上周我打开了尘封已久的 Obsidian vault。
50 多个插件,300 多个标签,12 个 database view,还有一套精心设计的 MOC(Map of Content)索引系统。我花了不知道多少小时在「组织」知识,而不是「使用」知识。
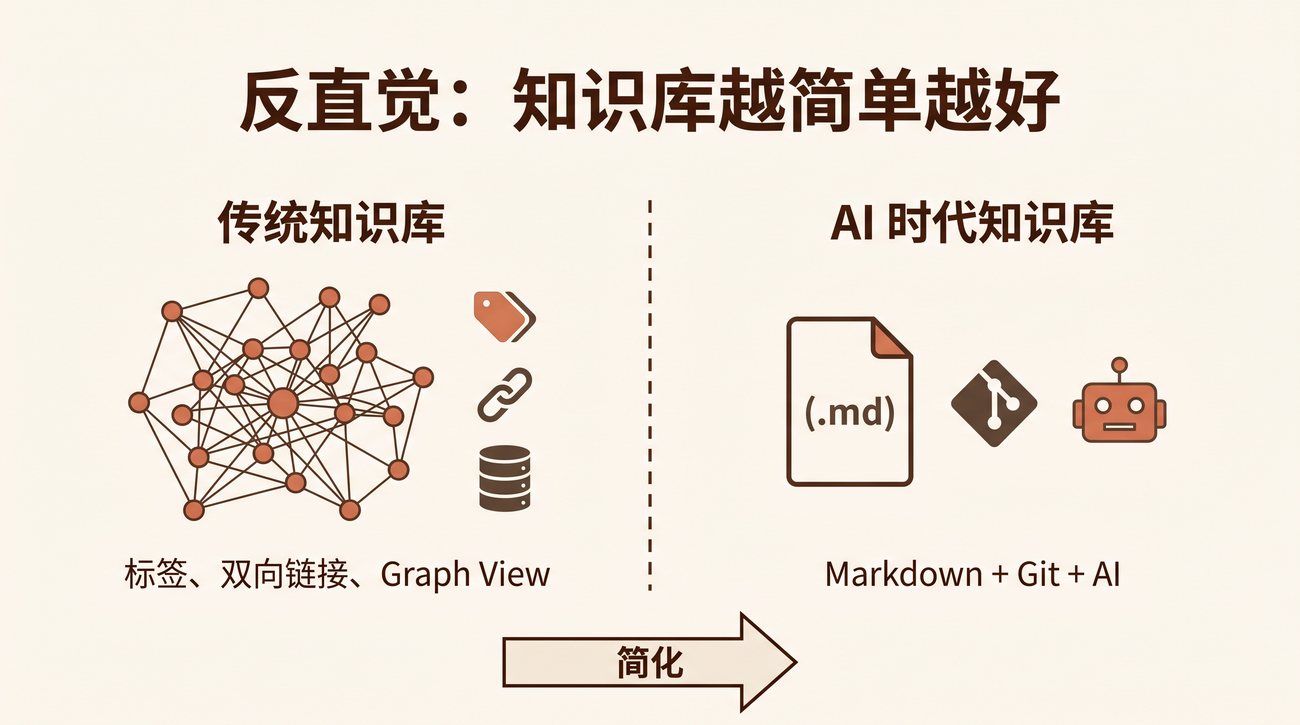
然后我意识到: 这套系统在 AI 时代已经过时了。
知识库复杂度悖论
过去 20 年,个人知识管理(PKM)工具的核心功能是帮人「找到信息」:
- 标签系统:给内容打分类标签
- 双向链接:建立知识之间的关联
- 全文搜索:快速定位内容
- Graph view:可视化知识网络
这些功能解决的是 人类认知的局限——我们记不住东西放在哪,所以需要结构。
但现在,AI 可以替你「找」。
你问它:「我之前写过什么关于 X 的?」它能读你所有的文件,给你一个答案。你不需要标签,不需要链接,不需要任何人工组织的结构。
悖论在于:你花越多精力「组织」知识,AI 读取时遇到的噪音就越多。
一个精心组织的 Obsidian vault,对 AI 来说是这样的:
---
tags: [ai, agent, workflow]
aliases: [智能体工作流]
related: [[agent-design-patterns]]
created: 2025-05-01
---
# AI Agent Workflow Design
> [!note] Key Insight
> 核心在于[[上下文管理]]和[[任务分解]]...
## See Also
- [[related-concept-1]]
- [[related-concept-2]]
AI 要理解这个文件,需要:
- 解析 YAML frontmatter(有用吗?也许)
- 解析 callout 语法(
> [!note],这是 Obsidian 特有的) - 解析
[[wiki-link]](这是双向链接语法,不是标准 Markdown) - 理解
[[related-concept-1]]指向哪个文件(需要额外的索引)
一个纯文本的 Markdown 文件,对 AI 来说是这样的:
# AI Agent Workflow Design
核心在于上下文管理和任务分解。
上下文管理决定了 Agent 能否记住之前的对话和决策。
任务分解决定了 Agent 能否处理复杂的多步骤任务。
AI 读得懂。 不需要任何元数据,不需要任何特殊语法。
「极简知识架构」框架
我总结了一个原则,叫 极简知识架构 (Minimal Knowledge Architecture):
知识库的价值不在于你组织得多好,而在于 AI 能读取多少。
这个框架有三个层次:
1. 格式层:纯 Markdown
不用任何工具特有的语法。不用 [[wiki-link]],不用 > [!note],不用 database view。
为什么?因为 Markdown 是 AI 的原生食物。
| 格式 | AI 可读性 | 工具锁定 | 迁移成本 |
|---|---|---|---|
| 纯 Markdown | ✅ 完美 | ❌ 无 | 零 |
| Obsidian (wiki-link) | ⚠️ 需解析 | ✅ 有 | 中 |
| Notion | ❌ 需 API | ✅ 强 | 高 |
| Heptabase | ⚠️ 有损导出 | ✅ 有 | 高 |
| 语雀 | ❌ 需爬取 | ✅ 强 | 极高 |
2. 组织层:文件夹,够了
不需要标签,不需要双向链接,不需要 MOC。
文件夹是最简单的组织方式,AI 能跨目录检索。
~/wiki/
├── ai/
│ ├── agent-design.md
│ └── prompt-engineering.md
├── devops/
│ ├── kubernetes.md
│ └── monitoring.md
└── inbox/
└── random-thought.md
我把笔记随便放在文件夹里,不需要精心分类。当我需要找某篇笔记时,直接问 Hermes:
「我之前写过什么关于 Kubernetes 监控的内容?」
它会 read_file 所有相关文件,给我答案。
标签是给人用的,AI 不需要。
3. 版本层:Git
用 Git 做版本控制。不需要云同步,不需要付费订阅。
cd ~/wiki
git add .
git commit -m "update notes"
git push # 可选,备份到 GitHub
Git 给你:
- 完整的版本历史(免费)
- 跨设备同步(免费)
- 协作能力(免费)
- 隐私(数据在本地)
Obsidian Sync 一年 $96,Notion Plus 一年 $96。Git 免费。
四层架构
我把这个思路抽象成一个四层架构:
┌─────────────────────────────────────┐
│ 展示层(可选) │
│ Hugo / Obsidian Publish / 不需要就不建 │
├─────────────────────────────────────┤
│ 智能层 │
│ Hermes / Claude / 任何能读文件的 AI │
├─────────────────────────────────────┤
│ 存储层 │
│ 文件系统 + Git │
├─────────────────────────────────────┤
│ 输入层 │
│ 任何能写文本的工具 │
└─────────────────────────────────────┘
每一层都可以替换:
- 输入层:VS Code、Obsidian、
nano、手机备忘录——无所谓,只要能导出纯文本 - 存储层:文件系统 + Git——这是核心,不能换
- 智能层:Hermes、Claude、ChatGPT——AI 模型会迭代,但文件格式不变
- 展示层:Hugo 发布到网站——可选,不需要就不建
关键是:存储层是纯文本 + Git,这是最持久、最灵活、最便宜的方案。
我的实际使用
我现在的知识库就是这样:
~/wiki/
├── concepts/ # 概念
├── people/ # 人物
├── projects/ # 项目
├── inbox/ # 随手记,未整理
└── .git/ # 版本控制
每个文件就是一个 .md,开头几个 YAML 字段(标题、日期、标签),正文随便写。
我用 Hermes 作为 AI 层。当我需要找某篇笔记时,直接问它:
「我之前写过什么关于 Agent 设计模式的内容?」
它会:
search_files搜索所有笔记read_file读取相关文件- 给我一个总结,附带文件路径
我不需要打开 Obsidian,不需要翻标签,不需要看 graph view。
AI 是我的搜索引擎,Markdown 是我的数据库,Git 是我的备份系统。
升维:知识库的目的是什么?
回到根本问题: 知识库的目的是什么?
传统答案是:「帮助我组织和检索信息。」
但在 AI 时代,答案变了: 知识库的目的是让 AI 能理解和检索我的信息。
这意味着:
- 格式要对 AI 友好(纯文本)
- 组织要简单(AI 能跨目录检索)
- 版本要可控(Git)
- 不要被工具锁定(开放格式)
最好的知识库工具,是你几乎感觉不到它存在的工具。
你不需要学一套复杂的系统,不需要维护标签和链接,不需要担心数据迁移。你只需要写,用任何能写文本的工具。
Obsidian、Notion、Heptabase 都是好产品。但在 AI 时代,它们解决的是 上一代的问题。
下一代的问题是:怎么让 AI 更好地理解你的知识?
答案是:越简单越好。
你在用什么知识库工具?有没有想过「简化」一下?欢迎留言讨论。