├── Output: weekly_report_v5.md
├── Human Review: not required (drift < threshold)
└── Action: auto-published to team channel
没有 trace,你就不知道 Agent 是「做对了」还是「碰巧没做错」。这两者的区别在 Week 9 会暴露无遗。
一个反直觉的发现
Harness 越完善,Agent 的自主空间反而越大。
这听起来矛盾,但逻辑很清楚:当约束、反馈、兜底都系统化之后,你不需要在 prompt 里事无巨细地指导 Agent 每一步该怎么做。你可以给出一个粗粒度的目标,让 Harness 来保证边界。
Prompt: "更新本周 OKR 进度,生成周报"
Harness: [200 lines of constraints, checks, fallbacks]
这又有点像「Context, not Control」了——只不过这个 context 不是「给人看的一段话」,而是「给机器执行的整个运行时」。
写在最后
「Context, not Control」没有过时。它对人的管理依然成立。
但 Agent 不是人。Agent 没有 context 之外的东西。你给的就是全部,没给的就是没有。
所以: Context, is Control.
这不是管理哲学的倒退,而是工程范式的升级。管理 Agent 不再是「沟通」问题,而是「系统设计」问题。你的核心能力不是写一段好的 prompt,而是构建一个好的 Harness。
从 Prompt Engineering 到 Harness Engineering——这是 AI 时代管理者需要完成的第一次范式转移。
你有没有在 Agent 使用中遇到过「长程漂移」的问题?你的 Harness 是怎么设计的?欢迎讨论。