一个工程师修了一个 Bug,ROI 是多少?
传统算法:节省了一次排查时间。AI 时代的算法:如果这个修复沉淀为 Harness 的一部分,AI 以后能自动修多少个类似的 Bug。
这就是思维范式的根本转变——你修的每一个 Bug,都是一次训练数据。不是训练模型,而是训练你项目周围的那套 Harness。
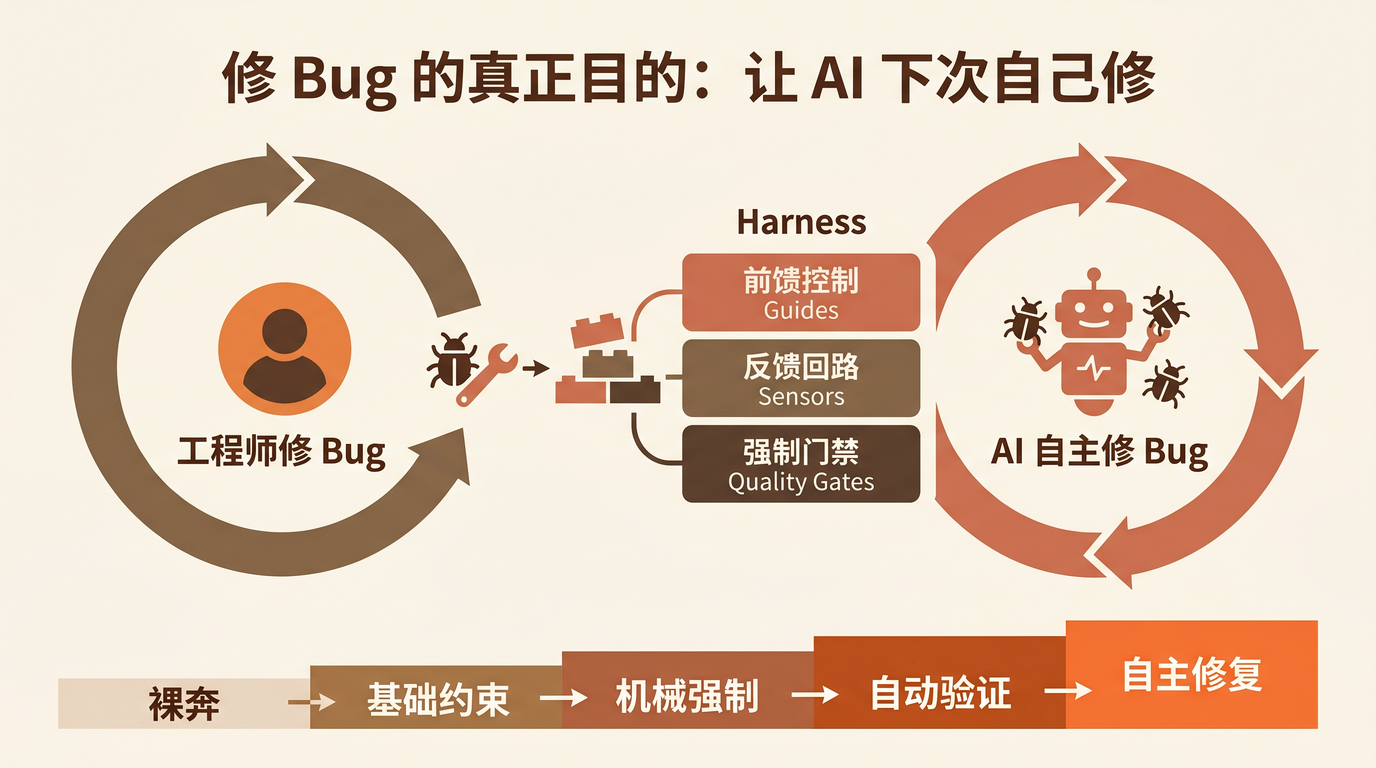
什么是 Harness
先对齐概念。LangChain 的定义最精准:
Agent = Model + Harness
Harness 不是 prompt,不是 context,是 模型之外的整个环境——脚手架、约束、反馈循环、上下文生命周期管理、错误恢复、沙箱、文档基础设施。
SWE-bench 的数据最有说服力: 同一个底层模型,不同的 Harness 实现之间可以有 20-30 个百分点的性能差距。也就是说,Harness 比模型选型更重要。
在 Claude Code 的语境下,Harness 有三层:
┌─────────────────────────────────────────────────┐
│ Harness 全景 │
├──────────────┬──────────────┬───────────────────┤
│ Guides │ Sensors │ Quality Gates │
│ (前馈控制) │ (反馈回路) │ (强制门禁) │
├──────────────┼──────────────┼───────────────────┤
│ CLAUDE.md │ TypeScript │ CI/CD Pipeline │
│ AGENTS.md │ ESLint │ Git Hooks │
│ .claude/ │ Pytest │ PR Review Bot │
│ rules/ │ Playwright │ Mutation Test │
│ Skills │ Structured │ Dependency │
│ │ Error Msgs │ Staleness Gate │
│ Architecture │ │ │
│ Docs │ │ │
└──────────────┴──────────────┴───────────────────┘
- Guides (前馈控制):在 Agent 行动之前缩小解空间
- Sensors (反馈回路):在 Agent 行动中提供结构化错误信号,让它自我修正
- Quality Gates (强制门禁):阻止不合规代码进入主干
7 个关键动作:把 Bug 修复变成 AI 能力
以下每个动作都遵循一个原则: 工程师今天修一个 Bug,AI 明天能自己修一类 Bug。
动作 1:Regression Test——让 Bug 可复现
这是最基础也最重要的一步。修完 Bug,第一件事不是提交,而是写一个让 Bug 暴露的测试。
Claude Code 实战:
# 不要只说 "fix the bug"
$ claude "users report that login fails after session timeout.
check the auth flow in src/auth/,
especially token refresh.
write a FAILING test that reproduces the issue,
then fix it"
关键在 write a FAILING test——TDD 的 Red-Green-Refactor 循环。Claude Code 的 TDD skill 会强制执行:
🔴 Red: 写一个失败测试,确认 Bug 可复现
🟢 Green: 写最小修复代码,让测试通过
🔵 Refactor: 重构,保持测试通过
为什么这能赋能 AI? 回归测试就是一个 Bug 的「指纹」。下次类似的 Bug 出现,AI 可以:
- 看到测试失败 → 知道问题在哪
- 有明确的「通过」标准 → 知道什么时候修好了
- 有现成的验证手段 → 可以自主确认修复正确
动作 2:结构化错误信息——给 AI 可读的诊断信号
Augment Code 的 Harness Engineering 指南里有一条关键原则:
Lint messages must become actionable prompts.
「violation detected」requires human interpretation.「use logger.info({event: 'name', ...data}) instead of console.log」enables autonomous fixes.
反面案例:
Error: Something went wrong
正面案例:
{
"error_code": "AUTH_TOKEN_EXPIRED",
"context": {
"user_id": "u_123",
"token_expired_at": "2026-05-25T10:00:00Z",
"refresh_endpoint": "/api/auth/refresh"
},
"suggested_action": "Call refresh endpoint with valid refresh_token"
}
在 CLAUDE.md 里写清楚你的错误码体系:
# Error Handling
- All API errors use structured format: { error_code, context, suggested_action }
- Error codes follow pattern: MODULE_ACTION_REASON (e.g., AUTH_TOKEN_EXPIRED)
- When fixing errors, always add structured context fields
- Never return raw stack traces to clients
AI 读到这种 CLAUDE.md,下次遇到一个裸 stack trace,它自己就知道该改成结构化格式。
动作 3:最小复现 Fixture——缩短 AI 的调试路径
Bug 触发往往需要特定的输入条件。把这些条件固化成 fixture 文件,等于给 AI 一个「一键复现」的按钮。
tests/
├── fixtures/
│ ├── expired_session.json # 过期 session 的完整状态
│ ├── malformed_webhook.json # 畸形 webhook payload
│ └── race_condition_setup.py # 竞态条件的初始化脚本
# tests/test_session_refresh.py
import json
from pathlib import Path
FIXTURES = Path(__file__).parent / "fixtures"
def test_session_timeout_recovery():
"""Regression: session timeout caused login failure (Issue #342)"""
expired_state = json.loads(
(FIXTURES / "expired_session.json").read_text()
)
response = client.post("/api/auth/refresh", json=expired_state)
assert response.status_code == 200
assert "new_token" in response.json()
Claude Code 实战:
$ claude "I'm seeing a parsing error with webhook payload X.
Save this payload as tests/fixtures/bad_webhook.json,
write a test that fails with it, then fix the parser"
下次 Claude Code 遇到类似的解析问题,它会先检查 tests/fixtures/ 目录,看看有没有现成的测试用例。
动作 4:可执行的 Runbook——把排查步骤变成脚本
很多 Bug 的排查有固定的套路。把这套套路从「资深工程师脑子里的经验」变成「可执行脚本」,AI 就能直接调用。
#!/bin/bash
# scripts/diagnose_auth.sh - 认证问题诊断脚本
# 用法: ./scripts/diagnose_auth.sh <user_id>
USER_ID=$1
echo "=== Step 1: Check token status ==="
redis-cli get "session:${USER_ID}:token" | jq .
echo "=== Step 2: Check recent auth logs ==="
kubectl logs -l app=auth-service --since=1h | grep "${USER_ID}" | tail -20
echo "=== Step 3: Check rate limiting ==="
redis-cli get "ratelimit:${USER_ID}:auth"
echo "=== Step 4: Validate config ==="
kubectl get configmap auth-config -o yaml | grep -A5 "session_ttl"
在 CLAUDE.md 里引用这些脚本:
# Debugging
- Auth issues: run `./scripts/diagnose_auth.sh <user_id>` first
- Performance issues: run `./scripts/profile_endpoint.sh <path>`
- Always run diagnostic scripts BEFORE making code changes
AI 在修 Bug 之前会先跑这些脚本,收集上下文,然后基于实际数据做判断——而不是猜。
动作 5:CLAUDE.md 的 3 层上下文架构
Harness Engineering 社区总结的最佳实践是 3 层架构:
~/projects/CLAUDE.md ← Global: 通用标准 (TDD, 安全, 命名)
~/projects/my-app/CLAUDE.md ← Project: 架构, 命令, 坑, 文档地图
.claude/rules/ ← Path-Scoped: 按文件路径自动加载
Path-Scoped Rules 的威力:
<!-- .claude/rules/auth.md -->
---
globs: ["src/auth/**", "src/middleware/session*"]
---
# Auth Module Rules
- Token validation MUST check expiry BEFORE signature
- Session refresh MUST invalidate old token atomically
- All auth failures MUST return structured error with AUTH_ prefix
- Rate limiting: 5 attempts per minute per user_id
- When in doubt, check tests/fixtures/expired_session.json
当 Claude Code 修改 src/auth/ 下的文件时,这些规则会自动加载。这意味着:
- AI 不需要被告知「要注意认证模块的特殊规则」
- 规则跟着代码走,不跟着对话走
- 每个新 session 都能继承这些规则
动作 6:Git Hooks 机械强制——永远不要用 prompt 做 linter 的事
Augment Code 的核心原则:
「Never send an LLM to do a linter’s job.」
实战 Git Hooks 配置:
#!/bin/sh
# .husky/pre-commit
# 1. Lint (自动修复)
npx lint-staged
# 2. Secret scan (防密钥泄露)
npx gitleaks protect --staged
# 3. File size check (≤300 行)
for file in $(git diff --cached --name-only --diff-filter=ACM); do
lines=$(wc -l < "$file" 2>/dev/null || echo 0)
if [ "$lines" -gt 300 ]; then
echo "❌ $file exceeds 300 lines ($lines). Split it."
exit 1
fi
done
# 4. Test colocation (src/ 下的文件必须有对应测试)
for file in $(git diff --cached --name-only --diff-filter=ACM | grep "^src/"); do
test_file=$(echo "$file" | sed 's/\.ts$/.test.ts/')
if [ ! -f "$test_file" ]; then
echo "❌ No test found for $file. Create $test_file"
exit 1
fi
done
为什么这是关键动作? AI 可能会写出巨型文件、忘记写测试、硬编码密钥。这些约束是 确定性的,不依赖 AI 是否「记得」规则。
动作 7:CI 输出语义化——AI 能读懂的失败报告
AI 修完 Bug 提交 PR,CI 跑失败了。AI 能不能自己看懂失败原因并修复,完全取决于 CI 的输出格式。
反面案例:
FAIL tests/test_auth.py
正面案例:
{
"status": "failed",
"suite": "auth",
"test": "test_session_timeout_recovery",
"error": "AssertionError: expected 200 but got 401",
"location": "tests/test_auth.py:42",
"context": {
"expected_status": 200,
"actual_status": 401,
"response_body": "{\"error_code\": \"AUTH_TOKEN_EXPIRED\"}"
},
"related_files": ["src/auth/session.py", "src/auth/token.py"]
}
在 CLAUDE.md 里告诉 AI 如何解读 CI:
# CI Pipeline
- Run: `npm run test:ci` (outputs structured JSON to .ci-results/)
- If CI fails, read .ci-results/failures.json first
- The `related_files` field points to likely root cause
- Fix the issue and re-run CI before committing
真实案例
Spotify Honk:验证循环驱动 1500+ PR
Spotify 的内部 AI Agent「Honk」(基于 Claude Code)已经合并了 1500+ 个 AI 生成的 PR。它的核心设计是验证循环:
Developer (Slack)
↓
Honk AI Agent (分析 Bug)
↓
生成修复代码 + PR
↓
Verification Loop (MCP Tools)
↓
CI 通过?→ 通知开发者 Review
CI 失败?→ Agent 自动读取错误,重试修复
Honk 的三个关键 Harness 设计:
- Agent 不知道验证逻辑的细节——它只知道「必须通过验证」,防止针对验证做表面文章
- CI 失败会触发自动重试——但限制重试次数,防止 doom loop
- 开发者只做最终 Review——不参与中间修复过程
Spotify 的工程师不是在修 Bug,而是在 构建和维护 Honk 的 Harness。
OpenAI 内部实验:3 人 100 万行
OpenAI 用 3 个工程师 + Codex Agent,在 5 个月内生成了一个 100 万行的生产级代码库,零手写代码。
关键数据:
- ~1500 个 PR
- 每人每天 3.5 个 PR
- 88 个
AGENTS.md文件管理上下文
核心发现: 人工维护的 AGENTS.md 带来约 4% 的基准提升,而 LLM 自动生成的 AGENTS.md 反而降低性能。
Harness 必须是工程师精心设计的,不能交给 AI 自己写。
成熟度阶梯
把你的项目从「AI 无法修 Bug」升级到「AI 能自主修一类 Bug」,需要走过 5 级:
Level 5 ┃ 自主修复 ┃ AI 能自动修一类 Bug,人类只做 Review
━━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Level 4 ┃ 自动验证 ┃ CI 结构化输出,AI 能读懂失败并自修复
━━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Level 3 ┃ 机械强制 ┃ Git Hooks + Lint 阻止常见问题
━━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Level 2 ┃ 基础约束 ┃ CLAUDE.md + 测试覆盖 + Fixture
━━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Level 1 ┃ 裸奔 ┃ 无文档,无测试,Bug 靠人盯
大多数团队停在 Level 2。从 Level 2 到 Level 4 的跨越,就是本文讲的 7 个关键动作。
实操 Checklist
下次你修一个 Bug 时,对照这张表:
| # | 动作 | 产出物 | AI 赋能效果 |
|---|---|---|---|
| 1 | 写回归测试 | test_xxx.py | AI 有明确的 pass/fail 标准 |
| 2 | 结构化错误 | {error_code, context, action} | AI 能精确定位而非猜测 |
| 3 | Fixture 文件 | tests/fixtures/xxx.json | AI 一键复现 Bug 条件 |
| 4 | 诊断脚本 | scripts/diagnose_xxx.sh | AI 先收集数据再修代码 |
| 5 | Path-Scoped Rules | .claude/rules/xxx.md | AI 自动加载模块约束 |
| 6 | Git Hooks | pre-commit + pre-push | 阻止 AI 犯常见错误 |
| 7 | CI 语义化 | .ci-results/failures.json | AI 能读懂失败并自主重试 |
总结
Harness Engineering 的核心思想:
工程师的角色从「写代码修 Bug」变成「设计 Harness」——设计环境、明确意图、构建反馈循环,让 Agent 能自主地构建和维护软件。
每一次修 Bug,都是一次 Harness 升级的机会。浪费这个机会,就是浪费 AI 时代工程师最稀缺的资源——自己的时间。
参考:Anthropic Claude Code Best Practices、Augment Harness Engineering Guide、Spotify Honk Part 3、Harness Engineering Field Guide