周一早上 9:30,一个 5 人 Scrum 团队的钉钉群里,AI 表格自动推送了一条晨会摘要:
📊 今日待办 7 项 (P0×2 / P1×3 / P2×2)
⚠️ 发现 3 个支付模块 bug 集中在支付网关,关联上周五 v2.3.1 发布。建议优先处理 #BUG-042,指派给 @张三(支付模块 owner)。
🔗 需求 #REQ-015 与 #BUG-039 存在依赖关系,建议先完成 bug 修复再启动需求开发。
工程师张三看到这条消息,点进 AI 表格,看到 AI 给出的修复方案:「参考支付网关 v2.3.0 的超时配置,建议在 PaymentClient.java:128 添加重试策略,预计 30 分钟」。他结合自己的经验判断,觉得方案基本靠谱,但超时时间应该更短。改了参数,40 分钟搞定。CI/CD 跑完,AI 表格自动更新状态,群里推送:
✅ BUG-042 已修复(张三,40 分钟)→ 已部署 staging
这不是假设。用钉钉 AI 表格 + 群沟通 + dws CLI,这个工作流的每个环节今天都能搭出来。下面拆解怎么搭。
一、Anthropic Skills 指南的一个关键洞察
最近读到一份 Anthropic 内部关于 Claude Code Skills 的使用指南,其中有一段话让我反复看了好几遍:
Product Verification 是最有影响力的 Skill 类别。模型会制造「完成幻觉」——必须在关键节点加程序化断言。
这段话放在 AI Agent 场景下很好理解:Agent 说「我完成了」不等于真完成了,你得验证。但如果把它放到团队协作场景下呢?
一个 Scrum 团队每天产生大量信息——bug 报告、需求讨论、代码提交、部署结果。这些信息散落在各个系统里,靠人工搬运和记忆串联。问题不在于团队成员不努力,而在于 信息在流转过程中不断丢失和失真。
Anthropic 指南还提到另一类高 ROI 的 Skill:「Library & API Reference」——不是教模型基础知识,而是记录团队特有的 gotcha。这给了一个启发:如果我们把整个 Scrum 团队的工作流看作一个 Skill,那 AI 表格就是它的结构化载体,dws CLI 就是它的执行引擎。
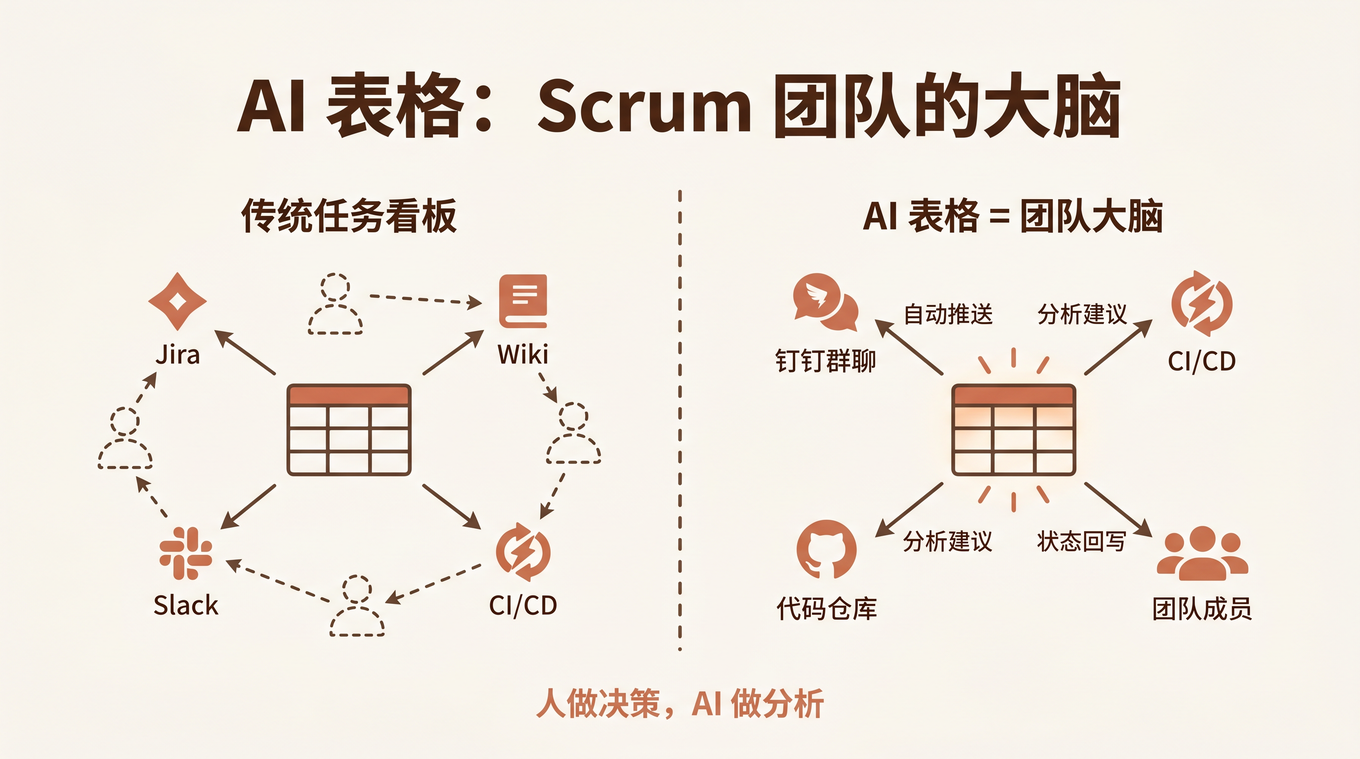
二、AI 表格不是任务看板,是团队的「工作记忆」
传统任务看板(Jira、Trello、Teambition)回答的问题是「有什么任务」。AI 表格能回答一个更深的问题:「这些任务意味着什么,以及下一步最该做什么」。
区别在哪?
| 维度 | 任务看板 | AI 表格 |
|---|---|---|
| 数据录入 | 人工填写 | 人工 + 自动(CI/CD 回调、群消息提取) |
| 数据分析 | 看统计图表 | AI 主动分析,给出建议 |
| 状态变更通知 | 人去看板查看 | 自动推送到群 |
| 上下文关联 | 手动链接 | AI 自动发现关联(同模块 bug、需求依赖) |
| 知识沉淀 | Wiki 另写 | 分析记录自动积累 |
我在 AI 原生周报:从「周五补作业」到「数据自然长出来」 里说过,周报不是「写」出来的,是「长」出来的。同样的逻辑适用于每日 Scrum:任务状态不应该靠人去更新,而应该从 CI/CD、代码提交、测试结果中自然长出来,AI 表格负责汇聚和分析。
举个具体例子。工程师在群里说「支付模块又超时了」,传统工作流下这句话沉在聊天记录里。AI 表格的工作流下,dws CLI 自动提取这条信息,关联到已有的 3 个支付 bug,AI 分析后推送:
⚠️ 支付超时问题再次出现(第 4 次),集中在支付网关模块,关联 v2.3.1 发布。根因可能是连接池配置。建议:@张三 优先排查
PaymentClient的超时配置。
工程师不用自己去翻数据,AI 已经把上下文铺好了。
三、工作流架构
先看全貌。整个系统围绕 AI 表格这个「大脑」展开,dws CLI 是连接各系统的桥梁:
┌──────────────────────────────────────────────────────────┐
│ 钉钉 AI 表格(大脑) │
│ │
│ 任务数据 ←→ AI 分析 ←→ 方案建议 ←→ 状态追踪 │
│ ↑ ↑ ↓ ↑ │
└─────┼───────────┼──────────┼───────────┼──────────────────┘
│ │ │ │
▼ │ ▼ │
dws aitable │ dws chat send │ CI/CD Webhook
(读写数据) │ (推送通知到群) │ (构建/部署回调)
│ │ │ │
▼ │ ▼ │
CI/CD 系统 │ 钉钉群沟通 │ 代码仓库
(构建/测试/ │ (讨论/决策/ │ (提交/MR/
部署) │ 确认) │ Review)
传统模式下,这几个系统之间的信息靠人肉搬运。AI 原生模式下,AI 表格是中心节点,dws CLI 是连接管道。
跟 AI 驱动的业务流程自动化:一个五维决策框架 里的思路一致—— 钉钉 AI 表格做结构化中间层,把非结构化的群聊讨论、CI/CD 日志转化成有明确字段的任务数据,AI 才有干净的数据可分析。
四、AI 表格结构设计
AI 表格是整个工作流的核心。字段设计要同时满足「记录」和「分析」两个需求:
| 字段 | 类型 | 用途 |
|---|---|---|
| task_id | 文本 | 唯一标识,如 BUG-042、REQ-015 |
| type | 单选 | bug / feature / improvement / tech-debt |
| priority | 单选 | P0 / P1 / P2 / P3 |
| status | 单选 | 待办 / 开发中 / 测试中 / 已部署 / 已完成 |
| assignee | 成员 | 负责人 |
| context | 长文本 | 任务背景、复现步骤、需求描述 |
| ai_analysis | 长文本 | AI 主动生成的分析和建议 |
| ci_status | 单选 | 待构建 / 构建中 / 通过 / 失败 |
| created_at | 日期 | 创建时间 |
| completed_at | 日期 | 完成时间(自动回填) |
| iteration | 单选 | Sprint 编号 |
关键在 ai_analysis 这个字段——它不是让人填的,是 AI 主动写入的。这是 AI 表格和普通表格的本质区别。
一条典型的记录:
task_id: BUG-042
type: bug
priority: P0
status: 开发中
assignee: 张三
context: 用户支付时频繁超时,错误码 PAYMENT_TIMEOUT
ai_analysis: 支付超时集中在支付网关模块,关联 v2.3.1 发布。
根因可能是 PaymentClient 超时配置过短。
建议方案:添加重试策略(3 次,间隔 2s/5s/10s),
调整 connectTimeout 从 3s 到 5s。预计 30 分钟。
ci_status: 构建中
Anthropic Skills 指南里说「Value lies in gotchas」——最有价值的不是 AI 已知的编程知识,而是团队特有的上下文。AI 表格通过日常积累,逐渐「学会」了:哪些模块容易出 bug、谁的专长是什么、某类问题的常见根因。这些 gotcha 体现在 ai_analysis 的分析质量里。
五、dws CLI:串联一切的管道
dws CLI 是让这个工作流跑起来的关键基础设施。它不是一个抽象层,而是直接操作钉钉能力的命令行工具。我在 对话即编程:非工程师的 30 秒自动化 里展示过 dws 的能力——这里把它用在 Scrum 场景。
Anthropic Skills 指南把 Scripts 列为 Skill 成熟后自然长出的三个组件之一:「预烘焙辅助函数,节省上下文和轮次,让 AI 专注于编排」。dws CLI 就是这里的 Scripts。
5.1 晨会摘要推送
每天 9:30,从 AI 表格读取当日待办,生成摘要推送到群:
import subprocess, json
from datetime import datetime
def dws_run(args: list[str]) -> dict:
"""执行 dws 命令并解析 JSON 输出"""
result = subprocess.run(
["dws"] + args + ["-f", "json"],
capture_output=True, text=True
)
return json.loads(result.stdout)
def send_group_message(text: str) -> None:
"""发送消息到 Scrum 团队群"""
subprocess.run([
"dws", "chat", "message", "send",
"--group-id", "$SCRUM_GROUP_ID",
"--content", text,
"-f", "json"
])
# generated by AI
def daily_standup_summary():
"""每日晨会摘要:读取 AI 表格,推送分析到群"""
records = dws_run([
"aitable", "record", "list",
"--base-id", "$BASE_ID",
"--table-id", "$TABLE_ID",
"--filter", "status!=已完成 AND sprint=当前"
])
p0 = [r for r in records if r["priority"] == "P0"]
p1 = [r for r in records if r["priority"] == "P1"]
bugs = [r for r in records if r["type"] == "bug"]
summary = (
f"📊 **{datetime.now().strftime('%m/%d')} 晨会摘要**\n\n"
f"今日待办 {len(records)} 项 "
f"(P0×{len(p0)} / P1×{len(p1)})\n\n"
)
if len(bugs) >= 3:
modules = {}
for b in bugs:
mod = b.get("module", "未知")
modules[mod] = modules.get(mod, 0) + 1
top_module = max(modules, key=modules.get)
if modules[top_module] >= 2:
summary += (
f"⚠️ {top_module} 模块有 {modules[top_module]} 个 bug,"
f"建议优先排查\n\n"
)
for r in records[:5]:
emoji = "🔴" if r["priority"] == "P0" else "🟡"
summary += (
f"{emoji} [{r['task_id']}] {r['context'][:30]}...\n"
f" → {r.get('ai_analysis', '待分析')[:60]}\n"
)
send_group_message(summary)
# generated by AI
5.2 CI/CD 回调更新
构建结果自动回写 AI 表格,任务状态变化自动通知群:
from dataclasses import dataclass
@dataclass
class CIBuildResult:
task_id: str
status: str # "success" | "failed"
duration: int # 秒
deploy_env: str # "staging" | "production"
commit_sha: str
def on_ci_complete(build: CIBuildResult):
"""CI/CD 完成回调:更新 AI 表格 + 通知群"""
# 更新 AI 表格
new_status = "测试中" if build.status == "success" else "构建失败"
dws_run([
"aitable", "record", "update",
"--base-id", "$BASE_ID",
"--table-id", "$TABLE_ID",
"--record-id", build.task_id,
"--fields", json.dumps({
"ci_status": "通过" if build.status == "success" else "失败",
"status": new_status,
})
])
# 推送到群
if build.status == "success":
msg = (
f"✅ {build.task_id} 构建通过 "
f"({build.duration // 60} 分钟)"
f"→ 已部署 {build.deploy_env}"
)
else:
msg = (
f"❌ {build.task_id} 构建失败,"
f"请 {get_assignee(build.task_id)} 检查"
)
send_group_message(msg)
# generated by AI
5.3 状态变更自动通知
任务状态每次变更都自动推送,不用人工同步:
def on_status_change(task_id: str, old: str, new: str, assignee: str):
"""任务状态变更 → 自动通知群"""
emoji_map = {
"开发中": "🔧", "测试中": "🧪",
"已部署": "🚀", "已完成": "✅"
}
emoji = emoji_map.get(new, "📋")
send_group_message(
f"{emoji} {task_id}:{old} → **{new}**({assignee})"
)
# generated by AI
dws CLI 在这里扮演的角色,跟 Anthropic 指南里说的 Scripts 完全一致:「预烘焙辅助函数,让 AI 专注于编排」。你不需要写 REST API 调用、不需要处理鉴权、不需要管分页——一行命令搞定。
六、AI 分析:从记录到建议
AI 表格最有价值的能力不是记录,而是 主动分析。这是它区别于所有传统项目管理工具的地方。
6.1 Bug 修复场景
当一个 P0 bug 进入 AI 表格,AI 不只是记录它——它会:
- 关联分析:扫描同模块近期 bug,发现集中趋势
- 根因推断:结合最近的代码提交和 CI 日志,给出可能的根因
- 方案建议:基于代码上下文,给出修复方案
- 人员推荐:根据团队成员的历史修复记录,推荐最合适的人
- 影响评估:检查是否有需求任务依赖此 bug 的修复
这些分析结果写入 ai_analysis 字段,在晨会摘要中推送。
6.2 需求迭代场景
当产品需求进入 AI 表格,AI 会:
- 依赖检查:是否存在未完成的依赖任务(bug、技术债)
- 工作量估算:基于类似历史任务的实际耗时
- 排期建议:考虑团队当前负载,推荐合理的排期
- 风险预警:标记可能影响交付的前置条件
6.3 一个完整的日循环
把上面的环节串起来,一个 Scrum 团队的一天是这样的:
| 时间 | 动作 | AI 表格操作 | 群通知 |
|---|---|---|---|
| 09:30 | 晨会 | 读取全部待办 → 生成摘要 + 分析 → 推送 | 晨会摘要 + 优先级建议 |
| 10:00 | 张三认领 BUG-042 | 状态更新为「开发中」 | 「🔧 BUG-042 开发中(张三)」 |
| 10:40 | 张三提交代码 | CI/CD 触发构建 | — |
| 10:55 | 构建通过 | ci_status → 「通过」,状态 → 「测试中」 | 「✅ BUG-042 构建通过 → 部署 staging」 |
| 11:00 | AI 分析 | 检查剩余支付 bug,更新优先级 | 「📊 支付模块还有 2 个 bug,建议…」 |
| 14:00 | 测试通过 | 状态 → 「已部署」 | 「🚀 BUG-042 已部署 production」 |
| 17:30 | 日终汇总 | 统计当日完成情况 | 日终报告 |
每个环节都是自动触发、自动流转。人只做两件事: 决策 (认领哪个任务、是否采纳 AI 方案)和 执行 (写代码、做测试)。
Anthropic 指南把这种模式叫做「premature done gate」——Agent 说完成了不算完成,必须通过验证。在 Scrum 工作流里,CI/CD 就是这个 gate。代码提交不算完成,构建通过不算完成,部署成功、测试通过,AI 表格才把状态更新为「已完成」。
七、人的角色:不是执行 AI 方案,而是做决策
这里要正面回应一个常见的质疑:AI 的分析经常不靠谱,让 AI 给建议不是增加噪音吗?
这个质疑成立,如果 AI 被定位为「决策者」。但在 Scrum 工作流里,AI 的角色是「提案者」——它铺开上下文、给出建议,人做最终判断。
具体来说:
- AI 说「建议张三处理 BUG-042」→ 组长可以改派给更合适的人
- AI 说「建议添加重试策略」→ 张三可以改用熔断方案
- AI 说「预计 30 分钟」→ 张三知道实际上要 2 小时
价值不在于 AI 的每条建议都准确,而在于:
- 上下文可见性——所有人同时看到 AI 汇总的全貌,不用各自去翻数据
- 启动成本降低——从零开始分析一个问题需要通读代码和日志,从 AI 的初步分析出发可以直接验证和修正(基于我的项目经验,这个差距通常在数量级上)
- 知识不丢失——AI 的分析记录自动积累,形成团队的知识库
Anthropic 指南里有一个好说法:「模型会制造完成幻觉」。对,AI 的建议也会制造「正确幻觉」。所以人的角色不是被动接受,而是主动验证。AI 提议 + 人决策,比纯人工分析更高效,比纯 AI 自动化更可靠。
八、落地要注意的坑
说完整套流程的好处,也得说几个实际的坑,免得看起来太美好:
- AI 分析质量取决于数据质量——如果团队不在 AI 表格里维护
context字段(只填标题不填背景),AI 的分析就是空中楼阁。冷启动阶段需要人工投入把上下文写清楚 - dws CLI 需要权限配置——AI 表格的读写、群消息发送都需要 OAuth 授权。第一次搭的时候花在权限调试上的时间可能比写代码还多
- AI 分析需要调校——开箱即用的 AI 分析往往太泛。需要在 AI 表格里配好分析提示词,告诉 AI 你们团队的模块划分、常见根因、人员专长。这就是 Anthropic 指南里说的「gotcha」——你团队的特定知识
- 通知频率要克制——每个状态变更都推送群消息,容易变成噪音。建议只对 P0/P1 和关键状态变更(构建失败、部署成功)推送,其他的在晨会摘要里汇总
- CI/CD 回调需要 Webhook——不是所有 CI/CD 系统都原生支持钉钉 Webhook,可能需要一个中间层转发
九、对比与总结
| 维度 | 传统 Scrum | AI 原生 Scrum |
|---|---|---|
| 信息汇聚 | 人工更新任务系统 | AI 表格自动从 CI/CD、群聊采集 |
| 每日同步 | 站会口头沟通 | AI 推送结构化摘要到群 |
| 任务分配 | Scrum Master 手动分派 | AI 分析 + 推荐,人确认 |
| 方案制定 | 工程师从零分析 | AI 提供初步方案,工程师验证和调整 |
| 状态通知 | 人去看板查看 | 状态变更自动推送群 |
| 验证 | 人工 Review + 测试 | CI/CD 作为「premature done gate」 |
| 知识沉淀 | 事后写文档 | 分析记录自动积累 |
整套工作流的核心不是「用 AI 替代人」,而是 重新分配人和 AI 各自擅长的事:
- AI 擅长:数据汇聚、模式识别、关联分析、状态追踪、自动通知
- 人擅长:判断、决策、创造性解决问题、经验直觉
Anthropic Skills 指南说,最好的 Skill 是聚焦的、有验证的、记录 gotcha 的。AI 表格做 Scrum 团队的大脑,本质上就是在构建一个不断进化的团队 Skill——它聚焦在 Scrum 日常循环上,通过 CI/CD 做验证,通过日常积累记录团队的 gotcha。
你在团队日常中有哪些信息还在靠人肉搬运?欢迎留言讨论。