上周五晚上,一个做 RPA 的朋友跟我吐槽:他们给某电商平台搭的自动化流程,上线三个月,页面改版了两次,每次改版都要派人重新录制操作、调整元素定位、测试回归。「甲方觉得 AI 这么火,为什么你们的机器人还是这么脆弱?」
这个问题问得好,但答案可能不是他期望的。
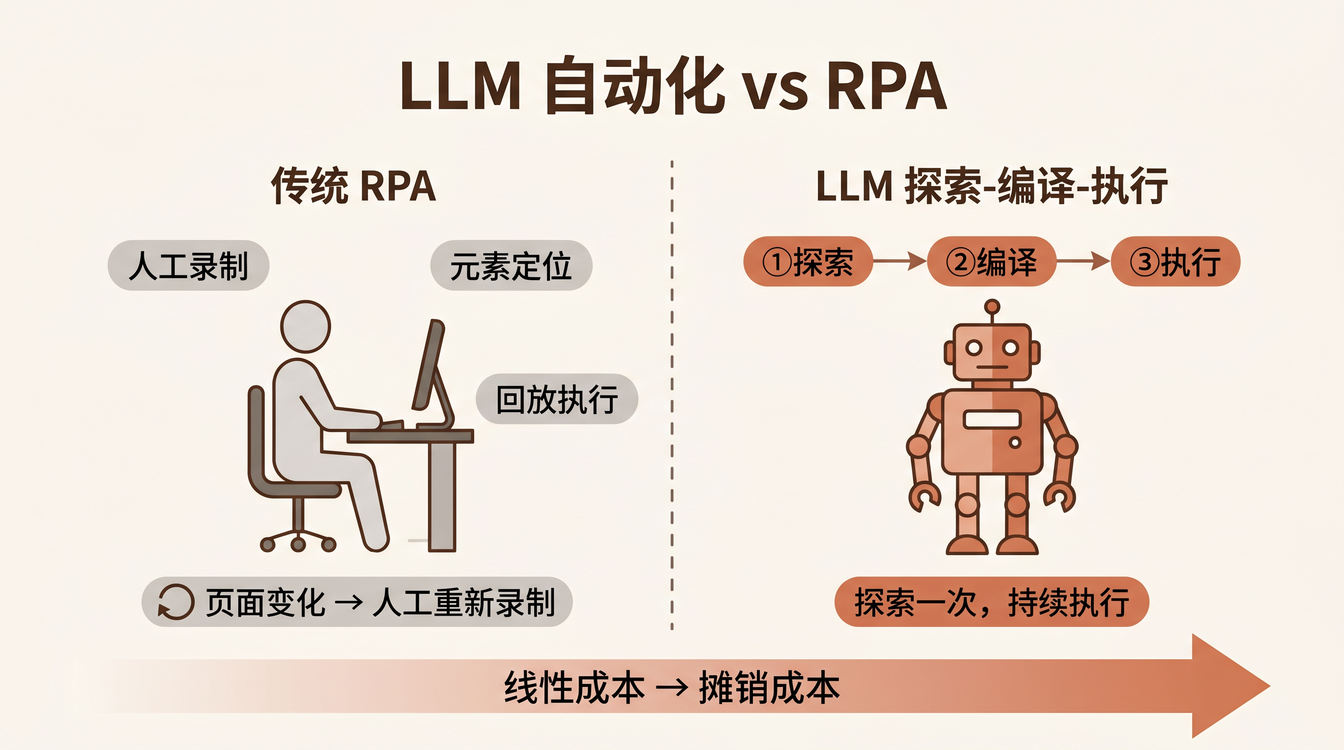
脆弱的不是 AI,是 每次页面变化都要人工重新编排 这个工作模式。影刀、UiPath 这类传统 RPA 工具,本质上是人工录制 + 元素定位的自动化回放。它的优势是稳定——录制好的流程跑一千次都不会出错。它的劣势也很明显——页面改了,流程就废了,而修复的成本和第一次录制一样高。
大模型的 Computer-Use 和 Browser-Use 走了一条完全不同的路,但大多数人只看到了它「贵」和「慢」的一面,没看到它真正值钱的地方。
一、两种自动化的本质区别
先把问题说清楚。
传统 RPA 的成本结构:人工编排成本高,执行成本低,维护成本高。
人工录制 → 元素定位 → 回放执行 → 页面变化 → 人工重新录制
↑ │
└──────────────── 循环 ─────────────────────────┘
每次页面变化,修复成本 ≈ 首次编排成本。这是一个 线性成本模型——你编排了 N 次,就付了 N 次人工成本。
LLM Computer-Use 的成本结构 (如果每次都推理):推理成本高,执行成本也高,但不需要人工编排。
LLM 观察页面 → 推理下一步动作 → 执行 → 观察结果 → 继续推理
这个模式的问题是 每次执行都在烧 token。一个需要 30 步操作的流程,每步消耗数千 token(基于 GPT-4o 级别模型的经验估算),跑一次就是几万 token。跑一百次,成本就上天了。
所以,大多数人对 LLM 自动化的印象是:比 RPA 灵活,但贵得离谱,慢得要死。
这个印象 只对了一半。
二、真正的杀手模式:探索一次,编译成代码
如果你仔细观察 Claude Code、Cursor 这类 AI 编码工具的工作方式,会发现一个模式:
- AI 先理解任务,探索代码库,尝试不同方案
- 找到可行路径后,生成最终代码
- 后续执行直接跑代码,不再重新推理
这个模式完全可以迁移到 UI 自动化领域。事实上,我在 压缩即智能 中讨论过一个类似的思路——AI 的价值不在于每次都从零推理,而在于把探索过程 压缩 成可复用的结构。LLM 把一次 UI 探索的完整推理链,压缩成几十行代码或一段精炼指令,后续执行不再需要重新推理。这就是智能的压缩。
┌─────────────────────────────────────────────────────────────┐
│ 探索-编译-执行 三层架构 │
├─────────────┬───────────────┬───────────────────────────────┤
│ 探索层 │ 编译层 │ 执行层 │
│ (一次性) │ (一次性) │ (持续) │
├─────────────┼───────────────┼───────────────────────────────┤
│ LLM 观察页面 │ 将成功路径 │ 纯代码执行 │
│ 尝试操作 │ 编译为代码 │ 或 小模型 + 指令执行 │
│ 找到可行路径 │ 或 精炼为指令 │ 失败时自动回退到探索层 │
├─────────────┼───────────────┼───────────────────────────────┤
│ 成本: 高 │ 成本: 低 │ 成本: 极低 │
│ Token 密集 │ 一次性转换 │ 零 Token 或极少 Token │
│ 耗时: 分钟级 │ 耗时: 秒级 │ 耗时: 毫秒级 │
└─────────────┴───────────────┴───────────────────────────────┘
这才是 LLM 自动化真正值得兴奋的地方——它省的不是「更智能」,而是 每次人工重新编排自动化流程的人力成本。增加的是 token 消耗,但 token 只在探索阶段大量消耗,后续执行阶段趋近于零。
成本模型从线性变成了摊销:
总成本 = 探索成本(一次性) + 执行成本(趋近零) × 执行次数
执行次数越多,单次成本越低。这和 RPA 的「N 次编排 × 固定成本」是完全不同的曲线。
三、鲁棒性的关键差异:自愈能力
传统 RPA 和 LLM 自动化在鲁棒性上的差异,很多人理解反了。
RPA 的稳定是 脆性稳定——正常运行时完美无缺,但一旦页面变化,就直接崩溃,必须人工介入。影刀这类工具虽然也有 AI 元素识别能力,但本质还是基于 DOM 选择器或图像匹配,页面结构一改就失效。
LLM 自动化的鲁棒性不在代码本身,而在 fallback 机制:
代码执行 → 成功?→ 结束
│
↓ 失败
LLM 局部修正(看当前页面,调整 1-2 步操作)→ 成功?→ 更新代码
│
↓ 多次修正仍失败
LLM 完整重新探索 → 生成新代码
这是一个 分层降级 的策略:
| 层级 | 触发条件 | 成本 | 耗时 |
|---|---|---|---|
| 代码直接执行 | 页面未变化 | 零 | 毫秒级 |
| LLM 局部修正 | 页面小改(按钮换位置、文案变化) | 低(几百 token) | 秒级 |
| LLM 完整重新探索 | 页面大改(流程重构、新系统上线) | 高(万级 token) | 分钟级 |
RPA 只有一层:要么全跑通,要么全挂。LLM 方案有三层缓冲,小问题自己修,大问题才重跑。
这才是鲁棒性的本质差异——不是代码更抗变化,而是系统有自愈能力。
四、三种落地深度:按场景选型
「探索-编译-执行」这个模式,根据投入深度有三种实现方式:
第一层:纯代码执行(最便宜,最脆弱)
LLM 探索完成后,直接生成 Python + Playwright/Selenium 代码。后续纯代码执行,连模型都不需要。
from playwright.sync_api import sync_playwright
# generated by hugo AI
def submit_order(page):
"""自动提交订单流程 — LLM 探索后生成的代码"""
page.click('[data-testid="add-to-cart"]')
page.wait_for_selector('[data-testid="checkout-btn"]')
page.click('[data-testid="checkout-btn"]')
page.fill('#address-input', '杭州市西湖区文三路 100 号')
page.click('button:has-text("确认订单")')
page.wait_for_url('**/order/confirm**')
# generated by hugo AI
适用场景:页面结构稳定、流程简单的内部系统。 缺点:CSS 选择器一变就挂,没有任何自适应能力。
第二层:小模型 + 指令执行(性价比最优)
大模型把探索结果总结成一段精炼指令,每次执行时把指令塞给本地小模型(7B 参数的视觉语言模型)当 system prompt。小模型按指令操作,同时具备基本的视觉理解能力来适应页面小变化。
# 大模型生成的执行指令(~200 token)
任务:在电商后台提交订单
步骤:
1. 点击页面上方的「购物车」图标(通常在右上角)
2. 确认商品列表后,点击「去结算」按钮
3. 在地址栏输入配送地址
4. 点击红色的「确认订单」按钮
注意:如果看到「库存不足」提示,停止操作并报告
小模型每次执行时读这段指令 + 看当前页面截图,决定具体操作。页面小变化它能自己适应(按钮从左边移到右边,它看得见),不需要重新探索。
适用场景:页面偶尔变化、任务类型固定的业务系统。 成本:本地推理,零云端 token 消耗。
第三层:蒸馏训练(一次性高投入,长期趋零)
大模型跑几百次探索,生成大量「页面状态 → 动作」的轨迹数据。用这些数据 fine-tune 本地小模型。小模型学到大模型的决策模式后,同类任务直接本地推理。
适用场景:高频执行、长期投入的核心业务流程。 成本:训练阶段高(几百到几千次大模型调用 + GPU 训练),之后趋近于零。
选型矩阵
| 维度 | 纯代码 | 小模型 + 指令 | 蒸馏训练 |
|---|---|---|---|
| 首次投入 | 低(1 次 LLM 调用) | 中(1 次 LLM + prompt 设计) | 高(数百次 LLM + 训练) |
| 执行成本 | 零 | 极低(本地推理) | 零 |
| 抗页面变化 | 无 | 中(小改自适应) | 高(学到决策模式) |
| 自愈能力 | 无(挂了需人工) | 有(fallback 到大模型) | 有(fallback 到大模型) |
| 适合场景 | 内部稳定系统 | 业务系统(月改几次) | 核心流程(日执行千次) |
五、成本对比的真正变量
很多人把「LLM vs RPA」简化成「token 成本 vs 人力成本」,这是错的。真正的变量是:
决策因子 = 页面变化频率 × 人工编排成本 ÷ token 消耗
- 高频变化的页面 (电商后台天天改版、SaaS 产品月更):LLM 方案碾压 RPA。页面改了,LLM 自动重新探索或局部修正,成本是一次 token 调用。RPA 需要派工程师重新录制,成本是一天人力。
- 稳定的内部系统 (ERP、OA、财务系统):RPA 够用,LLM 是过度工程。三年不改版的页面,你花 token 去「自适应」它,纯属浪费。
- 混合场景 (80% 稳定 + 20% 常变):这才是大多数企业的真实情况。用 RPA 覆盖稳定的 80%,用 LLM 方案处理常变的 20%。
还有一个常被忽略的成本: 迁移成本。影刀这类工具的壁垒不在技术本身,而在已有用户训练好的几千个流程。这些流程的迁移成本是真实的商业壁垒,和技术优劣无关。
六、一个更本质的类比
如果你把 LLM 自动化和 RPA 的关系往抽象了看,它和「解释型语言 vs 编译型语言」的关系很像:
- RPA 像预编译的二进制文件——跑得快、稳定,但改一行代码就要重新编译部署
- LLM 每次都推理,像纯解释执行——灵活,但每次都要重新解析
- 「探索-编译-执行」模式,像 JIT(Just-In-Time)编译——第一次运行慢(探索 + 编译),后续直接跑编译后的代码,遇到新情况才重新编译
JIT 之所以赢了纯解释和纯编译,就是因为它在两者之间找到了最优平衡点。LLM 自动化的「探索-编译-执行」模式,走的是同一条路。
写在最后
不要把 LLM Computer-Use 和 RPA 当成二选一的对手。它们是不同成本结构下的最优解,适合不同的场景。真正的机会在于理解这三层架构——代码、小模型、蒸馏——然后按场景组合使用。
需要诚实说的是,目前这个「探索-编译-执行」三层架构,更多还停留在架构思路和早期实践阶段。Anthropic 的 Computer-Use、OpenAI 的 Operator 目前仍以「每次推理」模式为主,完整的 explore-compile-execute 产品还在路上。但方向是清晰的——就像 JIT 编译器花了几十年才从论文走进 JVM,这条路的终点不会太远。
最值得投入的方向,不是追求一个「什么都能干」的通用 LLM Agent,而是为特定业务场景找到「探索一次、持续执行」的最佳平衡点。
你的业务系统里,哪些流程适合 RPA,哪些适合 LLM 方案?欢迎留言讨论。