2023 年 3 月,一个名叫 Toran Bruce Richards 的开发者发布了 AutoGPT,两周内 GitHub Star 突破 10 万。他在 README 里写道:「给 AI 一个目标,它自己规划、自己执行、自己反思。」不需要你画流程图,不需要定义任务依赖——完全自治。
三个月后,Richards 的 GitHub Issues 页面变成了大型翻车现场。一个被反复引用的案例:用户让 AutoGPT「研究人工智能的历史」,Agent 搜索了 10 篇文章,保存,然后又搜索了 8 篇,再保存,然后检查自己保存的文件,然后重新搜索……无限循环,API 费用烧了几十美元,一事无成。AutoGPT 的 GitHub 仓库里记录了超过 200 个类似的 infinite loop issue。
AutoGPT 的失败让行业得出了一个看似正确的结论: Agent 需要预定义的执行图。于是 LangGraph 成了 2026 年最受欢迎的 Agent 框架——62% 的开发者选择了它,正是因为它提供了精细的状态机控制和可预测的执行路径。
但我跟很多在用 LangGraph 的团队聊过,他们私下都在抱怨同一件事: 画图太痛苦了。 每增加一个能力,就要重新设计图的拓扑结构;每遇到一个边界情况,就要加一条边和一个条件分支。开发者的时间,一半花在写 Agent 逻辑,另一半花在维护那张 DAG。
这就引出了一个真正的问题:DAG 是答案吗?还是我们在 AutoGPT 的阴影下过度矫正了?
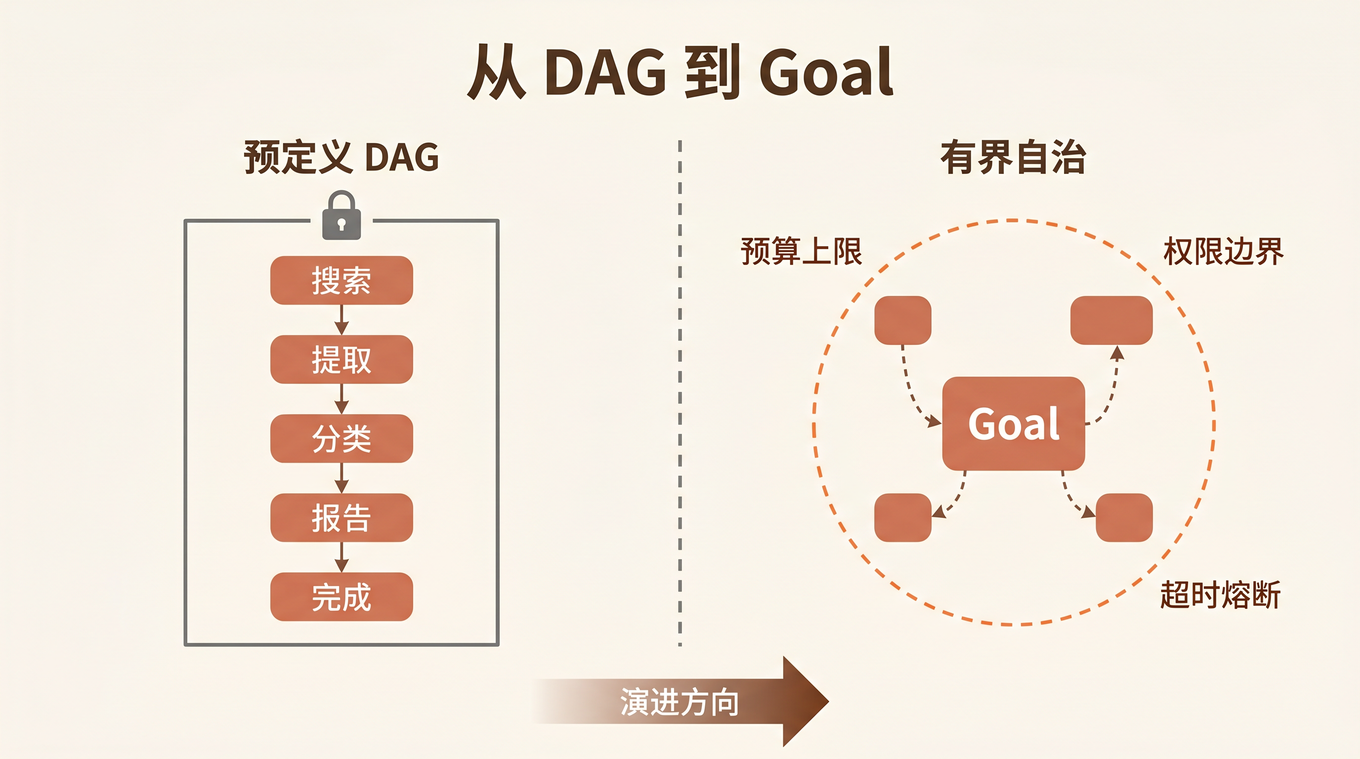
DAG 的真正问题
先说清楚,我不是要全盘否定 DAG。在确定性工作流中——比如数据处理管道、CI/CD 流水线、审批流程——DAG 是正确的设计。步骤已知、依赖关系固定、异常路径可枚举。这些场景里,DAG 提供了可预测性和可审计性,这是生产环境的硬需求。
但多智能体系统的本质是什么?是 让 AI 做决策。当你预定义了一张执行图,你其实是在说:「我已经提前知道这个任务应该怎么分解、步骤之间有什么依赖、遇到异常该怎么处理。」
问题是,你不可能提前知道这些。
一个真实的场景:你让 Agent 系统「分析竞品最近一个月的动态,生成一份报告」。用 DAG 的话,你可能会画出这样的图:
[搜索竞品新闻] → [提取关键事件] → [分类整理] → [生成报告]
↓ (异常)
[重试搜索] → [降级到缓存数据]
这看起来合理。但实际执行时会发生什么?Agent 在搜索阶段发现竞品刚发了一个重大公告,这时候它应该停下来深挖这个公告的细节,而不是按 DAG 继续走「提取关键事件」。或者它发现竞品的新闻太少,应该转向分析竞品的 GitHub 提交记录和招聘信息来推断战略方向。
这些决策是 DAG 画不出来的。 因为 DAG 的本质是「开发者在写代码时做的决策」,而 Agent 的价值是「在执行时根据实时信息做决策」。两者存在根本性的张力。
纯 Goal-driven 为什么也失败了
那回到 AutoGPT 的思路——只给目标,让 Agent 自己生成 DAG 再执行。这个方向是对的吗?
方向对,但执行方式错了。AutoGPT 的致命问题不在于「让 Agent 规划」,而在于它 没有任何约束。一张白纸交给一个能力不稳定的规划者(LLM),结果自然是混沌的。
具体来说,纯 Goal-driven 有三个工程层面的硬伤:
1. 任务分解质量不稳定。 给 LLM 一个中等复杂度的目标,它可能分解出 3 个子任务,也可能分解出 15 个。有的子任务太大(「完成整个后端」),有的太小(「创建一个空文件」)。依赖关系判断也经常出错——把有因果关系的步骤并行了,把可以并行的步骤串行了。
2. 失败时不会调整计划。 LLM 在规划阶段生成了一个 DAG,然后忠实执行。当某个节点失败时,它不会重新规划——因为 DAG 是「一次性产物」,Agent 没有「修改计划」的能力,只有「按计划执行」的能力。结果就是:错误的计划 + 忠实的执行 = 灾难。
3. 成本不可控。 每一步规划、执行、反思都是 LLM 调用。没有结构约束,Agent 可能反复规划-执行-反思-重新规划。AutoGPT 用户报告过单次运行消耗数百美元 API 费用的案例。
第三条路:有界自治
DAG 太死板,纯 Goal-driven 太混沌。真正的答案在中间——有界自治(Bounded Autonomy)。
核心思想只有一句话: 给 Agent 一个 playground,而不是一张白纸。
Playground 有围栏——这些是硬编码的安全边界、成本控制、合规检查。围栏之内,Agent 完全自治——自己决定怎么分解任务、用什么工具、如何处理异常。
┌──────────────────────────────────────────────────┐
│ Playground │
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 子任务A │──→│ 子任务B │──→│ 子任务C │ │
│ │(Agent自决)│ │(Agent自决)│ │(Agent自决)│ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │
│ ────── 围栏 ────── │
│ · 预算上限:$5 │
│ · 最大步数:20 │
│ · 禁止操作:删除生产数据、发送邮件 │
│ · 必须操作:每步记录审计日志 │
└──────────────────────────────────────────────────┘
这不是理论。2026 年 5 月,Anthropic 在 Claude Code 2.1 中发布了 /goal 命令,这正是有界自治的一个教科书级实现。
Claude Code /goal:教科书级的实现
Claude Code 的 /goal 命令让开发者可以设定一个完成条件,然后 Agent 自主工作直到条件满足。它的工作方式是这样的:
- 开发者输入
/goal 所有测试通过且代码覆盖率 > 80% - Agent 进入自主循环:分析代码 → 修改 → 运行测试 → 检查结果 → 决定下一步
- 每一轮结束后,一个独立的「检查模型」判断完成条件是否满足
- 条件满足时,目标自动清除,控制权返回开发者
关键不在于 Agent 能自主执行——AutoGPT 也能。关键在于 围栏的设计。
来自 VILA-Lab 对 Claude Code 源码的逆向分析(约 512K 行 TypeScript 代码),一个惊人的发现是: 只有 1.6% 的代码是 AI 决策逻辑,其余 98.4% 都是确定性基础设施——权限门控、上下文管理、工具路由、错误恢复。
这意味着什么?Agent 的「智能」只占系统的极小部分,绝大部分工程量在于构建那个 playground 的围栏:
from dataclasses import dataclass, field
from typing import Optional
from enum import Enum
class GuardType(Enum):
COST = "cost"
STEP = "step"
PERMISSION = "permission"
TIME = "time"
@dataclass
class PlaygroundConstraint:
"""围栏定义——Agent 自治的边界。"""
guard_type: GuardType
limit: float | int
on_violation: str = "stop" # stop | fallback | escalate
metadata: dict = field(default_factory=dict)
@dataclass
class GoalSpec:
"""目标定义——不是 DAG,而是完成条件 + 围栏。"""
completion_condition: str # 自然语言描述的完成条件
constraints: list[PlaygroundConstraint]
available_tools: list[str] # 可用工具白名单
context: Optional[str] = None # 初始上下文
# 示例:一个有界自治的任务定义
goal = GoalSpec(
completion_condition="所有单元测试通过,无 lint 错误",
constraints=[
PlaygroundConstraint(GuardType.COST, limit=5.0),
PlaygroundConstraint(GuardType.STEP, limit=30),
PlaygroundConstraint(GuardType.PERMISSION, limit=0,
metadata={"forbidden": ["rm -rf", "git push --force"]}),
PlaygroundConstraint(GuardType.TIME, limit=600), # 10 分钟
],
available_tools=["terminal", "read_file", "write_file", "run_tests"],
)
# generated by hugo AI
Agent 在这个 playground 内完全自治——它自己决定改哪个文件、先改哪个后改哪个、怎么验证。但围栏是不可突破的:超过 30 步就停,超过 $5 就停,试图执行危险命令就停。
这就是 Goal 和 Graph 的正确关系:Goal 定义「做什么」和「不能做什么」,Agent 在执行时自己生成「怎么做」的隐式 DAG。
框架对比:三个范式的本质差异
把今天主流的多智能体框架放在这个视角下看,它们的本质差异就清晰了:
| 维度 | LangGraph(DAG-first) | AutoGPT(Goal-only) | Claude Code /goal(有界自治) |
|---|---|---|---|
| 谁做任务分解 | 开发者(编码时) | Agent(运行时) | Agent(运行时),但有围栏 |
| 执行路径 | 预定义状态机 | 完全自主 | 自主 + 确定性基础设施约束 |
| 失败恢复 | 预定义 fallback 边 | 经常陷入无限循环 | 检查模型每轮评估,超限自动停止 |
| 可预测性 | 高(可审计每一步) | 低(每次运行路径不同) | 中(路径不可预测,但边界可预测) |
| 开发成本 | 高(维护 DAG 拓扑) | 低(只需写目标) | 中(定义围栏 + 目标) |
| 适用场景 | 确定性流程、合规要求高 | 原型验证、探索性任务 | 复杂但可约束的任务 |
注意,这不是「一个比一个好」的关系。每种范式都有它的最佳适用场景:
- 你的任务是数据处理管道,每一步都是确定的 → 用 LangGraph 画 DAG,这是正确的工具
- 你在做研究性探索,没有明确的步骤,也不需要生产级可靠性 → AutoGPT 式的纯 Goal-driven 可以接受
- 你的任务复杂且有不确定性,但有明确的安全边界和成本要求 → 有界自治是正确的选择
真正的问题是:大多数团队在用 DAG 做本应使用有界自治的事情。 他们花大量时间维护复杂的 DAG 拓扑,本质上是在编码时预测运行时的所有可能性——而这恰恰是 Agent 应该做的事。
有人可能会反驳:「预定义 DAG 保证确定性和可审计性,企业合规必须如此——你不能让 Agent 自主决定怎么处理用户数据。」这个担忧完全合理。但有界自治的回应是: 约束放在任务边界层面,而非执行路径层面。这就像公司的财务制度——审批流程是固定的(这是约束),但每个部门怎么花预算是自治的(这是执行)。合规检查可以作为围栏的硬编码部分(「不得访问 PII 数据」「每步记录审计日志」),而 Agent 在这些约束之内的决策自由度,恰恰是它比 DAG 更擅长处理不确定性场景的原因。
从 DAG 到 Goal 的迁移路径
如果你的系统目前完全基于预定义 DAG,想要逐步引入 Goal-driven 的能力,我建议分三步走:
第一步:识别 DAG 中的「伪确定性」节点。
你的 DAG 里一定有这种节点:开发者写了一个 if-else 分支来处理某种不确定性,但分支条件写得极其粗糙,覆盖不了真实场景。这些节点就是应该交给 Agent 自主决策的地方。
第二步:把这些节点替换为 Goal + 围栏。
不是把整个 DAG 扔掉,而是把「伪确定性」节点替换成一个有界自治的子 Agent。DAG 的整体结构保留(提供可预测性),但关键节点内部让 Agent 自主决策(提供灵活性)。
[DAG 节点A] → [子 Agent:Goal + 围栏] → [DAG 节点C]
↓ (超时/超限)
[DAG fallback 节点]
第三步:逐步放宽 DAG 约束,扩大 Agent 自治范围。
随着你对 Agent 决策质量的信心增加,逐步把更多的 DAG 节点替换为 Goal-driven 的子 Agent。最终,DAG 退化为只保留安全围栏和关键检查点——这就是成熟的有界自治系统。
OpenAI 的框架演进路径恰好印证了这一点:从 Swarm(教育性质的轻量级 handoff 框架)到 Agents SDK(生产级的 Agent 协作框架),核心转变就是从「预定义交互模式」走向「Agent 自主 handoff」。
一个反直觉的结论
回到文章开头的问题:用 Goal 取代 Graph,可行吗?
答案是: 不是取代,而是分层。
底层是 Goal——定义做什么、不做什么、完成的标志是什么。这一层是 Agent 的自治领域。
外层是 Graph——但不是执行路径的 Graph,而是约束和检查点的 Graph。预算上限、权限边界、审计日志、超时熔断。这一层是确定性的、可审计的、不依赖 AI 的。
DAG 不应该告诉 Agent「怎么走」,而应该告诉 Agent「哪里不能去」。
这个思维转换的意义可能比技术选型更大。它本质上是在说:我们对 AI 的信任模型应该从「白名单」(只允许做预定义的事)转向「黑名单」(禁止做明确不允许的事,其余自由发挥)。
前者适合 AI 能力不够强的时代。后者,在 2026 年的今天,可能是正确的赌注。
你的多智能体系统,还在画 DAG 吗?欢迎留言讨论。