周三晚上 9 点,供应链主管小林在钉钉里收到一条告警:「供应商 A 本周交货延迟率从 3% 升至 12%」。他看了一眼,回了句「知道了,季节性波动,不用管」。这条消息随即被淹没在后续 200 条群聊里。
两个月后,另一个团队的采购经理在审批供应商 A 的新合同时,完全不知道这段历史。合同正常通过。三个月后,供应商 A 果然出了大问题——产能不足导致全线延迟。
这个故事里, 信息是存在的——告警推了,人判断了,反馈也有了。但信息在人与人之间断裂了。小林的处理经验没有被结构化地沉淀下来,后来的决策者无从获取。
这正是大多数企业 AI 落地时撞上的第一堵墙: 不是 AI 不够聪明,而是企业的「神经系统」还没建好。
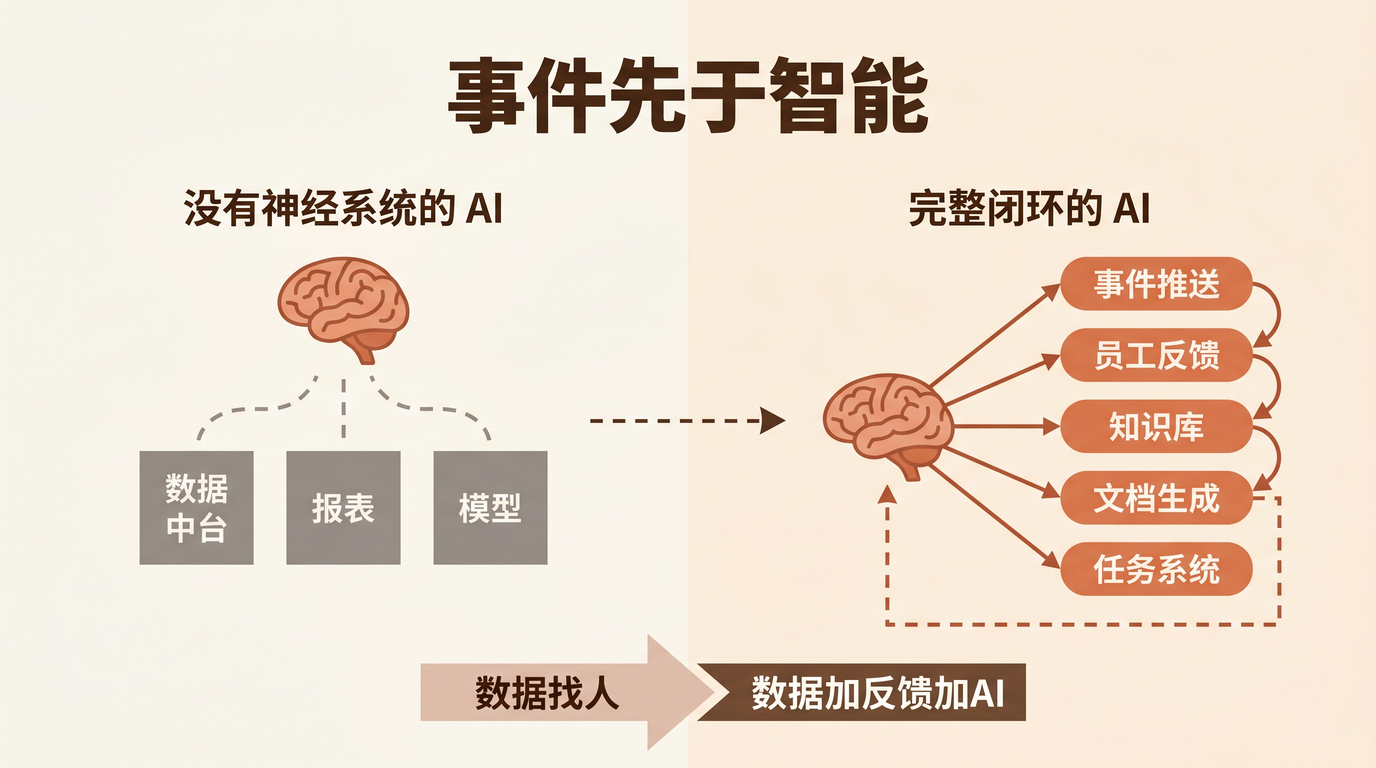
一、数据中台不等于 AI Ready
过去五年,几乎每家有点规模的企业都建了数据中台。数仓、实时计算、BI 看板——基础设施确实有了。但数据中台解决的是「 数据可见性 」问题:让人能看到数据。它没有解决「 数据可行动性 」问题:让系统(包括 AI)能基于数据自动行动。
区别在哪?
| 维度 | 数据中台 | AI Ready 的数据基础设施 |
|---|---|---|
| 数据消费者 | 人(看报表) | 人 + AI Agent |
| 数据形态 | 静态表/报表 | 结构化事件流 |
| 触发方式 | 人主动查询 | 事件主动推送 |
| 反馈机制 | 无 | 闭环(人反馈 → 知识库) |
| 因果关系 | 无(只有相关性) | 有(事件拓扑) |
我在 AI 时代的企业数字化 = 工作 Agent 化 + 知识 AI Ready 化 + 软件 CLI 化 里提过,知识 AI Ready 化是企业转型的三个支柱之一。但「AI Ready」具体怎么落地?很多人理解成「把文档灌进向量数据库」。这只做对了最表面的一步。
真正的 AI Ready,是让业务数据变成 可被 AI 消费的事件流,并且这些事件之间有拓扑关系——AI 能沿着因果链做推理,而不是在孤立的数据点上做单点判断。
二、先把事件推起来——用规则,不用等 AI
一个常见的误区:要搞 AI 驱动的工作流,得先把模型训练好。
恰恰相反。 在 AI Ready 之前,先用传统的规则引擎把业务关键指标、关键流程节点状态,通过 IM 和邮件通道推出去。 这一步不需要任何 AI 能力,但它做的事情极其重要——构建企业的「感觉器官」。
回到小林的故事。数据中台里已经有供应商 A 的交货数据,但如果没有规则引擎把它变成一条告警推送到小林的 IM 里,这条数据就静静地躺在数仓里,等着有人想起来去查。
规则引擎做的事很简单:
IF 供应商.交货延迟率 > 10% AND 环比上升 > 5pp:
PUSH 告警 TO 供应链主管.钉钉
但这简单的一步,把数据的消费模式从「人找数据」变成了「数据找人」。
事件推送的三个层次
不是所有推送都同等重要。我在实践中观察到三个递进层次:
第一层:原始指标告警。 某个指标超阈值,推一条消息。最基础,但噪音大。
第二层:关联事件推送。 不仅推指标本身,还推相关上下文——这个供应商上个月的延迟率是多少?同行业其他供应商的情况如何?这条规则是谁设的、什么时候设的?上下文越丰富,人做判断的效率越高。
第三层:跨流程事件推送。 事件之间有拓扑关系。供应商 A 延迟率上升 → 自动关联到正在审批中的供应商 A 合同 → 推给审批人。这层最难做,但价值也最大。
大多数企业卡在第一层和第二层之间——告警推了,但推得太碎、太孤立,人处理不过来,最终麻木了。
为什么不直接上 ML 异常检测?
有人会问:既然最终目标是智能化,为什么还要先建规则引擎?直接用机器学习做异常检测不是更好?
这个想法忽略了一个关键事实: ML 异常检测需要训练数据,而训练数据恰恰是规则引擎运行过程中产生的。 没有规则引擎先跑几个月,你不知道哪些告警被人工确认为真异常、哪些被标记为误报。这些标记就是 ML 模型最需要的训练标签。
而且,规则引擎的价值不仅是「过渡」。它提供了一个 deterministic 的基线——你可以精确知道某条告警为什么被触发(阈值是多少、条件是什么)。当 ML 模型给出一个「异常分数 0.87」时,你没法向业务方解释为什么。规则引擎和 ML 不是替代关系,是互补关系:规则负责可解释性,ML 负责发现规则覆盖不到的模式。
所以正确的路径是: 先让规则引擎跑起来,积累标注数据,再渐进地引入 ML 做增强。 跳过第一步直接上 ML,等于在没有地基的情况下盖楼。
三、员工反馈——闭环中最容易被忽略的一步
事件推给员工了,然后呢?
大多数团队觉得:推了就完了,人自己处理就好。但如果不把员工的处理结果和判断 结构化地回收,整条链路就是断的——AI 永远学不到人的决策逻辑。
还是小林的故事。他回了句「季节性波动,不用管」,这句话包含了关键信息:
- 意图:确认告警,但判定为无需行动
- 原因:季节性波动(领域知识)
- 关联实体:供应商 A、延迟率指标、季节性模式
如果这些信息被结构化地提取并存入知识库,后续的场景就完全不一样了。但问题在于——让员工填一个反馈表单?没人会干。 反馈的成本高于不反馈的成本时,人就沉默了。
这就是 LLM 带来的真正改变。不是让 AI 替代人做判断,而是让 AI 从人的自然语言回复中提取结构化知识:
from dataclasses import dataclass
from enum import Enum
from datetime import datetime
class FeedbackIntent(Enum):
CONFIRM_NO_ACTION = "confirm_no_action" # 确认但无需行动
CONFIRM_ACTION = "confirm_action" # 确认并已处理
REJECT_FALSE_POSITIVE = "reject_false_positive" # 误报
ESCALATE = "escalate" # 需要升级处理
SUPPLEMENT_CONTEXT = "supplement_context" # 补充上下文
@dataclass
class StructuredFeedback:
alert_id: str
intent: FeedbackIntent
reason: str
related_entities: list[str]
confidence: float
source_message: str
timestamp: datetime
user_id: str
def extract_feedback(
llm_response: dict, alert_id: str, user_id: str
) -> StructuredFeedback:
"""从 LLM 结构化输出中提取反馈。
LLM 负责理解自然语言回复并输出 JSON,
这个函数负责校验和标准化。
"""
intent_map = {
"无需处理": FeedbackIntent.CONFIRM_NO_ACTION,
"已处理": FeedbackIntent.CONFIRM_ACTION,
"误报": FeedbackIntent.REJECT_FALSE_POSITIVE,
"需要协助": FeedbackIntent.ESCALATE,
"补充信息": FeedbackIntent.SUPPLEMENT_CONTEXT,
}
raw_intent = llm_response.get("intent", "")
intent = intent_map.get(raw_intent, FeedbackIntent.SUPPLEMENT_CONTEXT)
return StructuredFeedback(
alert_id=alert_id,
intent=intent,
reason=llm_response.get("reason", ""),
related_entities=llm_response.get("entities", []),
confidence=llm_response.get("confidence", 0.5),
source_message=llm_response.get("original_text", ""),
timestamp=datetime.now(),
user_id=user_id,
)
# generated by hugo AI
关键是: 员工在 IM 里正常回复就好,不需要做任何额外动作。 LLM 在后台把非结构化的回复变成结构化的知识条目。
知识库的衰减管理
把反馈写进知识库只是第一步。更致命的问题是: 写进去的知识会过期。
小林说「季节性波动,不用管」,这个判断在夏天是对的,到了年底旺季可能就不成立了。如果知识库里这条一直在,AI 就会学到一个过时的判断。
所以知识库需要设计衰减机制:
| 维度 | 策略 |
|---|---|
| 时效性 | 每条知识带置信度,随时间衰减 |
| 冲突检测 | 新反馈和旧知识矛盾时,标记而不是覆盖 |
| 来源权重 | 同一指标,领域专家的反馈权重高于普通员工 |
| 验证回路 | 定期用历史 case 跑一遍知识库,看命中率和准确率 |
这和传统文档管理系统的根本区别在于:文档是静态的,而基于反馈闭环的知识库是 活的——它随着业务变化和人的判断不断演进。关于知识库怎么从「文档」变成「可查询的数据」,我在 知识库编译查询:让 AI 从「读文档」变成「查数据」 里有更详细的技术讨论。
四、文档生成——知识库价值的最直接出口
知识库建好了,反馈闭环跑起来了,接下来最自然的事: 让 Agent 基于知识库自动生成日常文档——日报、周报、方案、汇报。
这不是「让 AI 帮你写东西」那种浅层应用。真正的价值在于,Agent 能交叉引用知识库里的结构化数据,生成人写不出来的深度内容。
日报:从回忆到确认
传统日报最大的问题是 遗忘——下午做的事记得,上午的忘了。Agent 基于事件流生成日报,不会遗漏。
它还能自动关联上下文:你处理了告警 A,而告警 A 恰好是上周张三反馈过的规则误报——Agent 能写出有因果关系的日报,而不是流水账。人的角色从「写作者」变成「审核者」,花 2 分钟扫一遍 Agent 标记了低置信度的部分就好。
周报:从凑篇幅到结构化复盘
周报和日报的本质区别不是时间跨度,是 抽象层级。日报记事实,周报要提炼趋势和问题。
Agent 能做到一件人很难做到的事——纵向模式识别:
「本周告警推送量 47 条,较上周(62 条)下降 24%。其中规则 X 的误报反馈连续两周下降,说明 5/12 的阈值调整生效。但规则 Y 的反馈率从 15% 降到 3%,建议关注是否存在告警疲劳。」
这段话不是从某个单一数据源能写出来的——它需要 规则知识库 (阈值调整历史)+ 反馈知识库 (反馈率趋势)+ 事件统计 的交叉分析。在 AI 原生周报:从「周五补作业」到「数据自然长出来」 里,我用 War Room Scrum 的完整案例演示了这种数据聚合的具体实现。
方案:80% 是已有知识的重新组合
一个好的技术方案,80% 是已有知识的重新组合,20% 是创新。知识库让 Agent 能自动关联历史经验:
回到供应商延迟的问题。如果团队要写一个「智能告警降噪方案」,Agent 可以从知识库中提取:
- 过去 6 个月的告警反馈数据(哪些是误报,误报原因分类)
- 团队过去讨论过的类似方案(哪怕只是 IM 里的讨论片段)
- 当前系统架构和技术栈约束
然后按问题分类匹配已知解决模式——季节性波动用自适应阈值,关联条件缺失用关联规则引擎,时间窗口过短用多窗口聚合。方案不再是拍脑袋,而是 有据可查的决策链。
汇报:按受众调整抽象层级
汇报和方案的区别: 受众不同,需要讲故事。Agent 可以基于同一套知识库,按不同受众调整输出。给 VP 的汇报侧重 ROI 和趋势数据,给技术团队的方案侧重实现细节和风险评估。
而且 Agent 可以记住受众的偏好——VP 上次追问了交付延迟的具体数字,这次汇报里就自动把相关数据前置。
五、任务系统——闭环的最后一块拼图
前面讨论的事件推送(告警、指标异常)是 反应式 的——系统感知到变化,推给你。而流程系统推送的任务是 计划式 的——它代表组织对你下一步行动的明确期望。
两类推送叠加在一起,Agent 就拥有了一个很完整的画面:
| 推送类型 | 来源 | 结构特征 | Agent 的价值 |
|---|---|---|---|
| 事件/告警 | 数据中台 + 规则引擎 | 触发式、有时间压力、需要判断 | 辅助决策 |
| 流程任务 | BPM/OA/项目系统 | 有状态机、有 SLA、有前后依赖 | 辅助执行 |
当任务推送和事件推送交叉
最有价值的时刻,是两类推送产生交叉的时候。
流程系统推送:「请在今天 18:00 前完成供应商 A 的合同审批」
×
事件系统推送:「供应商 A 的交货延迟率本周从 3% 升至 12%」
传统模式下,这两条消息分别到达员工的 IM,员工需要自己关联。但如果知识库把两条都收录了,Agent 可以主动干预:
「你有一个待审批的供应商 A 合同,但本周该供应商交货延迟率异常上升(3% → 12%)。建议暂缓审批,先确认延迟原因。」
这才是 AI 工作流的真正价值——不是帮你写得更快,而是帮你想得更全。
任务状态机是 Agent 的行动框架
流程系统里的任务天然有状态流转(待处理 → 处理中 → 待审核 → 已完成),Agent 知道每个任务现在在哪、下一步该去哪、卡在哪了。基于此可以做三件事:
智能催办。 不是无脑发「你有 N 个待办」,而是判断催了有没有用——如果任务被上游阻塞,催当前负责人毫无意义,应该催上游。如果用户正在处理更紧急的事,延迟催办。
优先级编排。 不是基于「谁催得紧」,而是基于流程拓扑——谁在等你,你卡住了谁。Agent 能发现「需求评审」任务有 3 个人在等你排期、已经等了 2 天,这比一封催办邮件更有说服力。
流程健康度诊断。 知识库积累足够多后,Agent 能学到:张三处理「合同审批」平均 4 小时(团队均值 8 小时),李四最近处理「需求评审」变慢了(从 1 天变成 3 天),跨部门协作任务平均延期 2 天。这些 pattern 让 Agent 在任务超期之前就能预警。
六、完整的闭环
把这五层连起来看:
┌─────────────────────────────────────────────────────────┐
│ 员工工作界面(IM) │
│ │
│ ┌───────────┐ ┌───────────┐ ┌───────────┐ │
│ │ 事件推送 │ │ 任务推送 │ │ Agent 建议 │ │
│ │ (数据中台) │ │ (流程系统) │ │ (知识库) │ │
│ └─────┬─────┘ └─────┬─────┘ └─────┬─────┘ │
│ │ │ │ │
│ └──────┬───────┘ │ │
│ ↓ │ │
│ 员工行动 + 反馈 ←──────────────┘ │
│ │ │
│ ↓ │
│ 结构化提取 → 知识库 ←──────────────────┐ │
│ │ │ │
│ ↓ │ │
│ Agent 学习 → 更精准的推送/建议 ────────┘ │
│ │
│ ↓ 自动生成 ↓ │
│ 日报 · 周报 · 方案 · 汇报 │
│ │
└─────────────────────────────────────────────────────────┘
这个飞轮能不能转起来,核心度量不是知识库有多大,而是 反馈率 和 反馈后的改善感知。员工反馈了两次,发现推送质量没有改善,就不会再反馈了。闭环就断了。
所以第一步不是建知识库,不是训模型,而是: 先把事件推起来,让员工感受到反馈有用。
七、流程系统和真实行为之间的 gap
技术上这套架构已经可行。真正的障碍在组织层面: 流程系统定义的任务和员工的实际工作经常有偏差。
- 流程系统里任务状态是「处理中」,但员工已经做完了,忘了更新
- 员工做了很多「流程外」的工作——帮同事排查问题、临时响应——这些在流程系统里不可见
- 流程系统定义的 SLA 不合理,员工实际按自己的优先级在排
这些偏差如果不解决,Agent 基于流程系统做的判断就会和员工的实际体感脱节,员工就不信任 Agent 的建议。
解决方式还是反馈闭环。员工可以纠正 Agent 的判断——「这个任务我已经线下处理了」「这个优先级不对,实际应该先做 XX」——这些纠正回流到知识库,Agent 逐渐学会组织的「隐性规则」。
说到底, 流程系统是组织的「显性意图」,员工的实际行为是「隐性现实」,AI 的价值就是不断缩小这两者之间的 gap。 这和 企业知识库新范式:从一亿预算到人在回路 里的核心观点一脉相承——知识不是建出来的,是在人的日常工作中长出来的。
最后的问题
大多数企业的 AI 战略是这样的:先选模型、再找场景、然后做 POC。但这篇文章想说的是另一个顺序: 先把事件基础设施建好,把反馈闭环跑通,AI 能力会从数据中自然生长出来。
事件推送不是 AI 时代之前的过渡方案,它是 AI 工作流的地基。没有感觉器官的大脑,再聪明也没用。
你在企业里推 AI 工作流时,是先从模型侧切入还是从事件基础设施切入?踩过什么坑?欢迎留言讨论。