上周我写了一篇 LLM 自动化 vs RPA:省的不是智能,是编排成本,提了一个「探索-编译-执行」的三层架构——LLM 先探索网页、找到可行路径,然后编译成代码,后续直接执行。
写完没几天,微软研究院发了 Webwright,几乎就是这套思路的学术验证。但让我意外的不是它验证了三层架构,而是另一个发现: harness 本身可以薄到离谱。
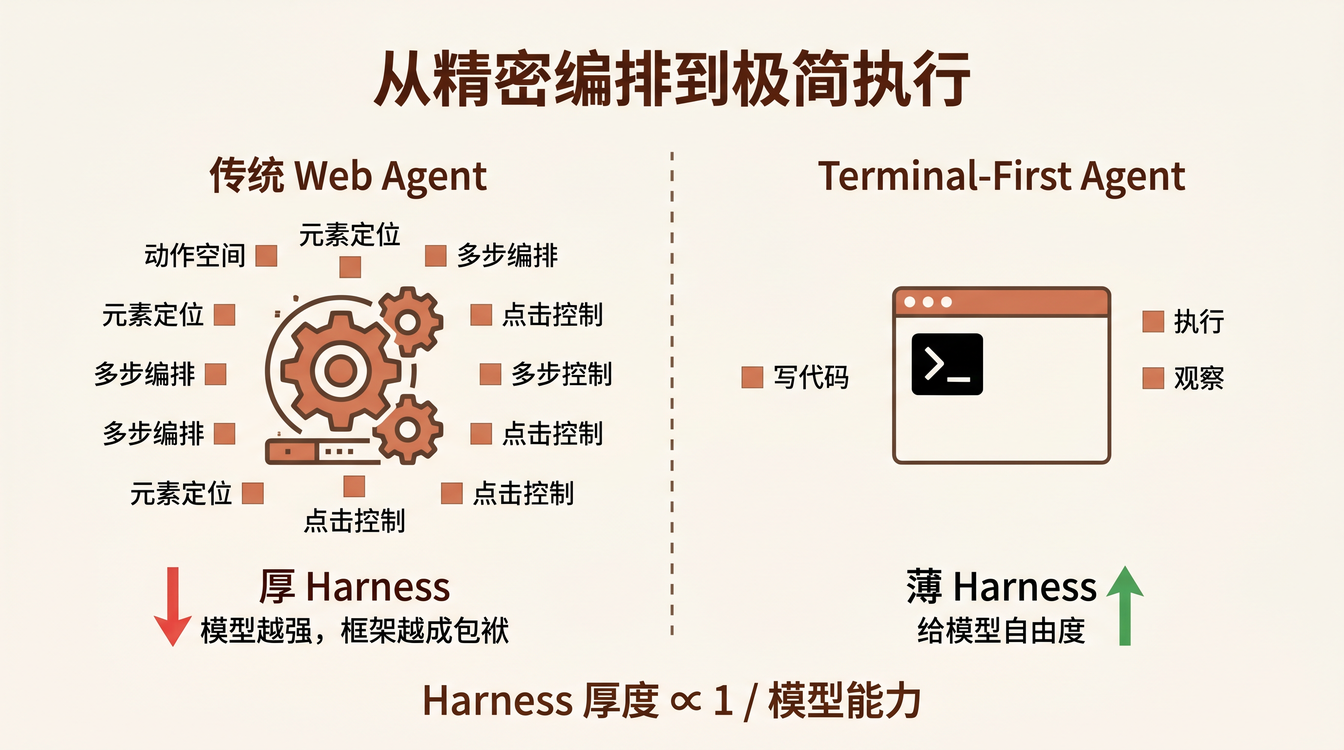
整个系统只有 ~1000 行代码,三个模块,没有 multi-agent 编排,没有复杂的动作空间设计。它给模型的东西只有一个——terminal。
一、Webwright 做对了什么
先说数据,再说道理。
微软团队做了一个极简的实验: 不给模型预定义的动作列表 (click、type、scroll 这些),只给它一个 bash terminal。模型想操作浏览器?自己写 Playwright 代码去。
结果在 Online-Mind2Web(300 个任务,136 个真实网站)上:
| 模型 | 准确率 | 平均步数 | 平均每任务成本 |
|---|---|---|---|
| GPT-5.4 (Webwright) | 86.67% | 26.3 | $2.37 |
| Claude Opus 4.7 | 84.7% | 21.9 | $6.09 |
| 上代 SOTA | ~75% | - | - |
在 Odysseys(200 个长链路、多网站任务)上更夸张:
| 方案 | 成功率 | 平均步数 |
|---|---|---|
| Webwright + GPT-5.4 | 60.1% | 76.1 |
| 上代 SOTA (Opus 4.6) | 44.5% | 81.3 |
| 基础 GPT-5.4 (截图+坐标) | 33.5% | - |
比上代 SOTA 高了 35 个百分点,比基础模型高了将近一倍。
这不是「稍微好一点」,这是范式级别的差距。
二、为什么「少即是多」成立
微软论文里有一句话我觉得值得单独拎出来:
As model capabilities improve, heavily engineered web agent harnesses become less helpful and more constraining.
翻译成人话: 模型越来越强,你精心设计的框架反而在拖后腿。
这反直觉,但想清楚后很合理。传统 Web Agent 框架做的事是什么?
传统框架:
模型 → 动作空间(click/type/scroll/select)→ 元素定位 → 执行
↑
这里每一步都是约束
你给模型一个 click(element_id) 的 API,模型就只能一个一个点。你给它一个 terminal,它可以写一个 for 循环批量处理,可以开三个 browser session 并行抓取,可以先截图分析再操作——它的自由度从「在你定义的菜单里选」变成了「你想怎么干就怎么干」。
这和编程语言的演化是同一个道理。汇编语言给了你精确到字节的控制力,但没人愿意用它写 Web 应用。高级语言牺牲了底层控制力,换来了生产力。Web Agent 的 harness 也在经历同样的抽象层次提升——从「精确控制每一步点击」到「给模型一个 terminal 让它自己写代码」。
关键工程细节
Webwright 不是「给个 terminal 就完了」那么简单,它解决了两个实际问题:
问题一:模型过早喊「完成」
模型有时做到一半觉得差不多了,就输出 done: true。Webwright 的解法是加了一个 self-reflection gate——模型必须先写一个验证脚本,在干净环境里跑一遍自己的结果,通过验证才能结束。过不了就继续干。
问题二:上下文爆炸
长任务写到后面,代码历史太长,超出 context window。Webwright 每 20 步压缩一次历史,把中间过程总结成一段摘要,只保留关键信息。
这两个都不是什么高深技术,但解决的是真实痛点。harness 薄不代表没有工程,而是 工程用在刀刃上。
三、autocli:编译产物的另一个极端
如果说 Webwright 证明了「探索层可以极简」,那 autocli 展示的是「编译产物可以极轻」。
autocli 的玩法完全不同:它不是让模型实时写代码操作浏览器,而是 一次性生成一个 YAML adapter,之后所有数据提取都走这个静态配置。
# 第一次:AI 生成 adapter
autocli generate https://example.com --goal 'list' --ai
# 之后:直接调用,零 LLM 开销
autocli example list
# 输出结构化 JSON
它覆盖了 300+ 网站,每个网站有若干 command adapter。小红书、飞书、微信公众号、Twitter 都有。你跑一条命令就拿到结构化数据,不需要启动浏览器、不需要推理、不需要 token。
autocli 本质上是我上一篇说的「编译层」的一个极致实现——LLM 的探索结果被编译成一个轻量 YAML 文件,后续执行完全是确定性的。
把它和 Webwright 放在一起看:
| 维度 | Webwright | autocli |
|---|---|---|
| 核心目标 | 完成 web 任务 (填表、提交、多步流程) | 提取数据 (网页→结构化输出) |
| 执行方式 | 动态 agent loop(写代码→执行→观察→继续) | 静态 adapter(生成后直接调用) |
| 运行时依赖 | Playwright + LLM | 无 LLM,纯配置 |
| 自适应能力 | 高(页面变了重新探索) | 低(adapter 失效需重新生成) |
| 适合场景 | 复杂、有状态、多步骤的 web 任务 | 确定性的数据抓取和信息提取 |
两者不是竞品,是同一光谱的两端: Webwright 偏「探索」,autocli 偏「编译」。真实世界的大多数场景需要两者组合——用 autocli 这类工具做高频数据提取,用 Webwright 这类方案处理需要交互的复杂流程。
四、Harness 厚度的选择
不是所有场景都该用 terminal。我把 Web Agent 的 harness 按「厚度」排个序:
厚 ←─────────────────────────────────────────────────→ 薄
Multi-Agent 单 Agent + Agent + Terminal
编排框架 动作空间 Terminal Only
(BrowserUse, (click/type/ (Webwright (给模型 bash
Agent-T) scroll API) 模式) 让它自己写)
← 更多控制、更少自由度 更多自由度、更少控制 →
怎么选?取决于两个变量:
| 场景 | 推荐厚度 | 理由 |
|---|---|---|
| 模型代码能力强 + 任务多变 | 薄 (Terminal) | 充分利用模型自由度,不浪费在动作空间设计上 |
| 模型代码能力弱 + 任务固定 | 厚 (动作空间) | 用框架约束降低出错概率 |
| 高频重复 + 页面稳定 | 最薄 (静态 adapter) | 连模型都不需要,autocli 式配置即走 |
| 低频 + 页面常变 | 薄 (Terminal + 自愈) | 页面变了重新探索,成本是一次 LLM 调用 |
这和上一篇的结论是一致的,但现在有了更具体的数据支撑——Webwright 证明了「薄 harness + 强模型」在真实 benchmark 上能赢,而且赢得很多。
五、一个反直觉的推论
如果 harness 应该越来越薄,那现在大量 Web Agent 框架在做什么?
坦白说, 很多框架在解决模型不够强时的问题。给模型预定义动作空间,是因为模型自己写代码不够靠谱。加 multi-agent 编排,是因为单个 agent 容易走偏。设计复杂的 step-by-step 控制流,是因为模型不知道该怎么规划。
这些都是合理的工程妥协——在模型能力不足的当下。
但模型能力在以月为单位提升。去年 GPT-4o 级别的模型写 Playwright 代码还经常出错,今年 GPT-5.4 已经能在 terminal 里自主完成 100 步的复杂 web 任务。Qwen-3.5-9B 这样的小模型,配合 crafted tools,在工具丰富的站点上也能跑出不错的结果。
这意味着今天的「最佳实践框架」很可能在半年后就是包袱。 你在框架上投入的工程越多,迁移成本越高。
一个务实的建议: 构建 Web Agent 时,优先选择最薄的 harness 能跑通的方案,把工程投入放在模型选择、prompt 设计和 fallback 机制上,而不是放在更复杂的编排框架上。
写在最后
Webwright 的论文标题叫「A Terminal Is All You Need For Web Agents」。这个标题本身就是态度——它不是 terminal 比 browser API 好 5% 的增量改进,而是在说 整个 harness 设计思路该换了。
从「精心设计动作空间让模型按步骤执行」到「给模型一个 terminal 让它自己决定怎么做」,这个转变的本质是: 把控制权从 harness 转移到模型。
当模型足够强,harness 的最优厚度趋近于零。
你在用哪些 Web Agent 工具?harness 是太厚了还是太薄了?欢迎留言讨论。