「准备写一个 blog,详细讲解这个 skill。」
我对 Agent 说完这句话后,它在 0.5 秒内完成了三件事:加载 900 行 SKILL.md、扫描过去 127 篇博客的标题做交叉引用、按 Planner 模块输出了文章分类和大纲。没有追问「你想写什么角度」,没有问「用什么语气」,没有忘记中文排版要加空格。
这不是一个好的 prompt 能做到的事。这是一个 编译好的运行时。
在 一个会自己写博客的系统 里,我从宏观角度讲了这个系统的效果——月产量从 2 篇到 25 篇。但很多人追问:那个 SKILL.md 到底长什么样?里面写了什么?为什么一个 Markdown 文件能让 AI 的输出质量如此稳定?
这篇文章拆开来看。
一、Prompt 是请求,Skill 是规范
大多数人和 AI 的交互方式是 请求式 的:
「帮我写一篇关于 AI Agent 的博客,要有案例,要有代码。」
请求的问题在于:每次都要重新描述上下文。你上一次纠正过的排版错误,这次 AI 会再犯。你强调过的「不要自动发布」,下次它可能忘了。你在上一个对话里花 20 分钟磨合出来的风格偏好,新对话里要从零开始。
Skill 是另一种范式——声明式规范。你不是在请求 AI 做某件事,而是在告诉 AI: 在这个上下文里工作。
┌─────────────────────────────────────────────────────┐
│ Prompt 范式 │
│ │
│ 用户 ──►「请写一篇博客,注意…」──► AI 生成 │
│ │
│ 每次重新描述上下文,质量取决于 prompt 写得多好 │
│ 错误会重复犯,风格靠运气 │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ Skill 范式 │
│ │
│ 用户 ──► 一句话方向 ──► Agent 加载 Skill │
│ │ │
│ ┌─────────▼─────────┐ │
│ │ SKILL.md │ │
│ │ ┌─────────────┐ │ │
│ │ │ 流水线定义 │ │ │
│ │ │ 风格约束 │ │ │
│ │ │ 硬性禁止 │ │ │
│ │ │ 排版规则 │ │ │
│ │ │ 历史教训 │ │ │
│ │ │ 评估标准 │ │ │
│ │ └─────────────┘ │ │
│ └─────────┬─────────┘ │
│ ▼ │
│ Agent 在规范内工作 │
│ 输出确定、可复现、可审计 │
└─────────────────────────────────────────────────────┘
如果你在 API、MCP 和 Skills:三个概念的本质区别 里理解了 Skill 的定位,这里就是它最具体的实现:Skill 不是工具调用,不是上下文注入,而是 把工程标准编译成 Agent 可执行的运行时规范。
类比一下:Prompt 像是给实习生发微信说「帮我写篇文章」,Skill 像是给新员工一本 500 页的操作手册——包含流程、规范、禁止事项、历史事故报告。前者依赖接收者的理解力,后者依赖规范本身的完整性。
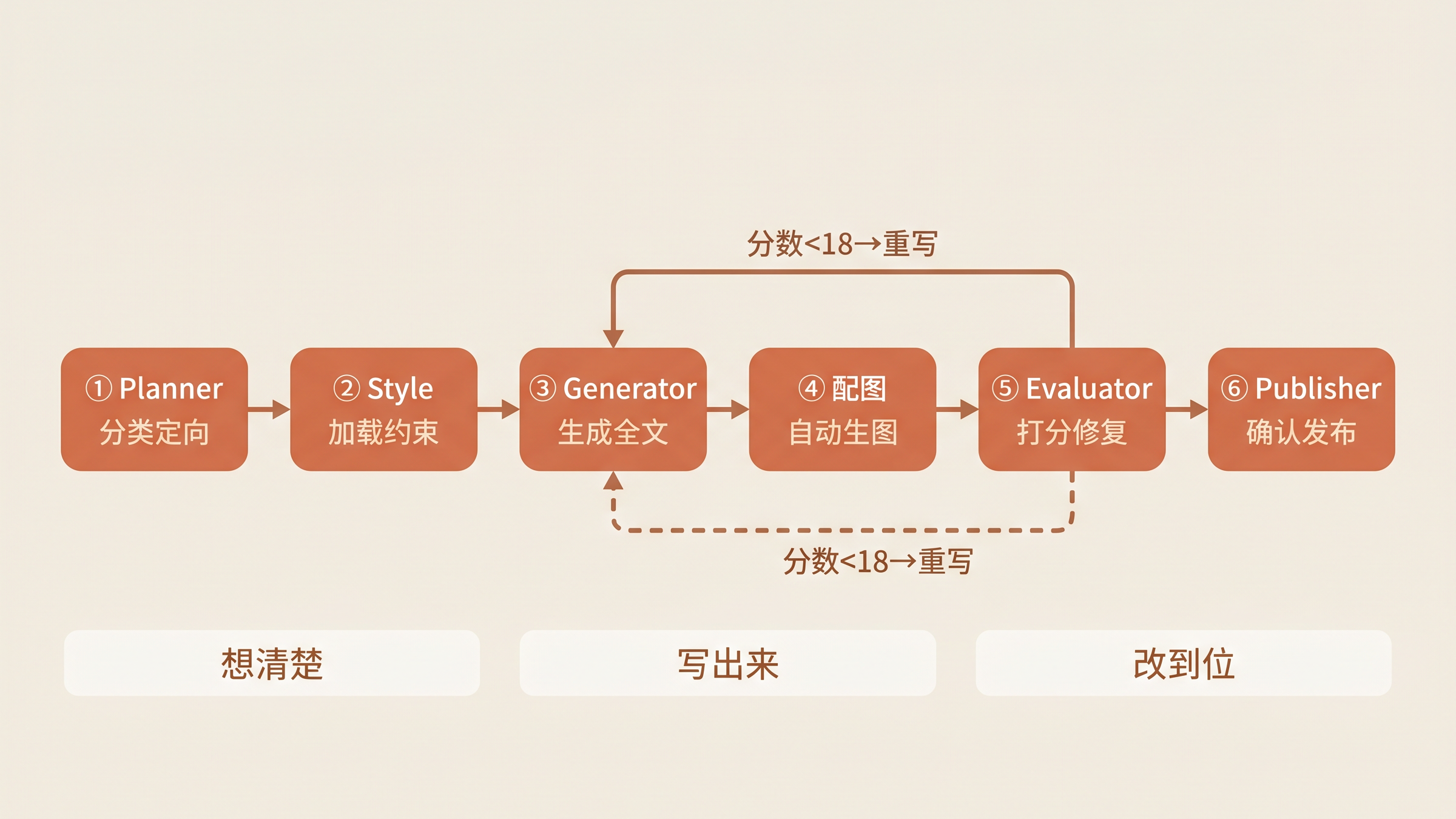
二、六阶段流水线:从「想清楚」到「发出去」
SKILL.md 的核心骨架是一个 强制顺序执行的六阶段流水线:
[1] Planner ──► [2] Style ──► [3] Generator ──► [4] Illustration ──► [5] Evaluator ──► [6] Publisher
分类定向 加载约束 生成全文 自动配图 打分修复 人机确认发布
注意「强制顺序」四个字。这不是建议,是约束。Agent 不能跳过 Evaluator 直接发布,不能在没有 Illustration 的情况下交稿。流水线的设计哲学来自制造业——质量不是检验出来的,是过程控制出来的。
2.1 Planner:不是选题,是分类
Planner 阶段的输出不是一个「选题方向」,而是一个严格格式的分类结果:
@dataclass
class PlanResult:
type: str # opinion | technical | hybrid
angle: str # 一句话核心观点
audience_level: str # beginner | intermediate | advanced
must_have: list # 必须包含的元素清单
# generated by hugo AI
为什么分类这么重要?因为不同类型文章走不同的结构模板:
| 类型 | 结构 | 核心要求 |
|---|---|---|
| opinion | Hook → 论点 → 反直觉框架 → 升维问题 | 必须有命名的框架 |
| technical | 问题 → 方案对比 → 实现 → 坑 & 限制 | 代码必须能跑 |
| hybrid | 故事 → 框架 → 技术实现 → 升维总结 | 两者都要 |
没有分类就开始写,就像没有 if/else 就开始写代码——所有逻辑混在一起,最后变成一锅粥。
2.2 Style Compiler:FORBIDDEN 比 DO 更重要
Style Compiler 阶段加载的不是「你应该怎么做」,而是 「你绝对不能怎么做」。
这是我反复迭代后得到的最重要的设计洞察: 对 AI 来说,负向约束的效力远大于正向指导。
告诉 AI「开头要引人入胜」,它可能写一段「随着 AI 的发展…」这种正确但无聊的开头。告诉 AI「 **禁止 **以抽象背景开头, **必须 **有真实人物+具体场景+冲突」,它就没法偷懒了。
Skill 里的 FORBIDDEN 清单是整份文档最有价值的部分:
FORBIDDEN 清单(节选):
开头:
❌ 「随着 AI 的发展...」
❌ 抽象背景开头
❌ 泛泛而谈,缺少具体细节
框架:
❌ 「总结几点」
❌ 散点罗列,没有结构
❌ unstructured ideas
案例:
❌ 「假设有一个电商场景」
❌ 「假设有一家公司」
❌ 不同章节用不同的抽象例子
排版:
❌ 中文**粗体**中文(缺外空格)
❌ ** 内容 **(多余内空格)
❌ 使用""而非「」
每一条 FORBIDDEN 背后都有一个真实的翻车故事。比如「假设有一个电商场景」这条——早期 AI 生成的博客,案例全是虚构的电商公司、虚构的用户数据、虚构的转化率。读起来像 MBA 教材,不像一个工程师在分享实战经验。加上这条 FORBIDDEN 后,AI 再也没写过空洞案例。
2.3 Generator:单案例贯穿模式
Generator 阶段最核心的设计是 Single-Case-Thread-Through(单案例贯穿) 原则。
这是从 修 Bug 的真正目的:让 AI 下次能自己修 的 Harness 理念中提炼出来的——AI 写长文时,最常见的失败模式是 每个章节换一个新例子,导致文章读起来像一堆独立段落的拼盘,没有叙事动力。
Skill 里的约束是这样的:
❌ BAD: 每个章节用不同的抽象例子
- 信号采集: 泛泛的「用户点了不喜欢」
- 智能归因: 虚构的周报数据分析
- 方案生成: 毫不相关的定价错误案例
✅ GOOD: 一个真实案例贯穿所有章节
- 信号采集: 这个用户的 PermissionError 堆栈
- 智能归因: AI 聚类发现 Windows 11 + OneDrive 集中
- 知识关联: 系统找到了 3 月份 macOS iCloud 修复经验
- 方案生成: 把沙箱迁移到 %LOCALAPPDATA%
- 代码修复: Agent 在 Harness 约束下改了 3 个文件
- 验证发布: 从 VOC 到发版 4 小时
一个案例创造叙事动力,证明系统端到端能跑通。 散落的例子读起来像理论,一个案例读起来像战争故事。
2.4 Illustration:自动化配图流水线
每篇博客必须有题图,这不是美学要求,是系统设计的一部分。
配图流水线完全自动化:
读完全文 ──► 提取核心主题 ──► 用中文写 Gemini Prompt
│
▼
image_generate(landscape, 1280x896)
│
▼
Gemini 返回 2048×2048 正方形
│
▼
Pillow center-crop → 16:9
│
▼
生成 JPG 缩略图(800px, q=85)
│
▼
插入 <!--more--> 之前
│
▼
上传 litterbox → 24h 分享链接
这里有一个经典的 pitfall:Gemini API 永远返回 2048×2048 正方形,不管你请求什么尺寸。所以 Pillow 后处理不是可选的,是必须的。这条被写进了 Skill 的 Pitfalls 清单,并且加了粗体和 CRITICAL 标记——因为 Agent 曾经直接把正方形图插进文章,我不得不手动修。
2.5 Evaluator:四维打分 + 自动修复
Evaluator 是我个人最喜欢的模块。它让 AI 在交稿之前 自己审自己。
四个维度,各 0-5 分:
| 维度 | 5 分标准 | 低于 3 分的自动修复 |
|---|---|---|
| hook | 具体人物+场景+冲突,读者立刻代入 | 补充更多具体场景细节 |
| insight | 反直觉观点清晰,读者会想反驳或认同 | 加强逆向思维 |
| framework | 有命名、可复用、结构完整、有图示 | 重建为结构化模型 |
| technical | 代码可运行、有 WHY 解释、有坑说明 | 补充代码注释和限制说明 |
决策规则:
≥ 18 分 → 可发布
14-17 分 → 需修改
< 13 分 → 拒绝重写
这个设计的本质是 把质量门禁从人的主观判断变成可计算的指标。不是说 AI 的自评一定准,而是说它至少会在交稿前过一遍这四个维度——比「生成完直接交」好得多。
2.6 Publisher:人机协作的最后一步
Publisher 阶段有一条铁律: 永远不自动发布。
Agent 做完所有工作——生成、配图、排版修复、评分——然后停下来,把草稿展示给我,等我说「发布」才执行 git push。
这是刻意设计的。AI 可以完成 95% 的工作,但最后 5% 的「这个东西代表我公开发表了」的判断,必须由人来做。就像自动驾驶可以处理 95% 的路况,但方向盘不能完全离开驾驶员的手。
三、五种入口模式
流水线是固定的,但入口有五种。这解决了不同场景下的启动成本问题:
| 模式 | 输入 | 适用场景 | 人的工作量 |
|---|---|---|---|
| A. One-shot | 一个主题 | 想法明确、一步到位 | 给主题 → 审一眼 |
| B. Iterative | 逐节讨论 | 复杂话题需要分段打磨 | 每节审一次 |
| C. Conversation-as-Draft | 对话中说「发布」 | 聊着聊着聊出好文 | 零额外(对话即研究) |
| D. Outline Expansion | 完整大纲 | 已有结构,需要扩写 | 写大纲 → 审一眼 |
| E. Research-Driven | 主题 + 角度 | 需要先做 web research | 确认大纲 → 审一眼 |
手冲咖啡.SKILL 就是一个 Mode D 的产物——我给了一个完整的冲煮参数大纲,Agent 在我的骨架上扩写出了全文。而这篇文章走的是 Mode E——先确认大纲方向,再由 Agent 展开。
不同模式解决同一个问题: 降低启动摩擦力。以前写一篇博客,你需要「有一个完整的想法 + 有整块时间 + 坐在电脑前」。现在,你只需要一个方向(Mode A/E)、一段对话(Mode C)、或者一个大纲(Mode D)。
四、Pitfalls 是运行时异常日志
Skill 里有一个专门的部分叫 Pitfalls——Agent 犯过的错误清单。这不是文档,是 异常日志。
Pitfalls(节选):
- 永远不自动发布——必须等人确认才 git push
- SSH key 必须用 id_ed25519——不是 wiki_rsa,不是 id_rsa
- 案例必须真实——不接受「假设有一个电商场景」
- Post ID 必须连续——创建文件前先查编号
- 插图必须 16:9 横版——Gemini 永远返回正方形,必须裁切
- 不要在括号和引号内加空格——(Context)不是( Context )
每一条背后都是一个真实的翻车故事:
- 「SSH key」这条:Agent 曾经用了错误的 key,
git push失败,文章写好了但发不出去。 - 「正方形插图」这条:Gemini 不管你怎么请求都返回 2048×2048,Agent 曾经直接把正方形图插进文章,我在手机上看到差点血压升高。
- 「自动发布」这条:早期版本没有这个约束,Agent 生成完直接 push 了,我来不及审就上线了。
这些 pitfall 的价值在于: Agent 每次加载 Skill 都会读到它们,所以同样的错误不会犯第二次。 人的记忆会衰减,Agent 加载 Skill 是全量加载,不会忘记、不会「这次先这样」。
在 让 AI 自己写 Skill:可进化 Agent 的设计原理与最佳实践 里我详细讨论过这个理念:Skill 的 Pitfalls 区域本质上是 人类经验的持久化存储。你在实际使用中发现的问题,修一条加一条,Skill 就越来越健壮。
五、Style Compiler 的中文排版:最细的约束,最大的收益
SKILL.md 里有大约 100 行专门定义中文 Markdown 排版规则。看起来琐碎,但这是 读者能直接感知到的质量差异。
核心规则四条:
1. 中英文之间加空格
✅ AI 时代 ❌ AI时代
✅ 收藏 500 篇 ❌ 收藏500篇
2. 粗体外侧加空格,内侧不加
✅ 中文 **内容** 中文 ❌ 中文** 内容 **中文
3. 用「」不用 ""
✅ 「记笔记的方式变了」 ❌ "记笔记的方式变了"
4. 括号内不加空格
✅ 上下文(Context) ❌ 上下文( Context )
这些规则在两个层面执行:
- 生成时遵守——Skill 里写了完整的排版规范,Agent 在写文章时就遵守
- 生成后兜底——跑一遍
fix-chinese-markdown.py,用正则自动修复漏网的排版问题
双重保障。这也是为什么我 127 篇博客没有一篇有排版问题——不是因为我逐篇检查了,而是因为流水线不允许排版问题通过。
六、Skill 的自我进化
SKILL.md 不是一次写完的。它有版本号(当前 v3.1.0),有 Evolution 日志,记录每次迭代的原因和内容。
进化的触发条件很简单: Agent 犯了 Skill 没覆盖的错误 → 加一条 Pitfall 或 FORBIDDEN。
比如:
- v1.0 → v2.0:发现 AI 写的案例太假 → 加入 Single-Case-Thread-Through 原则
- v2.0 → v2.5:发现配图总是正方形 → 加入 Gemini 裁切流程
- v2.5 → v3.0:发现不同场景需要不同入口 → 加入五种模式
- v3.0 → v3.1:发现 Gemini 尺寸 1536x1024 不够好 → 更新为 1280x896
这个机制让 Skill 越用越好。在 AI 时代的个人生产力公式 里我提过一个观点:AI 时代的个人竞争力不是「会用 AI」,而是「能让 AI 越用越好」。Skill 的进化机制就是这个观点的具体实现。
七、不是写作工具,是内容流水线
写到这里,回到开头的核心问题:为什么一个 Markdown 文件能让 AI 输出质量如此稳定?
答案是: SKILL.md 不是写给 AI 看的文档,是编译给 Agent 执行的规范。
它把「写博客」这个模糊的创作活动,拆解成了六个有明确输入输出的工程阶段。每个阶段有约束、有检查点、有兜底机制。AI 不是在「自由创作」,而是在一个 精心设计的约束空间 里工作。
普通 Prompt:
输入 → [AI 黑盒] → 输出(质量不可预测)
Skill Pipeline:
输入 → [Planner] → [Style] → [Generator] → [Illustration] → [Evaluator] → [Publisher] → 输出
分类定向 加载约束 生成全文 自动配图 打分修复 人机确认
(确定性流水线,每一步可审计)
这就是 Context Engineering 的本质——不是给 AI 更好的 prompt,而是给 AI 一个 完整的操作上下文。当上下文足够完整时,AI 的输出就从概率分布变成了确定性流水线。
你给 AI 的是一个 prompt,还是一个编译好的运行时?欢迎留言讨论。