上周,一个同事在悟空里问了一句「上周日活多少」,Agent 自信地返回了一个数字:精确到个位,格式漂亮,SQL 语法无懈可击。唯一的问题是——它用了一张已经废弃 3 个月的旧表。
没有人发现这个错误。因为数字「看起来对」。
这就是 Anthropic 在官方博客《How Anthropic Enables Self-Service Data Analytics with Claude》里描述的核心困境。我第一反应是「这不就是自然语言查数吗」。但读完全文,我发现自己错了——Anthropic 真正在做的,不是让业务人员用中文写 SQL,而是把整个数据工程的范式从「给人看」重构为「给 Agent 看」。
Anthropic 原文里最刺痛我的一句话是:
The initial elation of liberation from ad-hoc requests turns into dread with the realization that this setup separates stakeholders from the underlying infrastructure, documentation, and expertise that previously steered them toward carefully curated datasets.
翻译成大白话:你刚把 Claude 接上数据仓库,业务方欢呼终于不用找你写 SQL 了;但很快你会发现,他们问出来的问题越来越离谱,因为 Agent 失去了原来数据团队通过文档、培训、代码审查建立的「认知护栏」。
这不是技术问题,是 数据产品的用户变了。
传统自助分析的两大陷阱
Anthropic 开篇就点出了传统 BI 工具的困境:
陷阱一:宽表民主化。为了让非技术人员能用,数据团队把模型打平、去规范化,结果随着业务扩张,出现大量重叠视图和互相矛盾的定义。同一个「活跃用户」,市场部、产品部、财务部各有自己的算法。
陷阱二:隔离环境碎片化。另一种做法是给不同团队建独立的数据沙盒,结果是长尾问题没人管,指标和仪表盘膨胀成迷宫。
LLM 的出现似乎提供了一条新路:让 Claude 直接理解业务问题并生成 SQL。但 Anthropic 发现,这种做法会产生一种 虚假的精确感——Agent 能流畅地写出语法正确的 SQL,返回看似合理的数字,但你无法确定它用的是不是正确的表、正确的定义、正确的过滤条件。
把传统范式和 AI Native 范式放在一起看,差异是结构性的:
| 维度 | 传统 BI / 自助分析 | AI Native 数据分析 |
|---|---|---|
| 用户 | 人类分析师(有常识、会质疑) | Agent(无常识、不质疑、只执行) |
| 错误模式 | 人找不到数据 → 找同事问 | Agent 找到错误数据 → 自信返回错误答案 |
| 元数据角色 | 参考文档(人可看可不看) | API contract(Agent 的唯一导航依据) |
| 治理价值 | 统一口径(组织效率) | 降低搜索空间(准确率前提) |
| 文档维护动力 | 靠纪律和 review | 靠 CI 强制 + PR 联动(不更新就跑不过) |
| 历史查询价值 | 高(可直接复用) | 低(原始检索提升不到 1%,需提炼为模式) |
这不是给老方法贴新标签。核心区别在于:传统数据治理是「nice to have」——不治理也能凑合用;AI Native 治理是「must have」——不治理 Agent 就会以 95% 的置信度返回错误答案。
我在 Agent Model Plus Harness 里提过类似的观点:模型的能力只是冰山一角,真正的工程挑战在于 Harness 层如何约束模型的输出边界。数据分析场景下,这个 Harness 就是数据治理体系。
三个失败模式:为什么 95% 准确率这么难
Anthropic 的团队做了大量实验,发现大多数错误可以归因于三类失败模式:
1. 概念 / 实体歧义(Concept / Entity Ambiguity)
数据仓库里有成千上万个字段,当业务方问「上周的活跃用户数是多少」时,Agent 需要判断:
- 「活跃」指什么?登录?点击?完成核心动作?
- 是否排除测试账号、欺诈账号?
- 时间窗口怎么算?自然周还是滚动 7 天?
如果数据模型里有 40 个可能的「活跃用户」定义,Agent 选错的概率极高。
2. 数据过时(Data Staleness)
业务定义会变、Schema 会变、Pipeline 会挂。Agent 的知识一旦过时,就会返回微妙错误的结果——不是报错,而是给出一个「看起来对但实际上错」的数字。这种错误比直接失败更危险,因为它不会被察觉。
3. 检索失败(Retrieval Failure)
正确的信息可能就在数据模型里,也有完善的注释,但因为搜索空间太大,Agent 根本找不到它。这就像在一个没有索引的数据库里做全文搜索。
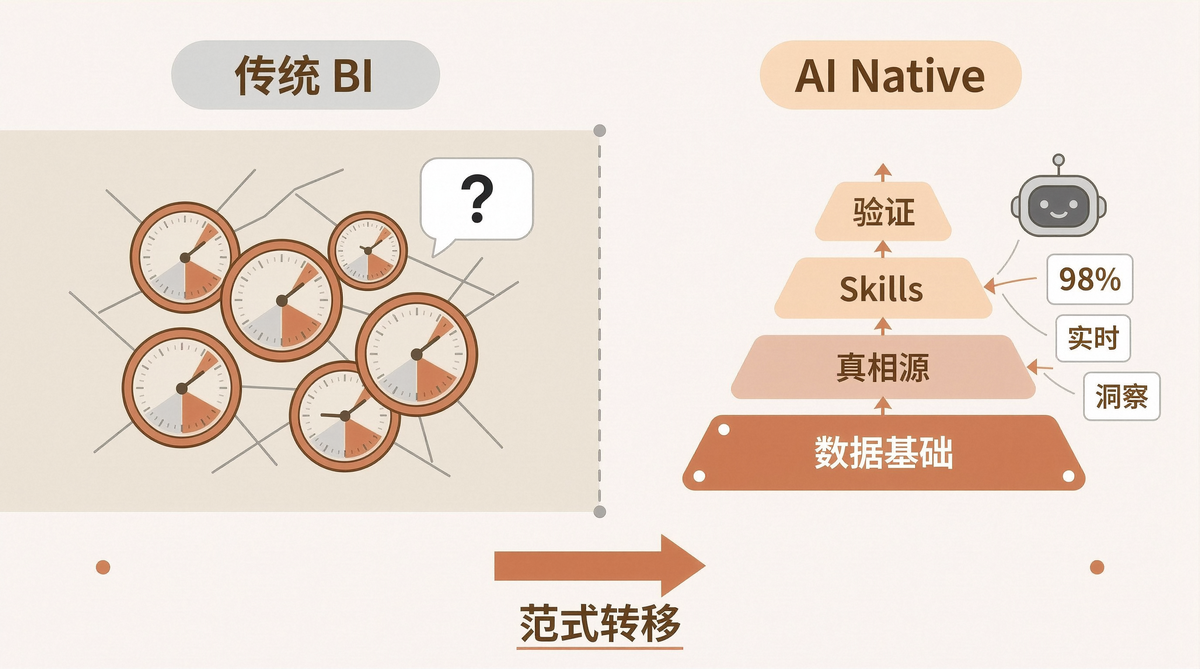
Anthropic 的解决方案不是换一个更强的模型,而是 缩小搜索空间 + 强化验证。他们的 agentic analytics stack 分四层,每一层针对一个或多个失败模式:
┌─────────────────────────────────────────┐
│ Validation (验证层) │
│ Offline evals + Online monitoring │
├─────────────────────────────────────────┤
│ Skills (技能层) │
│ Procedural knowledge: how to navigate │
├─────────────────────────────────────────┤
│ Sources of Truth (真相源层) │
│ Semantic layer, lineage, query corpus │
├─────────────────────────────────────────┤
│ Data Foundations (数据基础层) │
│ Canonical datasets, metadata as product│
└─────────────────────────────────────────┘
下面逐层拆解。
数据基础层:把元数据当成一等公民
这一层的目标是解决 概念歧义 和 数据过时。Anthropic 的做法很朴素,但执行起来需要极强的纪律性:
创建规范数据集(Canonical Datasets)
最常见的失败原因是 Agent 无法将业务概念映射到唯一正确的表和列。解决办法是: 少而精的逻辑模型。
- 维护一小套被明确拥有、消费就绪、可发现的规范数据集
- aggressively deprecate 近似重复的视图
- 物理汇总表和缓存应该从规范模型机械派生,而不是作为替代方案并存
目标是:当 Agent 搜索「revenue」时,只找到一个被治理的答案,而不是四十个候选。
强制执行标准
光有规范不够,还需要工具链强制路由到规范层:
- CI 检查:绕过规范层的变更无法通过审查
- 技能指令:Agent 被结构性要求优先使用语义层
- 组织 mandate:下游团队必须基于治理层构建,否则需要解释原因
我在 Evolvable Agent Skills Best Practices 里写过,Skills 的维护成本之所以高,是因为它们描述的是一个每天都在变的数据模型。Anthropic 的解法是把 Skill Markdown 文件和转换模型放在同一个 repo 里,这样修改模型的 PR 同时也是更新文档的 PR。大约 90% 的数据模型 PR 现在都包含 Skill 变更。
元数据即产品
代码 Agent 表现好,部分原因是代码库是可读的:README、类型签名、docstring。数据仓库也可以同样可读,前提是:
- 列和表的描述
- 规范指标定义
- 粒度文档
- 有效值范围
- 血缘关系
- 所有权
- 模型分层
这些元数据需要以和维护转换代码同样的严谨度来维护。好的治理提供了关键上下文,帮助 Agent 选择正确的数据集。
真相源层:把业务问题映射到受治理的实体
如果数据基础层是数据仓库本身,真相源层就是 Agent 用来导航它的参考表面。按信任度从高到低:
语义层(Semantic Layer)
编译后的指标和维度定义。如果一个问题能干净地映射到已定义的指标,Agent 调用函数就能得到一个数字——和公司其他表面产生的数字一致。
Anthropic 尝试过一个有趣但失败的方案:让 LLM 从原始表和查询日志中自动生成指标定义来引导语义层。结果是产生了看似合理但编码了我们试图消除的歧义的定义,在评估中反而不如小规模人工策划的层。 建议用 Claude 生成文档草稿,但让人类拥有定义的所有权。
血缘和转换图
当语义层覆盖不到某个问题时,血缘和表排名(基于引用次数)让 Agent 能够推理哪些上游模型支撑一个概念、哪些已废弃、哪些共享粒度。这把「我不知道这个指标」转化为「我知道该从哪个受治理的模型聚合」。
查询语料库
直觉上,历史 SQL(来自仪表盘、Notebook、过往分析)应该是高价值的——它是每个已被正确回答的问题的记录。但实践中,给 Agent 原始检索访问数千条历史查询,准确率提升不到 1 个百分点。非结构化检索无法将新问题映射到正确的先例。
真正有效的是:将语料库提炼成 **结构化的每领域参考文档 **和 Skills 中描述的可复用分析模式。把查询历史当作策展的原材料,而不是 Agent 直接读取的真相源。
业务上下文
这是大多数团队跳过、Anthropic 也低估最久的一层。不理解业务的 Agent 会回答用户问的,但不是用户想要的。它不知道「Q2 发布」指的是哪个具体产品,不知道两个团队对同一术语有不同定义,不知道这个问题被问出来是因为周四有董事会会议。
Anthropic 的做法是接入由公司文档、路线图、决策日志和组织结构组成的知识图谱,让 Agent 能够解析环境引用并提出更好的澄清问题。
Skills 层:从 21% 到 95% 的关键跃迁
如果真相源层是 Agent 的声明式知识(即指标的含义),那么 Skill 就是它的过程性知识:按什么顺序咨询哪些来源、如何导航模糊数据、finished analysis 长什么样。
在 Claude Code 中,Skill 是一个 Agent 按需读取的 Markdown 文件夹。Anthropic 的数据显示:
- 没有 Skills:准确率不超过 21%
- 有 Skills:总体准确率稳定在 95% 以上,某些领域达到 99%
这是一个数量级的提升。
Pairwise Skills 设计
Anthropic 采用两层 Skill 结构:
Knowledge Skill:作为薄顶层路由器,允许额外领域细节按需加载。它说「先试语义层,但如果没有覆盖,这里有 ~30 个参考文件描述相关表、列、连接和坑」。这本质上是对检索失败的回应:不让 Agent 搜索百万字段的仓库,而是先将空间缩小到几十个精心策划的文件。
Unbook Skill:编码高级分析师遵循的流程:澄清问题 → 查找来源(通过 Knowledge Skill)→ 运行查询 → 将结果循环通过对抗性审查子 Agent。它还捆绑了十几种可复用的分析模式(留存曲线、率分解、漏斗分析),这样常见请求不会每次都重新发明轮子。
参考文档的写法
为 LLM 检索而写的参考文档,结构如下:
# [Domain] Tables
## Quick Reference
### Business Context — [用通俗语言解释这个领域的含义]
### Entity Grain — [一行代表什么]
### Standard Hygiene Filter — [这个领域的每个查询都应用的过滤器]
## Dimensions
- [关键维度如何编码,以及同一概念在不同表中如何命名]
## Key Tables
### [table_name]
- **Grain**: [...] · **Scope/exclusions**: [...]
- **Usage**: [何时使用、何时不使用、连接键、必需过滤器]
## Gotchas
- [资深分析师会警告你的错误答案模式]
## Best Practices / Common Query Patterns
- [默认选择、标准切分、 worked patterns]
## Cross-References
- [拥有相邻问题的邻近领域文档]
关键点:描述表(粒度、范围、排除)、gotcha 的机制(例如「排除已知免费邮箱域名,但保留 anthropic.com 等自定义域名」)、显式的路由触发器(例如「IF 问题是关于实验提升… DO NOT 使用原始事件计数」),但不包含会过时的规定性配方。
验证层:离线评估 + 在线监控
最后,验证是发现哪类失败模式仍在泄漏的方式。
离线评估
Anthropic 部署两种离线评估:
- 基于仪表盘的评估:由 Claude 自动生成(然后人工验证),涵盖最常见的利益相关者问题
- 长尾评估:向 Claude 提供业务上下文(路线图、表文档),让它生成跨领域其余部分的合理问题
他们还持续收集每次利益相关者在对话中纠正 Agent 的情况,因为这些纠正是候选评估用例。
最佳实践包括:
- 锚定地面真值以防漂移:针对实时数据编写的评估会在底层数字变动时立即过时。将每个评估固定到快照日期、针对稳定的事实表编写,或让评分器评判 Agent 的查询而非其数字。将套件接入 CI,这样触及依赖项的 PR 会重新运行受影响的评估。
在线验证
离线评估告诉你是否有重大缺口,但不能告诉你在线 Agent 的表现。Anthropic 的做法是在线监控:
- 记录每个查询的置信度分数
- 当置信度低于阈值时,触发人工审查流程
- 将审查结果反馈回评估套件
So What:对数据团队的启示
读到这里,你可能会觉得 Anthropic 的方案太重。我先说一个我们在悟空上做过的小实验,证明这些思路不需要搬整套架构就能验证。
一个小实验:考勤域的参考文档
我们挑了考勤这一个数据域,按 Anthropic 的参考文档模板写了一份 Markdown:Quick Reference(业务上下文、实体粒度、标准过滤条件)、Key Tables(每张表的用途和坑)、Gotchas(「排除补卡未审批记录」等资深分析师才知道的陷阱)。总共不到 200 行。
然后让 Agent 回答同一组 10 个考勤分析问题:
| 指标 | 没有参考文档 | 有参考文档 |
|---|---|---|
| 表选择正确率 | 6/10 | 10/10 |
| 过滤条件正确率 | 4/10 | 9/10 |
| 最终答案正确率 | 5/10 | 9/10 |
| 平均耗时 | 38s | 22s |
最大的改善来自 Gotchas 部分。没有参考文档时,Agent 不知道「补卡申请未审批」的记录要从统计中排除——它直接 COUNT 了所有打卡记录。这正好对应 Anthropic 说的第一类失败模式:概念歧义。
200 行 Markdown,不需要语义层,不需要 eval 套件,就能让一个域的准确率从 50% 跳到 90%。这验证了 Anthropic 的核心判断: 问题不在模型能力,在搜索空间。
读完 Anthropic 的文章,我最深的感受是: 数据工程的最佳实践没有变,但受众变了。
以前,数据模型的用户是数据科学家或分析师,他们有能力理解 Schema、阅读文档、判断数字是否合理。现在,用户是 Agent——它们没有常识,不会质疑,只会执行。
这意味着:
- 元数据不再是文档,而是 API contract。Column description 不是给人看的备注,而是 Agent 选择字段的依据。
- 数据工程师的角色从「写转换」变成「设计 Agent 的认知边界」。你需要思考:如果我是 Agent,我会怎么理解这个表?我会犯什么错?
- 治理不是官僚主义,而是降低 Agent 的搜索空间。Canonical dataset 的价值不在于「统一口径」,而在于让 Agent 只有一个选项可选。
读到这里,最聪明的读者可能会问:「这不就是数据治理换了个 AI 的壳吗?Column description、canonical dataset、血缘关系——这些东西数据团队喊了十年了,有什么新东西?」
好问题。传统数据治理和 AI Native 数据工程的本质区别不在 做什么,而在 不做会怎样。
传统治理是效率问题:不写 column description,分析师多花 20 分钟找字段;不做 canonical dataset,两个团队报表对不上数。痛,但不致命。你可以一直拖着不做,业务照样跑。
AI Native 场景下,同样的疏忽变成了准确率问题:Agent 不读 description 就选字段,不做 canonical 就随机挑表。后果不是「效率低」,而是「以 95% 的置信度返回错误答案,而且没人发现」。上面那张对比表里的核心差异就在这里——治理从 nice to have 变成了 correctness 的前提条件。
所以这不是旧瓶装新酒。同样的最佳实践,当用户从人变成 Agent,激励结构彻底变了:以前治理靠人的纪律性(最不可靠的东西),现在治理靠工程约束(CI 检查、Skill 路由、eval 反馈),不做就过不了测试。这才是真正的范式转移。
我在 Agent Reinforcement Learning Best Practices 里写过,Agent 的持续优化依赖于高质量的反馈信号。在数据分析场景下,这个信号不仅来自用户的显式纠正,更来自离线评估和在线监控的系统化采集。
最后的升维问题
Anthropic 的方案看起来很重:规范数据集、语义层、Skills、离线评估、在线监控……小团队玩得起吗?
我的答案是: 重的不是方案,是方向错误的累积。
传统 BI 工具也在积累技术债——只是换了一种形式。宽表、孤立仪表盘、无人维护的指标定义,这些成本不会因为不用 AI 就消失。Anthropic 的做法是把隐性成本显性化,用工程手段管理它。
对小团队来说,核心启示不是照搬四层架构,而是记住一点: 在你让 Agent 查数之前,先确保你的数据模型是「可被 AI 理解」的。否则,你只是在加速生产错误答案。
如果明天就要动手,我会从这三步开始:
- 挑一个高频数据域,按 Anthropic 的参考文档模板写一份 Markdown。不需要语义层,不需要工具链,就是一个文件。上面考勤域的实验证明,200 行文档就能让准确率翻倍。
- 把这个文件和转换模型放在同一个 repo 里。改模型的 PR 必须同步更新文档——Anthropic 说他们 90% 的数据模型 PR 现在都包含 Skill 变更,这就是让文档不过时的工程约束。
- 建一个简单的 eval 集。从过去 30 天业务方问过的问题里挑 20 个,人工标注正确答案,跑一遍 Agent。这就是你的 baseline。以后每次改文档、改模型,都跑一遍看有没有回归。
这三步加起来,一个人一周能做完。它不是 Anthropic 的完整架构,但它验证了完整架构的每一个核心假设。
你在实际落地自助数据分析时遇到过什么坑?欢迎留言讨论。