上周五下午 4 点,一个管着 30 人销售团队的区域总监在钉钉里对悟空说了一句话:
「帮我把本周所有客户的跟进记录整理成表格,标记哪些超过 3 天没回访的,然后给对应的销售发个提醒。」
她没有写一行代码。她甚至不知道什么是 API。但 30 秒后,一张 AI 表格建好了,12 条超时记录标红了,12 条 DING 消息已经发到了对应销售的手机上。
这不是 demo,是她每天的工作方式。
一、一个被误解的门槛
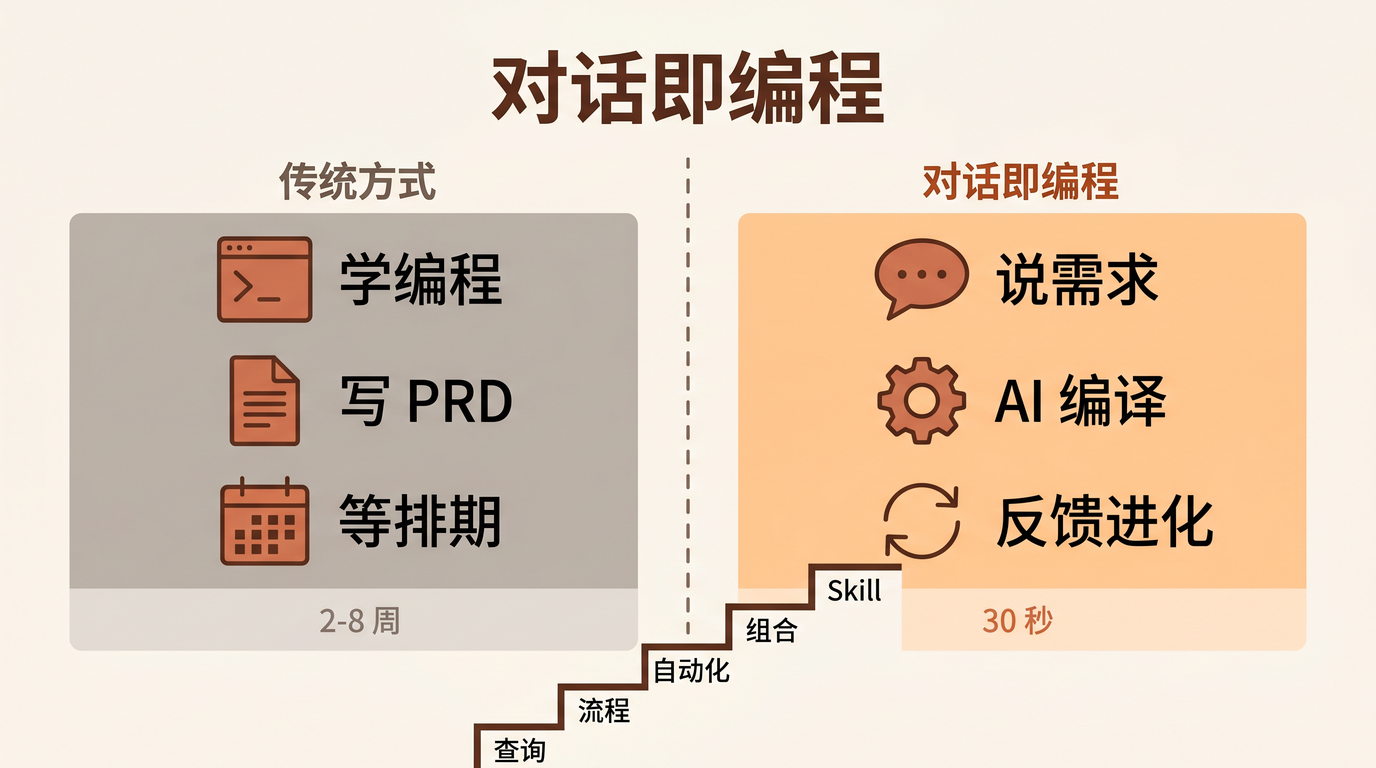
软件行业有一个根深蒂固的假设: 要让系统按你的方式工作,你得先学会它的语言。
想自动化客户跟进?你得学 Python 调 API。想做数据报表?你得学 SQL 写查询。想搭一个审批流?你得找个开发团队,写 PRD,排期,上线。
这个假设在过去的 30 年里基本成立。它制造了一个巨大的鸿沟:一边是懂技术的人,能把需求变成系统;一边是懂业务的人,只能手动执行或者花大钱请人开发。
但 2026 年,这个假设正在失效。
不是因为出现了更好的低代码平台——低代码本质上还是在编程,只是换了个更友好的界面。而是因为 LLM 从根本上改变了「编程」的含义: 你不再需要把需求翻译成机器能理解的语法,你只需要把需求说清楚。
说清楚,就是编程。
二、对话即编程:三层模型
我在实践中总结了一个框架,叫 「对话即编程」。它有三层:
┌──────────────────────────────────────────────────┐
│ 意 图 层 │
│ 「你说什么」—— 自然语言描述需求 │
│ 例:「每周一下午,统计上周未成交客户,发给销售」 │
├──────────────────────────────────────────────────┤
│ 编 译 层 │
│ 「AI 做什么」—— LLM 把意图翻译成工作流 │
│ 意图解析 → 步骤拆解 → 工具选择 → 代码生成 │
├──────────────────────────────────────────────────┤
│ 运 行 时 │
│ 「系统怎么跑」—— 钉钉提供数据、触发、交互 │
│ 审批 · 日历 · 群聊 · 通讯录 · AI 表格 · 待办 │
└──────────────────────────────────────────────────┘
↕ 反馈闭环(进化的引擎)
关键洞察:这三层之间的连接不是靠代码,而是靠 对话。你说需求,AI 编译执行,结果不对你就说「这里不对」,AI 修改重跑。每一次反馈都是一次迭代,每一次迭代系统都更贴合你的实际需求。
这就是标题里说的「会进化的系统」——它不是一次性交付的软件,而是一个在使用中持续生长的有机体。
三、一个系统是怎么长出来的
让我用一个完整的案例来说明。
第一阶段:一个简单请求
张琳是一家 B2B SaaS 公司的华东区销售总监。她的团队 30 人,管理 200+ 客户。她不懂技术,Excel 用到 VLOOKUP 就封顶了。
她做的第一件事,是在钉钉里对悟空说:
「帮我查一下,上周有哪些客户超过 5 天没有跟进记录。」
悟空的编译层做了什么?
- 意图解析:用户要查询「客户跟进记录」中「超过 5 天未更新」的条目
- 工具选择:需要调用钉钉通讯录查团队信息 + AI 表格查跟进记录
- 执行:
import subprocess
import json
from datetime import datetime, timedelta
# 查询 AI 表格中的跟进记录
result = subprocess.run(
["dws", "aitable", "record", "list",
"--base-id", "CUSTOMER_TRACKER_BASE",
"--table-id", "FOLLOW_UP_TABLE",
"--format", "json"],
capture_output=True, text=True
)
records = json.loads(result.stdout)
# 筛选超过 5 天未跟进的客户
cutoff = datetime.now() - timedelta(days=5)
stale = [r for r in records["data"]
if datetime.fromisoformat(r["last_follow_up"]) < cutoff]
print(f"共 {len(stale)} 个客户超过 5 天未跟进")
for r in stale:
print(f" {r['customer_name']} - 负责人: {r['owner']} - 最后跟进: {r['last_follow_up']}")
# generated by hugo AI
30 秒后,张琳拿到了一份清单。
这还不算「编程」。这只是一次查询。 但它埋下了一颗种子。
第二阶段:从查询到流程
第二天,张琳说了一句关键的话:
「这个清单能不能每周一早上自动跑?跑完了直接发到销售群里,@对应的人。」
这句话的性质变了。她不是在查询数据,她在 定义一个工作流。
悟空编译出来的东西:
触发条件:每周一 09:00
│
├─ ① 查询 AI 表格:超过 5 天未跟进的客户
├─ ② 按负责人分组
├─ ③ 在「华东销售群」发消息:
│ 「以下客户需要跟进:
│ @张三:客户A、客户B
│ @李四:客户C」
└─ ④ 给每个负责人创建待办,截止时间:本周三
张琳看到结果后说了第二句反馈:
「不要直接发群里,先发给我看一下,我确认了再发。」
系统 进化了:
触发条件:每周一 09:00
│
├─ ① 查询 AI 表格:超过 5 天未跟进的客户
├─ ② 按负责人分组
├─ ③ 发给张琳确认(私聊消息 + 确认按钮)
├─ ④ [等待确认] ← 这是进化出来的新节点
└─ ⑤ 确认后 → 发群消息 + 创建待办
注意这里发生了什么:张琳没有画流程图,没有写 if-else,她只是说了一句「先发给我看一下」。但系统理解了这个反馈,自动插入了一个人工确认节点。
这就是「对话即编程」的核心:你的反馈就是代码修改。
第三阶段:从流程到知识
两个月后,张琳的系统已经不只一个流程了。她有:
| 流程 | 触发方式 | 进化次数 |
|---|---|---|
| 客户跟进提醒 | 每周一 09:00 | 7 次 |
| 新客户自动建档 | 群聊中提到新客户时 | 4 次 |
| 周报自动生成 | 每周五 17:00 | 12 次 |
| 大单进展追踪 | 金额 > 50 万的客户有更新时 | 3 次 |
| 竞品动态提醒 | 每天 08:00 扫描群聊关键词 | 5 次 |
每个流程都不是一次性写好的。它们是被 用出来的。
周报流程是最典型的例子。第一版很简单——把本周所有跟进记录汇总。张琳说「太乱了,按客户分级排列」。第二版加了分级。张琳又说「加上和上周的对比,哪些客户进展了哪些停滞了」。第三版加了趋势分析。张琳说「把停滞超过 2 周的单独列出来,标红」。
12 次进化后,这份周报比她自己写的还好。
这就是进化系统的威力:它不是一次性交付一个 80 分的方案,而是通过 12 次反馈,长成了一个 95 分的方案。每次反馈的成本是一句话,而不是一个开发迭代。
四、为什么传统方案做不到
对比一下传统路径:
| 维度 | 传统方案 | 对话即编程 |
|---|---|---|
| 启动成本 | 写 PRD → 排期 → 开发 → 测试 → 上线(2-8 周) | 说一句话(30 秒) |
| 迭代成本 | 提需求 → 评审 → 开发 → 测试(1-2 周/次) | 说一句反馈(30 秒) |
| 迭代次数 | 通常 2-3 次就没人愿意改了 | 想改多少次就多少次 |
| 最终质量 | 80 分(因为迭代太贵,够用就收) | 95 分(因为迭代免费,可以一直优化) |
| 技术门槛 | 需要开发团队 | 会打字就行 |
核心差异在最后一行。传统方案的迭代成本限制了系统的进化次数。当每次迭代的边际成本趋近于零时,系统可以无限进化,直到完美匹配你的实际需求。
这不是效率的提升,是范式的转换。
五、为什么是钉钉 + 悟空
你可能会问:这个思路用在别的平台不行吗?
行,但钉钉有一个别的平台没有的东西: 中国企业工作流的全量上下文。
悟空能调用的不只是数据。它能理解:
- 通讯录:谁向谁汇报,谁在哪个部门,谁负责哪个客户
- 审批流:请假、报销、采购——已有的业务规则
- 群聊:信息在哪里流动,谁是关键节点
- 日历:什么时候有空,什么时候在开会
- AI 表格:结构化的业务数据
- 待办:任务的分配和完成状态
这些上下文是通用 AI 工具拿不到的。ChatGPT 可以帮你写代码,但它不知道你的组织架构。Copilot 可以帮你写文档,但它不知道你上周审批了什么。
悟空知道。因为你就在钉钉里工作。
用 dws(DingTalk Workspace CLI)做技术实现时,这种上下文优势非常明显:
# 查通讯录:找到华东区所有销售
team = subprocess.run(
["dws", "contact", "user", "search",
"--keyword", "华东", "--format", "json"],
capture_output=True, text=True
)
# 查日历:找到本周的会议
meetings = subprocess.run(
["dws", "calendar", "event", "list",
"--start", "2026-05-25T00:00:00+08:00",
"--end", "2026-05-31T23:59:59+08:00",
"--format", "json"],
capture_output=True, text=True
)
# 查 AI 表格:本周新增客户数
new_clients = subprocess.run(
["dws", "aitable", "record", "list",
"--base-id", "CRM_BASE",
"--table-id", "CLIENTS",
"--filter", "created_at >= '2026-05-25'",
"--format", "json"],
capture_output=True, text=True
)
# generated by hugo AI
三条命令,三个维度的业务数据。悟空不需要你去配置数据源、不需要你写 ETL 管道——数据就在那里,它直接去取。
六、进化的引擎:反馈循环
回到最核心的问题:系统怎么进化?
答案是三个字: 反馈循环。
┌──────────────────────────────┐
│ │
▼ │
① 你说需求 │
│ │
▼ │
② AI 编译执行 │
│ │
▼ │
③ 你看结果 │
│ │
┌────┴────┐ │
│ │ │
▼ ▼ │
满意 不满意 │
│ │ │
│ ▼ │
│ ④ 你说「这里不对」 │
│ │ │
│ ▼ │
│ ⑤ AI 修改重跑 │
│ │ │
│ └─────────────────────────┘
▼
⑥ 流程固化,等待下次触发
这个循环和传统软件开发的需求 → 开发 → 测试 → 交付有本质区别:
循环的时间单位不同。传统是周,这里是分钟。张琳的一个周报流程进化了 12 次,如果按传统方式,12 个迭代至少 12 周。她用对话完成了同样的进化,用了 3 天。
反馈的颗粒度不同。传统方式你只能说「这个报表不对」,开发去猜哪里不对。对话方式你可以说「第三列的数字格式改成百分比,标题从『客户统计』改成『客户健康度』,加上环比增长率」。颗粒度细到字段级别,而且 AI 不会理解错。
知识在积累。每次反馈不只是修改了这一次的输出,它还改变了 AI 对你业务的理解。第 12 次迭代时,悟空已经知道张琳说的「大客户」是指年合同额 100 万以上、「健康」是指最近 30 天有互动、「停滞」是指超过 2 周无进展。这些知识不是预设的,是从 12 次反馈中 长出来的。
七、Skill:进化的结晶
进化到一定阶段,稳定的流程会沉淀为 Skill。
Skill 是什么?用我在 SKILL.md 不是文档,是编译器 里的话说:它是一个 Markdown 文件,但它不是文档,它是编译器——AI 读到这个文件,就知道该怎么执行。
张琳的「周报生成」流程经过 12 次迭代后,被沉淀为一个 Skill:
---
name: weekly-sales-report
description: 华东区销售周报自动生成
triggers:
- schedule: "every Friday 17:00"
---
# 周报生成 Skill
## 数据源
- AI 表格:CRM_BASE / CLIENTS(客户数据)
- AI 表格:CRM_BASE / FOLLOW_UPS(跟进记录)
- 通讯录:华东区销售团队
## 输出结构
1. 客户健康度总览(按 A/B/C 分级)
2. 本周进展(新增跟进记录数、新签客户数)
3. 环比分析(与上周对比,百分比格式)
4. 停滞预警(> 2 周无进展的客户,标红)
5. 下周重点(基于历史数据推荐)
## 格式要求
- 标题用「客户健康度」不用「客户统计」
- 数字格式:金额用万元,增长率用百分比
- 大客户定义:年合同额 ≥ 100 万
# generated by hugo AI
这个 Skill 做了什么?它把 12 次对话中积累的 业务知识 固化了下来。下次新来的销售助理说「帮我生成本周周报」,系统已经知道所有的业务规则,不需要再迭代 12 次。
Skill 是进化系统的记忆。没有 Skill,每次对话都从零开始。有了 Skill,系统站在过去的肩膀上。
这就是我在 当钉钉变成命令行 中说的:过去靠定制软件解决的个性化需求,现在用 Token 就能交付。而 Skill 让 Token 的消耗越来越少——因为系统越用越聪明,需要的纠正越来越少。
八、给不懂技术的人的建议
如果你是不懂技术、但想让自己的工作流程程序化的人,这是我能给的最实际的建议:
第一步:从一个小请求开始。
不要上来就想「我要一个完整的 CRM 系统」。先说:「帮我查一下上周哪些客户没有跟进记录。」一个查询,30 秒出结果。
第二步:给反馈,不要忍着。
结果不对就说不对。格式不好就说不好。缺了字段就说缺什么。每一次反馈都是一次免费的迭代。不要想「差不多就行了」——在这个范式里,「完美」的成本和「差不多」一样。
第三步:让系统自动跑。
当手动跑了几次、调到你满意了,就说「这个每周一自动跑」。从手动到自动,只需要一句话。
第四步:组合流程。
单个流程稳定后,把它和其他流程串起来。客户跟进提醒 → 超时自动创建待办 → 待办完成后更新表格 → 周五汇总成周报。每个节点都是你说一句话建起来的。
第五步:沉淀为 Skill。
当你发现一个流程你已经用了三个月、改了十几次、现在很少需要改了——它就是一个成熟的 Skill。告诉 AI「把这个流程保存成 Skill」,下次别人也能直接用。
九、本质
回到最根本的问题。
过去 50 年,软件开发的本质是什么?是人把业务逻辑翻译成机器能执行的指令。这个翻译过程需要专业知识(编程语言),需要大量沟通(需求评审),需要持续维护(Bug 修复)。
LLM 改变了什么? 它让翻译过程消失了。
你不需要学 Python,因为 AI 会 Python。你不需要写 SQL,因为 AI 会 SQL。你不需要画流程图,因为 AI 能理解你的自然语言描述。
但 LLM 没有改变的是: 你需要知道你要什么。
这是「对话即编程」最深刻的地方——它没有降低对业务知识的要求,反而提高了。因为当技术门槛消失后, 决定系统质量上限的,是你对自己业务的理解深度。
张琳的周报为什么比开发团队做的好?不是因为 AI 更强,而是因为她知道什么指标真正重要、什么格式老板看着最舒服、什么预警阈值刚好不会太多也不会太少。这些知识在她的脑子里,过去没法变成系统,因为翻译成本太高。现在,翻译成本为零,这些知识直接变成了生产力。
最会编程的人,不是最懂语法的人,而是最懂业务的人。
这句话放在 2020 年是鸡汤。放在 2026 年,是事实。
你在自己的工作中有没有类似的体验?哪些重复性的工作你想过自动化,但一直觉得「得找开发才能做」?现在不用了——说出来就行。欢迎留言讨论。