上周五,我让 AI 帮我分析一场 90 分钟产品周会的听记转写稿——15000 字的会议记录,要求提取关键决策、未闭环的行动项、以及和过去三个月决策之间的矛盾。
第一次,我直接把转写稿喂给 AI,说「帮我整理会议纪要」。得到一份「看起来还行」的摘要:谁说了什么、讨论了什么话题。但这不是我需要的——我需要的是 洞察。
比如:技术负责人在讨论方案 A 时说「我觉得可以上」,但架构师追问了三个问题后,他改口说「那还是再看看」。AI 的摘要写的是「张总介绍了技术方案」—— 关键决策点被淹没了。
再比如:三个月前的另一次会议里,团队已经否决了方案 B,原因是「运维成本太高」。但这次会议里,有人在不知情的情況下重新提出了方案 B,而且获得了初步认可。AI 不会发现这个矛盾——因为它只看到了这一次会议。
问题不在 AI 的能力,而在我的知识库。
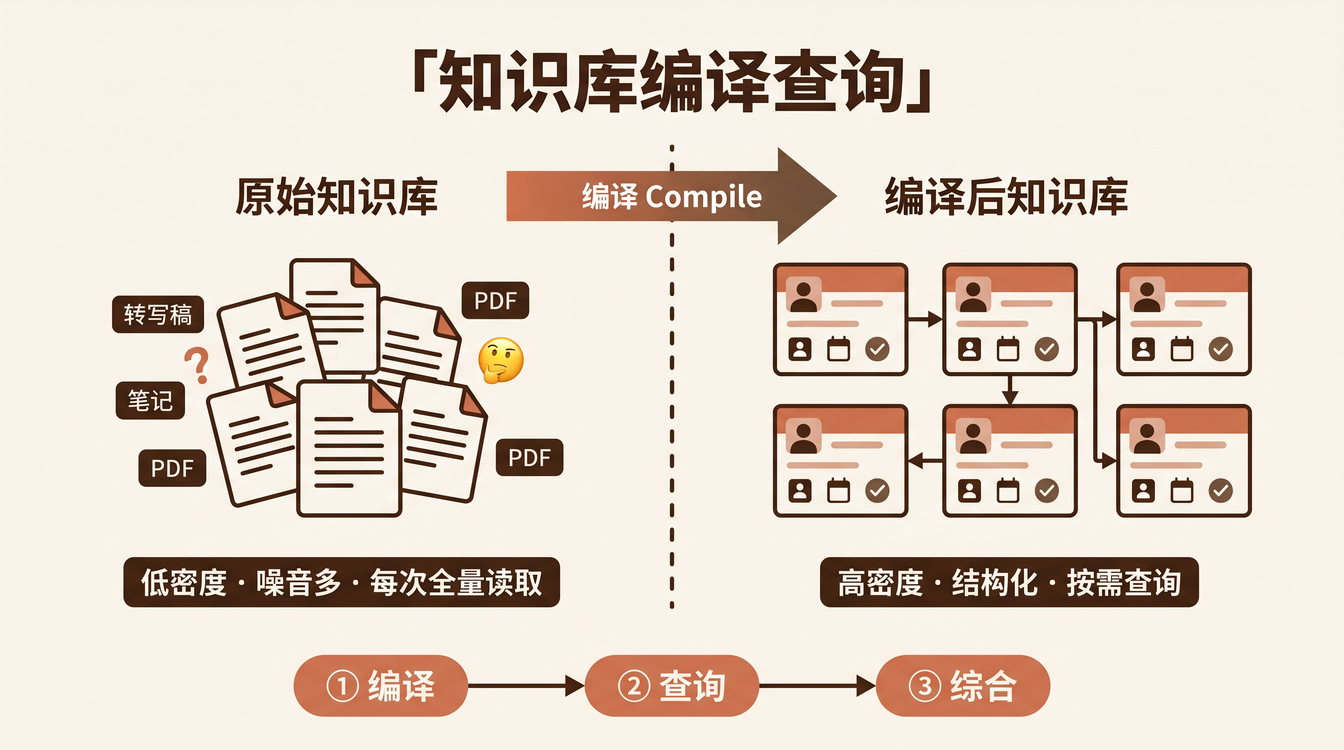
核心问题:你的知识库是「文档」还是「数据」?
大多数人的知识库是一堆文档。Markdown 文件、PDF、笔记、会议转写稿——它们被存在文件夹里,需要的时候扔给 AI 说「帮我总结」。
这就像把一堆 C++ 源码文件直接丢给 CPU 说「运行」。CPU 看不懂源码,它需要编译器把源码变成机器码。
知识库也一样。原始文档是「源码」,AI 需要的是「编译后的可执行格式」。
我在 继编程之后,大模型应用的下一个爆发场景是知识管理 中提出过一个概念——大模型是「知识编译器」,把非结构化的人类思维编译成结构化的、可推理的知识表示。但那篇文章讲的是 为什么 需要编译。这篇讲的是 怎么 编译,以及编译之后 怎么 查询。
编译-查询分离模型(CQ Separation)
我把知识库的使用方法分成两个独立环节:
- 编译 (Compile):把原始信息转换成「可分析的知识单元」
- 查询 (Query):根据特定任务,从知识单元中检索并综合
这两个环节 不应该混在一起。
大部分人使用 AI 处理知识的方式是:把原始文档 + 任务指令一起扔给 AI,期待它一步到位。这相当于让 AI 同时做编译和查询——而这两件事的认知模式完全不同。
| 维度 | 原始知识库 | 编译后知识库 |
|---|---|---|
| 信息密度 | 低(大量噪音和填充词) | 高(只保留结构化要素) |
| 事实/判断混合 | 混在一起,难以区分 | 分离,可独立查询 |
| 时间关系 | 隐含在文件日期里 | 显式标注,可排序 |
| 跨文档关联 | AI 需要自己发现 | 编译时已标注 |
| 查询效率 | 每次全量阅读 | 按需检索相关单元 |
编译的三种模式
模式一:实体抽取(Entity Extraction)
从原始内容中提取 谁、什么、何时、何因,以结构化格式存储。
一场会议的转写稿里,这段话:
张总说:「我觉得方案 A 在技术上是可行的,上周我们做了 PoC,性能数据还不错,P99 延迟降了 40%。」
编译后:
- entity: 张总
type: person
fact: 认为方案 A 技术可行
evidence: PoC 验证,P99 延迟降低 40%
time: 2026-05-23
context: 产品周会,技术方案评审环节
# generated by hugo AI
区别是什么?原始文本是一整段话,AI 需要「读懂」才能提取信息。编译后是一个 自包含的知识单元——不需要读原文就能理解。
模式二:时间线编译(Timeline Compilation)
把同一话题在不同时间点的讨论串联起来,形成 演进轨迹。
topic: 方案 A 的评估
timeline:
- date: 2026-04-10
event: 首次提出,进入技术评估
source: 产品周会
- date: 2026-05-02
event: 架构组否决,原因是运维成本高
source: 架构评审会
- date: 2026-05-23
event: 重新提出,新方案采用云原生架构降低成本
source: 产品周会
- date: 2026-05-23
status: pending
decision: 待架构组二次评审
# generated by hugo AI
没有这层编译,AI 看到的只是三个孤立的会议记录。有了时间线,AI 能看到 决策的演变过程——以及这次重新提出是不是在重复之前的讨论。
模式三:判断编译(Judgment Extraction)
把 客观事实 和 主观判断 分开存储。
facts:
- P99 延迟降低 40%
- PoC 在预发环境运行
- 样本量 1000 请求
judgments:
- who: 张总
judgment: 技术上可行
confidence: medium
basis: PoC 数据
decisions:
- what: 进入架构评审
status: pending
owner: 架构组
deadline: 2026-05-30
# generated by hugo AI
为什么分离很重要?因为查询的时候你可能只想看事实(「方案 A 的性能数据是什么?」),也可能想看判断(「谁认为方案 A 可行?」),也可能想看决策(「关于方案 A 做了什么决定?」)。混在一起,AI 需要自己区分;分开了,查询就变得精准。
三种编译模式组合使用,就把一场非结构化的会议变成了一个可查询的结构化数据库。
查询的四种模式
编译解决的是「知识怎么存」,查询解决的是「知识怎么用」。不同的分析任务需要不同的查询模式:
一、召回查询(Recall)
「把所有关于方案 A 的讨论找出来。」
最简单的查询。从编译后的知识库中召回某个实体或话题的所有记录。适合做背景调查——开会前快速了解某话题的历史。
二、对比查询(Compare)
「方案 A 和方案 B 在性能、成本、风险上有什么不同?」
取两个实体或两个时间段的编译结果,让 AI 做结构化对比。比直接问 AI「对比 A 和 B」好得多——因为对比的素材是编译过的结构化数据,不是两篇需要全文理解的原始文档。
三、溯源查询(Trace)
「这个决策是怎么做出来的?谁参与了?有什么反对意见?」
沿着时间线追踪一个决策的完整生命周期:提出、讨论、修改、决定、执行、复盘。这是我在实际工作中用得最多的查询模式——因为大部分「为什么这么做」的问题,答案都藏在过去的会议里。
四、洞察查询(Insight)
「过去三个月,有哪些技术决策在两周后被推翻了?共同原因是什么?」
这是最高级的查询模式。需要跨多个编译结果做综合,发现 非显而易见的模式。AI 擅长这个——但前提是知识已经被编译成结构化的单元。如果还是原始文档,AI 需要先理解每篇文档,再做综合——上下文太长,注意力被稀释,洞察质量直线下降。
实战:会议纪要的编译查询流水线
回到开头的场景。传统的会议纪要生成方式是这样的:
[会议转写稿 15000 字] ──→ [AI: 生成会议纪要] ──→ 平庸的摘要
问题:AI 在一次调用中既要「理解」原始转写稿,又要「综合」出有洞察的纪要。两件事都做不好。
编译-查询方式 是三个阶段:
┌─────────────────────────────────────────────────────────────┐
│ Stage 1: 编译 │
│ [会议转写稿] ──→ [实体/决策/行动项/分歧/开放问题] ──→ JSON │
├─────────────────────────────────────────────────────────────┤
│ Stage 2: 查询 │
│ [编译结果 + 知识库] ──→ [召回相关历史 + 溯源矛盾] ──→ 上下文 │
├─────────────────────────────────────────────────────────────┤
│ Stage 3: 综合 │
│ [编译结果 + 历史上下文] ──→ [AI: 生成带洞察的会议纪要] │
└─────────────────────────────────────────────────────────────┘
关键区别: 理解 和 综合 被分开了。
- 理解(Stage 1):把非结构化变成结构化
- 查询(Stage 2):找到相关的历史知识
- 综合(Stage 3):基于结构化数据 + 历史上下文,生成高质量输出
我在 如何 Benchmark 会议纪要 Agent 中提出过评估会议纪要质量的维度。编译-查询分离恰好能提升每一个维度:决策识别准确率、行动项完整度、历史关联覆盖度——因为每一层都专注做好一件事。
代码实现:一个最小可用的编译查询流水线
概念讲完了,来看怎么落地。以下是一个可以实际运行的 Python 实现:
from dataclasses import dataclass, field
from enum import Enum
from datetime import date
from typing import Optional
@dataclass
class KnowledgeUnit:
"""编译后的知识单元——知识库的最小存储单位。"""
id: str
source: str
compiled_at: str
entities: list[str] = field(default_factory=list)
facts: list[str] = field(default_factory=list)
judgments: list[dict] = field(default_factory=list)
decisions: list[dict] = field(default_factory=list)
action_items: list[dict] = field(default_factory=list)
timeline: list[dict] = field(default_factory=list)
topic: str = ""
raw_excerpt: str = ""
# generated by hugo AI
class QueryPattern(Enum):
"""四种查询模式,对应不同的分析任务。"""
RECALL = "recall" # 召回:找所有相关记录
COMPARE = "compare" # 对比:两个实体的差异
TRACE = "trace" # 溯源:决策的演变过程
INSIGHT = "insight" # 洞察:跨文档发现模式
# generated by hugo AI
COMPILE_PROMPT: str = """你是一个知识编译器。从以下内容中提取结构化知识单元。
## 提取规则
1. entities: 参与的人、项目、产品、技术方案
2. facts: 可验证的客观事实(带数据)
3. judgments: 主观判断(谁说的,信心程度)
4. decisions: 做出的决策(状态、负责人、截止时间)
5. action_items: 待办事项(负责人、截止时间)
6. timeline: 时间线事件
## 原则
- 事实与判断必须分离
- 每个单元必须自包含(不依赖原文也能理解)
- 保留关键数据(百分比、日期、人名)
## 输入
{raw_content}
输出 JSON 格式的知识单元。
"""
# generated by hugo AI
QUERY_TEMPLATES: dict[str, str] = {
"recall": (
"根据以下编译结果,回答:{query}\n\n"
"编译结果:\n{compiled_units}\n\n"
"要求:引用具体来源,标注时间。"
),
"compare": (
"对比以下两组编译结果,回答:{query}\n\n"
"A组:\n{units_a}\n\nB组:\n{units_b}\n\n"
"输出结构化对比表,标注数据来源和时间。"
),
"trace": (
"追踪以下决策的完整生命周期:{query}\n\n"
"时间线编译:\n{timeline_units}\n\n"
"按时间顺序输出:提出→讨论→修改→决定→执行→复盘。"
),
"insight": (
"综合以下多源编译结果,发现非显而易见的模式:{query}\n\n"
"编译结果:\n{compiled_units}\n\n"
"要求:模式必须有数据支撑,不是主观臆测。"
),
}
# generated by hugo AI
def filter_units(
units: list[KnowledgeUnit],
query: str,
time_range: Optional[tuple[date, date]] = None,
) -> list[KnowledgeUnit]:
"""按关键词和时间范围过滤知识单元。"""
results: list[KnowledgeUnit] = []
for unit in units:
if time_range:
unit_date = date.fromisoformat(unit.compiled_at[:10])
if not (time_range[0] <= unit_date <= time_range[1]):
continue
# 简单的关键词匹配,生产环境用向量检索
searchable = " ".join(
unit.entities + unit.facts + [unit.topic]
)
if query.lower() in searchable.lower():
results.append(unit)
return results
def build_query_prompt(
pattern: QueryPattern,
query: str,
units: list[KnowledgeUnit],
**kwargs: str,
) -> str:
"""根据查询模式构建 prompt。"""
import json
compiled_json = json.dumps(
[u.__dict__ for u in units],
ensure_ascii=False,
indent=2,
)
template = QUERY_TEMPLATES[pattern.value]
return template.format(
query=query,
compiled_units=compiled_json,
**kwargs,
)
# generated by hugo AI
这段代码展示的是 设计模式,不是完整系统。关键设计决策:
KnowledgeUnit是自包含的 ——每个单元脱离原文也能被理解COMPILE_PROMPT把事实和判断分离 ——这是编译质量的核心QUERY_TEMPLATES按任务类型定制 ——不同分析任务用不同 prompt,不是一个万能 prompt 打天下filter_units是预检索 ——在调用 AI 之前先缩小范围,减少上下文长度
三条设计原则
原则一:先编译,后查询
不要在一次 AI 调用中同时做理解和检索。编译是预处理,查询是使用。分开做,每一步的质量都可控。
这和软件工程里的「关注点分离」是同一个道理。你不会在一个函数里既做 IO 又做业务逻辑,也不应该让 AI 在一个 prompt 里既做理解又做综合。
原则二:编译产物要自包含
每个知识单元都应该 脱离原文也能理解。
「张总觉得可以」——脱离原文就不知道「什么」可以。 「张总认为方案 A 在技术上可行(基于 PoC 验证,P99 延迟降低 40%)」——自包含。
自包含的知识单元是查询质量的基础。如果每个单元都需要回到原文才能理解,查询就变成了全文检索——和没有编译一样。
原则三:增量编译,不是批量编译
不要攒了 50 篇文档再统一编译。每次新增内容(一场新会议、一篇新文章)就立刻编译、存入知识库。
这和 CI/CD 的理念一致:小批量、高频率。增量编译还能避免「编译疲劳」——一次性编译 50 篇文档,后面的质量一定比前面的差。
升维:知识库的编译质量决定了分析质量的上限
回到最开始的问题:怎么让知识库帮助提高分析和洞察的质量?
答案是: 知识库的编译方式决定了查询的上限。
这和数据库设计是一样的道理——索引设计决定了查询性能。你在一个没有索引的表上做全表扫描,再好的数据库引擎也跑不快。知识库也一样:如果知识没有被编译成适合你分析任务的结构,再强的 AI 也只能给你平庸的输出。
编译质量是分析质量的天花板。 AI 模型的能力是下限,知识库的编译质量是上限。
这也呼应了我在 Context Is Control 中的核心论点——上下文工程(Context Engineering)是 AI 时代最重要的工程能力。知识库编译,就是为 AI 构建高质量上下文的过程。
对听记和会议纪要的启示
现在市面上的 AI 会议工具大多在做「转写 + 摘要」。这是第一代产品——直接在原始转写稿上做生成。
第二代产品应该做的是: 编译 + 查询 + 生成。不是一个一次性的任务,而是一个持续积累的知识系统。每场会议的编译结果自动进入知识库,下一场会议的纪要自动引用历史上下文。
这时候,会议纪要就不再是「一次性的文档」,而是一个 不断生长的知识体。
你的 AI 会议纪要有没有遇到过「看起来正确但没用」的问题?你有没有尝试过先结构化再分析的方法?欢迎留言讨论。