上个月,我发现一个跑了 3 周的定时任务每天都在用 Claude Sonnet 4 做一件极其简单的事——搜索两条关键词、整理成表格、发给我。每次消耗约 8000 token,成本 $0.12。换成 GPT-4o-mini,同样的任务 2000 token 就够,成本 $0.003。
3 周 × 每天 $0.12 = $2.52。换成 mini 只要 $0.06。
这不是模型的问题,也不是调度器的问题——是 调度器和模型选择之间缺了一层。你的 cron 系统知道什么时候该跑这个任务,但完全不知道该用什么模型、多少推理深度来跑。
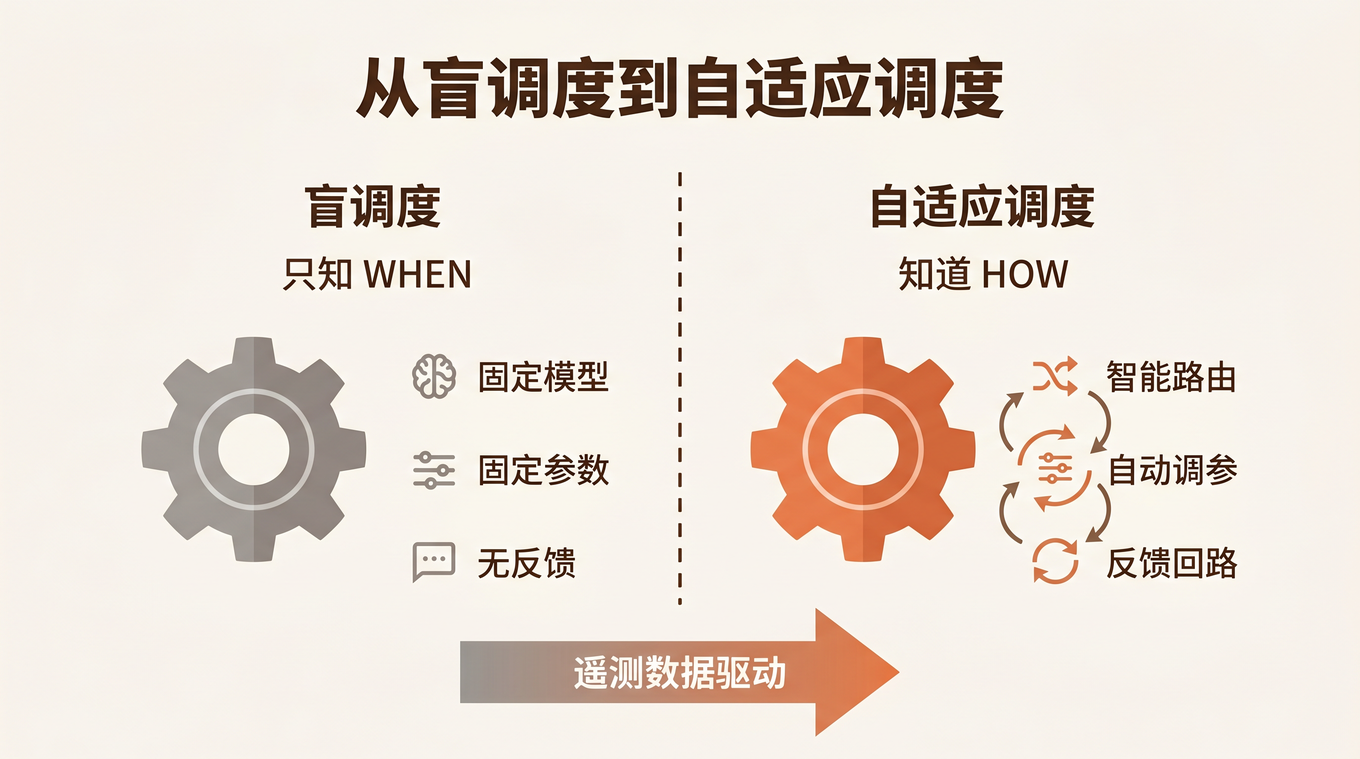
这个问题不是 Hermes Agent 独有的。几乎所有 AI Agent runtime 的定时任务系统都是「发射后不管」的设计——调度器只管触发,模型选择要么用户手动指定、要么全局默认。这在传统 cron 时代没问题(bash script.sh 不涉及模型选择),但在 Agent 时代, 每次执行的「执行参数」对成本和成功率的影响,远大于「执行时间」。
我在 当 10 万个定时任务同时敲门:MaaS 平台调度优化实战 中讨论过平台级的调度优化——整点风暴、确定性 jitter、分级调度。那篇解决的是「什么时候跑」的问题。这篇解决的是另一个维度的问题:「用什么跑、怎么跑得更好」。
一、盲调度器:2039 行代码的「防御堡垒」
要理解缺了什么,先看已有的东西有多扎实。
我最近深入读了 Hermes Agent 的 cron 调度器源码(cron/scheduler.py,2039 行)。这是一个工程质量很高的调度系统,几乎覆盖了你能想到的所有稳定性场景:
┌─────────────────────────────────────────────────────────┐
│ scheduler.py 稳定性矩阵 │
├──────────────────┬──────────────────────────────────────┤
│ 进程级隔离 │ fcntl/msvcrt 文件锁,防重复 tick │
│ 超时保护 │ 不活跃超时 600s,非硬超时 │
│ Provider 容错 │ fallback 链 + credential pool 轮换 │
│ 投递可靠性 │ live adapter → standalone HTTP 双通道 │
│ 安全防护 │ prompt 注入扫描 + 路径穿越校验 │
│ 并行优化 │ workdir/profile job 串行,其余并行 │
│ 资源回收 │ agent.close() + MCP 孤儿进程清理 │
└──────────────────┴──────────────────────────────────────┘
但翻遍 2039 行代码, 没有一行用于记录执行结果、分析历史、或基于经验调整策略。每次 job 执行完,状态只更新到 last_status: 「ok」 或 「error」 这种二值标记——没有 token 消耗、没有迭代次数、没有工具调用分布、没有失败原因分类。
这就像一个运维团队建了完善的告警系统,但 没接监控系统。
二、AI Agent 的 cron job 为什么不一样
传统 cron 的执行参数是确定的:跑哪个脚本、用什么解释器、超时多少秒。这些参数一旦设好,很少需要调整。
AI Agent 的 cron job 多了一层「 推理参数 」:
| 参数 | 影响 | 传统 cron 有吗 |
|---|---|---|
| 模型选择 | 成本差 10-50 倍,能力差 2-5 倍 | ❌ |
| reasoning_effort | 推理深度,影响 token 消耗和延迟 | ❌ |
| max_iterations | Agent 工具调用循环上限 | ❌ |
| enabled_toolsets | 可用工具集,影响 token 开销 | ❌ |
| prompt(含 skill) | 上下文长度,直接影响 token 成本 | 部分(脚本参数) |
这些参数的「最优值」 取决于任务本身的特征——而任务特征只有跑过才知道。一个每天跑的分析任务,前 10 次平均只用 2 次迭代就完成了,那 max_iterations=90 就是浪费(虽然不会真的跑 90 次,但模型不知道自己只需要 2 次,可能在简单任务上「想太多」)。
这就是「盲调度」的核心问题:执行参数和执行经验之间没有反馈回路。
三、三阶段实施路径
解决这个问题不需要大改调度器架构。我设计了一个三阶段的实施路径,每阶段独立可用,后一阶段依赖前一阶段的数据:
Phase 1 Phase 2 Phase 3
遥测采集 → 模型路由 → 参数自调优
(5 行代码) (opt-in) (opt-in)
│ │ │
▼ ▼ ▼
telemetry.jsonl auto_select_model() auto_tune_params()
│ │ │
▼ ▼ ▼
成本分析 自动升降级 自动调整推理深度
故障诊断 自动换 provider 自动调整迭代上限
Phase 1:遥测采集(最小可行方案)
这是 ROI 最高的一步——5 行代码的改动,换来所有后续优化的数据基础。
在 scheduler.py 的 _run_job_impl 函数中,Agent 执行完后(无论成功失败),记录一次执行指标:
# cron/telemetry.py
from __future__ import annotations
import json
import os
from dataclasses import asdict, dataclass, field
from datetime import datetime
from pathlib import Path
from typing import Optional
from hermes_constants import get_hermes_home
@dataclass
class JobRunMetrics:
"""单次 cron job 执行的可观测数据。
设计原则:只记录事实(what happened),不记录推断(why it happened)。
推断留给上层分析。
"""
job_id: str
job_name: str
model: str
provider: str
success: bool
duration_seconds: float
token_usage: dict = field(default_factory=dict)
iteration_count: int = 0
tool_call_count: int = 0
inactivity_timeout: bool = False
error_type: Optional[str] = None # "rate_limit" | "timeout" | "auth" | "injection" | None
timestamp: str = field(default_factory=lambda: datetime.utcnow().isoformat())
def record_run(metrics: JobRunMetrics) -> None:
"""追加写入遥测数据。JSONL 格式,append-only。"""
path = Path(get_hermes_home()) / "cron" / "telemetry.jsonl"
path.parent.mkdir(parents=True, exist_ok=True)
with open(path, "a", encoding="utf-8") as f:
f.write(json.dumps(asdict(metrics), ensure_ascii=False) + "\n")
def load_job_history(job_id: str, limit: int = 20) -> list[dict]:
"""读取指定 job 的最近 N 次执行记录。"""
path = Path(get_hermes_home()) / "cron" / "telemetry.jsonl"
if not path.exists():
return []
lines = path.read_text(encoding="utf-8").strip().splitlines()
records = [json.loads(line) for line in lines if line.strip()]
return [r for r in records if r.get("job_id") == job_id][-limit:]
# generated by hugo AI
接入点——在 _run_job_impl 的 finally 块中,agent.close() 之前:
# scheduler.py 约 L1838 处,finally 块内
from cron.telemetry import JobRunMetrics, record_run
try:
_metrics = JobRunMetrics(
job_id=job_id,
job_name=job_name,
model=model,
provider=runtime_provider,
success=_job_success,
duration_seconds=_job_duration,
token_usage=_get_token_usage(agent),
iteration_count=_get_iteration_count(agent),
tool_call_count=_get_tool_call_count(agent),
inactivity_timeout=_inactivity_timeout,
error_type=_classify_error(e) if not _job_success else None,
)
record_run(_metrics)
except Exception:
logger.debug("Job '%s': telemetry recording failed", job_id)
# generated by hugo AI
为什么用 JSONL 而不是 SQLite? 追加写入没有锁竞争,grep 就能做基础分析,和 Hermes 的 state.db 不耦合。如果后续需要复杂查询,可以加一个定时聚合任务把 JSONL 转成结构化格式。
Phase 1 上线后,你立刻可以做三件事:
# 1. 成本分析:哪些 job 最贵
cat ~/.hermes/cron/telemetry.jsonl | \
jq -s 'group_by(.job_name) | map({
name: .[0].job_name,
runs: length,
avg_tokens: (map(.token_usage.total // 0) | add / length)
}) | sort_by(.avg_tokens) | reverse'
# 2. 故障诊断:哪些 job 经常失败
cat ~/.hermes/cron/telemetry.jsonl | \
jq -s 'group_by(.job_id) | map({
name: .[0].job_name,
failure_rate: (map(select(.success | not)) | length) / length
}) | sort_by(.failure_rate) | reverse'
# 3. 容量分析:哪些 job 迭代次数最少(可能过度配置)
cat ~/.hermes/cron/telemetry.jsonl | \
jq -s 'group_by(.job_id) | map({
name: .[0].job_name,
avg_iters: (map(.iteration_count) | add / length)
}) | sort_by(.avg_iters)'
# generated by hugo AI
Phase 2:模型路由(基于历史自动选择模型)
有了 Phase 1 的数据,就可以做模型路由了。核心逻辑很简单: 根据一个 job 最近 N 次的表现,决定下次用什么模型。
# cron/model_router.py
from __future__ import annotations
import logging
from dataclasses import dataclass
from statistics import mean
from typing import Optional
from cron.telemetry import load_job_history
logger = logging.getLogger(__name__)
# 模型层级:数字越大能力越强(也越贵)
_MODEL_TIERS: list[list[str]] = [
["openai/gpt-4o-mini", "anthropic/claude-haiku-3"],
["openai/gpt-4o", "anthropic/claude-sonnet-4"],
["anthropic/claude-opus-4", "openai/o3"],
]
def _find_tier(model: str) -> int:
"""返回模型所在层级,找不到返回中间层。"""
for i, tier in enumerate(_MODEL_TIERS):
if any(model in m for m in tier):
return i
return 1 # 默认中间层
def _model_at_tier(current_model: str, target_tier: int) -> str:
"""在当前模型的同一 provider 中找到目标层级的对应模型。"""
provider = current_model.split("/")[0] if "/" in current_model else ""
for model in _MODEL_TIERS[target_tier]:
if model.startswith(provider + "/"):
return model
# fallback: 取目标层级的第一个
return _MODEL_TIERS[target_tier][0]
@dataclass
class RoutingDecision:
"""路由决策结果,附带理由(方便遥测记录和调试)。"""
model: str
provider: Optional[str]
reason: str
def auto_select_model(
job_id: str,
current_model: str,
current_provider: Optional[str] = None,
history_size: int = 10,
) -> RoutingDecision:
"""基于历史执行数据,为下次运行选择模型。
三条策略规则(按优先级):
1. 高失败率 → 升级模型(用更强的模型提高成功率)
2. 低迭代 + 高成功率 → 降级模型(任务简单,省钱)
3. 频繁 rate_limit → 切换 provider(同一个模型换个供应商)
Args:
job_id: cron job 的唯一 ID
current_model: 当前配置的模型
current_provider: 当前配置的 provider
history_size: 参考最近 N 次执行记录
Returns:
RoutingDecision: 推荐的模型、provider、和决策理由
"""
history = load_job_history(job_id, limit=history_size)
if len(history) < 5:
# 冷启动:数据不足,保持现有配置
return RoutingDecision(current_model, current_provider, "cold_start")
recent = history[-history_size:]
failure_rate = sum(1 for r in recent if not r["success"]) / len(recent)
avg_iters = mean(r.get("iteration_count", 0) for r in recent)
rate_limit_hits = sum(
1 for r in recent if r.get("error_type") == "rate_limit"
)
current_tier = _find_tier(current_model)
# 策略 1:失败率 > 30% → 升级一档
if failure_rate > 0.3 and current_tier < len(_MODEL_TIERS) - 1:
upgraded = _model_at_tier(current_model, current_tier + 1)
return RoutingDecision(
upgraded, None,
f"upgrade: failure_rate={failure_rate:.0%} > 30%",
)
# 策略 2:平均迭代 < 3 次 + 零失败 → 降级一档
if avg_iters < 3 and failure_rate == 0 and current_tier > 0:
downgraded = _model_at_tier(current_model, current_tier - 1)
return RoutingDecision(
downgraded, None,
f"downgrade: avg_iters={avg_iters:.1f}, failure_rate=0",
)
# 策略 3:rate_limit 频繁 → 保持模型但建议换 provider
if rate_limit_hits > 2:
return RoutingDecision(
current_model, None, # provider=None 让 resolve_runtime_provider 重新选
f"switch_provider: rate_limit_hits={rate_limit_hits}",
)
# 默认:保持不变
return RoutingDecision(
current_model, current_provider, "stable"
)
# generated by hugo AI
接入点在 _run_job_impl 中构造 AIAgent 之前(约 L1486):
# scheduler.py 原有代码:
# model = job.get("model") or os.getenv("HERMES_MODEL") or ""
# 替换为:
if job.get("auto_model"): # 显式 opt-in,不影响现有用户
from cron.model_router import auto_select_model
_routing = auto_select_model(
job_id=job_id,
current_model=job.get("model") or os.getenv("HERMES_MODEL") or "",
current_provider=job.get("provider"),
)
model = _routing.model
logger.info(
"Job '%s': auto_model → %s (reason: %s)",
job_id, model, _routing.reason,
)
else:
model = job.get("model") or os.getenv("HERMES_MODEL") or ""
# generated by hugo AI
关键设计决策:opt-in 而非默认启用。 自动路由是一个会改变系统行为的特性,必须让用户显式选择。在 cronjob 工具的 create/update action 中加一个 auto_model: true 参数即可。
Phase 3:参数自调优(推理深度 × 迭代上限)
模型路由解决的是「用什么引擎」的问题。参数调优解决的是「油门踩多深」的问题。
# cron/param_tuner.py
from __future__ import annotations
import logging
from dataclasses import dataclass
from statistics import mean
from typing import Optional
from cron.telemetry import load_job_history
logger = logging.getLogger(__name__)
@dataclass
class ParamOverrides:
"""需要覆盖的运行参数。None 表示保持默认。"""
reasoning_effort: Optional[str] = None
max_iterations: Optional[int] = None
reason: str = ""
def auto_tune_params(
job_id: str,
default_max_iterations: int = 90,
default_reasoning_effort: str = "medium",
history_size: int = 10,
) -> ParamOverrides:
"""基于历史执行数据,调整运行参数。
三条规则:
1. 简单任务(迭代少 + 无失败)→ 降低 reasoning_effort,减少 max_iterations
2. 经常超时 → 降低 max_iterations,让 agent 更快放弃
3. 经常失败但不超时 → 提高 reasoning_effort,给更多迭代机会
Args:
job_id: cron job 的唯一 ID
default_max_iterations: 全局默认的最大迭代数
default_reasoning_effort: 全局默认的推理深度
history_size: 参考最近 N 次执行记录
Returns:
ParamOverrides: 需要覆盖的参数及其理由
"""
history = load_job_history(job_id, limit=history_size)
if len(history) < 5:
return ParamOverrides(reason="cold_start")
recent = history[-history_size:]
avg_iters = mean(r.get("iteration_count", 0) for r in recent)
success_rate = sum(1 for r in recent if r["success"]) / len(recent)
timeout_rate = sum(
1 for r in recent if r.get("inactivity_timeout")
) / len(recent)
# 规则 1:简单任务 → 降低推理深度
if avg_iters < 2 and success_rate == 1.0:
return ParamOverrides(
reasoning_effort="low",
max_iterations=min(30, default_max_iterations),
reason=f"simple_task: avg_iters={avg_iters:.1f}, success=100%",
)
# 规则 2:经常超时 → 收紧迭代上限
if timeout_rate > 0.2:
tightened = max(10, int(avg_iters * 1.5))
return ParamOverrides(
max_iterations=tightened,
reason=f"timeout_prone: rate={timeout_rate:.0%}, cap={tightened}",
)
# 规则 3:失败多但不超时 → 给更多机会
if success_rate < 0.5 and timeout_rate == 0:
return ParamOverrides(
reasoning_effort="high",
max_iterations=min(120, int(avg_iters * 2)),
reason=f"struggling: success={success_rate:.0%}, boosting",
)
return ParamOverrides(reason="stable")
# generated by hugo AI
接入点——在 AIAgent 构造时:
# scheduler.py 约 L1625 处
_param_overrides = ParamOverrides()
if job.get("auto_tune"):
from cron.param_tuner import auto_tune_params
_param_overrides = auto_tune_params(
job_id=job_id,
default_max_iterations=max_iterations,
default_reasoning_effort=str(reasoning_config.get("effort", "medium")),
)
if _param_overrides.max_iterations:
max_iterations = _param_overrides.max_iterations
if _param_overrides.reasoning_effort:
from hermes_constants import parse_reasoning_effort
reasoning_config = parse_reasoning_effort(
_param_overrides.reasoning_effort
)
logger.info(
"Job '%s': auto_tune → iters=%d, effort=%s (reason: %s)",
job_id, max_iterations,
_param_overrides.reasoning_effort or "default",
_param_overrides.reason,
)
agent = AIAgent(
model=model,
max_iterations=max_iterations,
reasoning_config=reasoning_config,
# ... 其余参数不变
)
# generated by hugo AI
四、设计取舍:为什么不是更聪明的方案
读完上面的实现,你可能会想:这太粗糙了。为什么不用 Bayesian optimization 自动搜索最优参数?为什么不训练一个轻量模型来预测最佳配置?
好问题。我选择这个「三条规则」方案,是有意为之。
取舍一:规则 vs 学习
| 维度 | 规则系统(本方案) | 学习型系统 |
|---|---|---|
| 实现复杂度 | 低(~200 行) | 高(需要训练 pipeline) |
| 可解释性 | 每次决策有明确理由 | 黑盒 |
| 冷启动 | 5 次执行即可生效 | 需要数百次训练 |
| 安全性 | 只升降一档,有保护 | 可能学到异常策略 |
| 适用规模 | 2-100 个 job | 1000+ 个 job |
对于个人 Agent(通常 2-20 个 cron job),规则系统已经够用。 学习型系统在 job 数量达到三位数时才有意义——那时候你可以把遥测数据喂给一个轻量分类器,但那是另一个话题了。
取舍二:opt-in vs 默认启用
自动路由和自动调参都是 opt-in 的(job.get(「auto_model」)、job.get(「auto_tune」))。原因很简单: 改变用户显式配置的参数是一个高信任操作。
想象一下:你精心配置了一个 job 用 Claude Opus 4 做复杂的代码审查,某天自动路由发现「最近 5 次迭代次数都很低,降级到 Haiku」——因为那 5 次恰好是简单 PR。降级后第一次遇到复杂 PR 就漏了关键 bug。
opt-in 意味着用户理解并接受了这个行为。在 cron job 的 UI/CLI 中可以加一个说明:「启用自动模型路由后,系统将根据历史执行数据自动选择模型层级」。
取舍三:JSONL vs SQLite
遥测数据选了 JSONL 而非写入 state.db。这是刻意的解耦:
state.db是 session store,有 FTS5 全文索引,schema 复杂,cron 遥测不需要这些- JSONL 可以
grep、jq、直接喂给 pandas, 分析友好 - 如果数据量真的成了问题(几十万条),可以加一个定时任务做聚合归档——但这在个人 Agent 场景下不太可能发生
五、一个不需要改代码的替代方案
如果你不想改 Hermes Agent 的源码,有一个利用现有机制的替代方案——用 cron 的 script + wake gate 做外部决策。
思路:在 script 阶段读取历史数据,把决策结果注入 prompt,让 Agent 自己在执行中「知道」应该用什么策略:
#!/usr/bin/env python3
# ~/.hermes/scripts/smart_router.py
"""外部决策脚本:读取遥测数据,输出路由建议。
这个脚本的输出会被注入到 Agent 的 prompt 中。
它不能真正改变模型(需要改 scheduler.py),
但可以在 prompt 中指导 Agent 的行为策略。
"""
import json
import os
from pathlib import Path
TELEMETRY = Path(os.environ.get("HERMES_HOME", "~/.hermes")) / "cron" / "telemetry.jsonl"
JOB_ID = os.environ.get("CRON_JOB_ID", "")
def analyze(job_id: str) -> dict:
if not TELEMETRY.exists() or not job_id:
return {"suggestion": "normal", "note": "no history"}
records = [
json.loads(line)
for line in TELEMETRY.read_text().strip().splitlines()
if json.loads(line).get("job_id") == job_id
]
if len(records) < 5:
return {"suggestion": "normal", "note": f"only {len(records)} runs"}
recent = records[-10:]
avg_iters = sum(r.get("iteration_count", 0) for r in recent) / len(recent)
failures = sum(1 for r in recent if not r["success"])
if failures > 5:
return {
"suggestion": "be_thorough",
"note": f"high failure rate ({failures}/10), take your time",
}
if avg_iters < 2 and failures == 0:
return {
"suggestion": "be_concise",
"note": "simple task, minimize token usage",
}
return {"suggestion": "normal", "note": "stable performance"}
result = analyze(JOB_ID)
print(json.dumps(result))
# generated by hugo AI
这个方案的局限是 无法真正切换模型——它只能在 prompt 里告诉 Agent「请高效执行」或「请仔细执行」。但对于 reasoning_effort 和工具使用策略,prompt 指导是有效的。
六、串联起来:自适应调度的完整回路
把三个阶段串起来,一个完整的自适应 cron 系统长这样:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ tick() │────▶│ 遥测采集 │────▶│ telemetry │
│ 触发 job │ │ record_run() │ │ .jsonl │
└──────┬───────┘ └──────────────┘ └──────┬───────┘
│ │
│ 读取历史 │ 追加写入
▼ │
┌──────────────┐ ┌──────────────┐ │
│ model_router │◀────│ load_history │◀────────────┘
│ param_tuner │ │ │
└──────┬───────┘ └──────────────┘
│
│ 输出决策
▼
┌──────────────┐
│ AIAgent │
│ (用推荐的 │
│ 模型+参数) │
└──────────────┘
每一次执行都产生数据,数据驱动下一次执行的决策。这不是一次性的配置优化,而是一个 持续学习的反馈回路——虽然「学习」的方式只是几条 if-else 规则。
回到开头的例子:那个每天用 Claude Sonnet 4 做简单搜索摘要的 job,如果启用了 Phase 2,前 5 次执行后就会被自动降级到 GPT-4o-mini,每周节省 $0.80。听起来不多,但如果你有 20 个这样的 job,一年就是 $832。
自适应调度不是锦上添花。在 AI Agent 时代,它是成本控制的基本功。
你在自己的 Agent 定时任务中遇到过「过度配置」或「配置不足」的问题吗?欢迎留言讨论。