4 月底,OpenAI 发布了 Codex CLI 0.128.0。更新日志里藏着一句话:「Added persisted /goal workflows with app-server APIs, model tools, runtime continuation, and TUI controls.」几乎同一时间,Claude Code 也上线了 /goal 指令。Greg Brockman 在推特上写了一句:「codex now has a built-in Ralph loop++.」
大多数人把这条更新当作又一个 feature flag 滑过去了。但如果你仔细拆解 /goal 的设计,会发现它代表的不是「又一个功能」,而是 AI Agent 工程的一次范式跃迁。
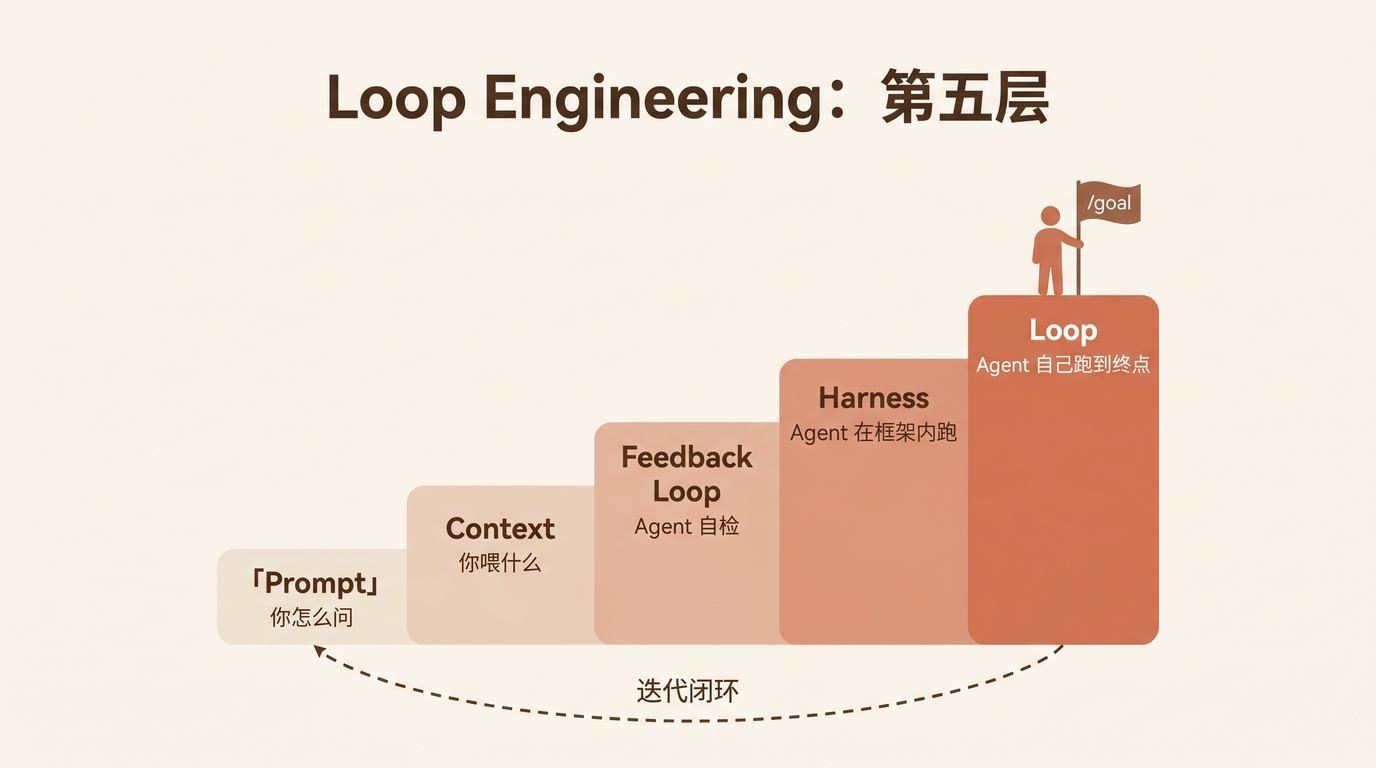
五层演进
过去两年,AI Agent 工程的能力层级一直在往上推。Daniel Demmel 在他那篇 Feedback Loop Engineering 里总结了四层:
Prompt Engineering — 你怎么问
< Context Engineering — 你喂什么
< Feedback Loop Eng — Agent 能不能自检
< Harness Eng — Agent 在什么框架内运行
这四层有一个共同特征: 人决定下一步做什么。Prompt 层,人写指令;Context 层,人喂信息;Feedback Loop 层,人建验证工具;Harness 层,人设计 workflow。Agent 在人的框架内执行,不会越界。
但 /goal 打破了这个模式。你不再告诉 Agent 每一步怎么走,你只告诉它终点线在哪:
Prompt Engineering — 你怎么问
< Context Engineering — 你喂什么
< Feedback Loop Eng — Agent 能不能自检
< Harness Eng — Agent 在什么框架内运行
< Loop Eng — Agent 自己跑到终点
| 层级 | 人的角色 | Agent 的角色 |
|---|---|---|
| Prompt | 写指令 | 执行一次 |
| Context | 喂上下文 | 执行一次 |
| Feedback Loop | 建验证工具 | 执行 + 自检 |
| Harness | 设计跑道 | 在框架内执行 |
| Loop | 定义终点线 + 预算 | 自己找路跑到 |
我在 Agent = Model + Harness 公式背后的工程纪律 中讨论过 Harness Engineering 的核心: Agent = Model + Harness,Harness 约束并放大 Model 的能力。Loop Engineering 不是替代 Harness——它在 Harness 之上加了一层自治。好的 Loop 需要好的 Harness 做底座。区别在于谁决定下一步:Harness 模式下人编排 workflow,Loop 模式下 Agent 根据当前状态自己决定。
有人会说:「Loop 不就是 Harness 加个 auto_continue=true 吗?本质还是一个 while 循环。」这个反驳有道理,但不完整。Loop Engineering 真正新增的东西是四个组件的组合: fresh context per iteration (防止 context rot 和 goal drift)、 structured state machine (5 个状态,不是简单的 running/done)、 audit-first completion (强制验证,对抗 proxy signal collapse)、 budget as first-class concern (token 预算,不是 iteration count)。单个组件都不新,组合起来构成了一个新的工程范式——你没法只靠加一个 toggle 实现 14 小时自主运行的设备驱动项目。
什么是 Loop Engineering
Loop Engineering 的核心模式来自 Geoffrey Huntley 的 Ralph Loop:
The loop’s intelligence is in the loop, not in the agent. The agent is fungible. The loop is what makes it autonomous.
翻译成工程语言:
定义 /goal(终点线)+ 设置 token budget(成本上限)
↓
Agent 自主迭代:
执行一步 → 验证结果 → 更新状态 → 继续 or 停止
↓
到达终点 / 预算耗尽 / 卡住了 → 报告
Codex 的 /goal 实现了五个状态:
pursuing → paused → achieved / unmet / budget-limited
关键设计是 每轮用 fresh context。Agent 跑久了会出现两个致命问题: context rot (上下文腐烂——历史信息太多,精确度下降)和 goal drift (目标漂移——跑着跑着解决了一个略有不同的问题)。每轮 fresh context 让长期记忆在 loop 里,不在 model 里。
Codex 的 /goal 指令集很简洁:
| 指令 | 作用 |
|---|---|
/goal <目标> | 设置目标,开始自主迭代 |
/goal pause | 暂停,保留状态 |
/goal resume | 恢复 |
/goal clear | 清除目标,回到普通对话 |
Claude Code 的 /goal 类似:/goal 「all auth tests pass and lint is clean」——声明式目标,Agent 跑到满足条件为止。
a16z 的 Andrew Chen 分享了一个案例:他让 Codex 在一个 eGPU 设备驱动项目上跑了 14 个小时,一夜之间完成。这就是 Loop Engineering 的典型场景——人定义了终点线,Agent 自己跑了一整夜。
Proxy Signal Collapse
Loop Engineering 最大的坑叫 proxy signal collapse——Agent 用表面信号代替真实完成。
我在 小学标准化试卷 AI 批改 Agent 最佳工程实践 中遇到过类似问题:Agent 说「批改完成」,但其实只检查了答案对不对,没有判断解题过程是否合理。表面信号(答案正确 ≠ 解题正确)成了 proxy。
在 Loop 场景下这个问题更严重。Agent 说「测试通过了」,但它只跑了单元测试没跑集成测试。说「代码已提交」,但提交到了错误的分支。说「表单填好了」,但其实漏了三个必填字段。
Codex 的 continuation.md 模板专门针对这个问题:
# continuation.md — 每轮注入 Agent 的 system prompt
- 不接受 proxy signal 作为完成
- 必须 inspect actual files
- 必须 run actual tests
- 必须 verify actual output
- 只有每个 checklist item 都通过直接验证,才能调用 update_goal(achieved)
# generated by hugo AI
这跟你在公司里遇到的情况一模一样——下属说「搞定了」,你得问:「怎么验证的?」
钉钉场景:差旅报销
下面用一个设计场景来展示 Loop Engineering 在 To B 产品中的实际运作。这个场景尚未完整落地,但每一步的 API 和校验能力在钉钉平台上都已具备。
找一个性价比最高的场景来展开。
| 维度 | 评估 |
|---|---|
| 目标明确 | 表单字段填完 + 校验通过 + 提交成功 |
| 验证天然存在 | 钉钉表单有字段类型校验、必填项、业务规则 |
| 复杂度适中 | 单次 loop 100k-300k token,约 ¥0.5-1.5 |
| 高频 | 每个员工每周多次提交(估算) |
| 痛点真实 | 填表烦、字段多、容易填错被打回 |
用户的输入只有一句话:
/goal "提交上周杭州出差的报销单,高铁票 3 张共 ¥1,200,
住宿 2 晚 ¥800,餐补按公司标准"
然后 Agent 开始自主迭代:
Iteration 1: 打开报销单模板,识别全部字段(日期、金额、项目编码、附件...)
Iteration 2: 从聊天历史和附件中提取票据信息
Iteration 3: 填写基础字段
Iteration 4: 查公司制度 → 餐补 ¥100/天 × 5 天 = ¥500
Iteration 5: 上传附件
Iteration 6: 触发钉钉校验 → 报错:「项目编码必填」
Iteration 7: 从历史报销记录匹配项目编码
Iteration 8: 重新校验 → 0 error
Iteration 9: 提交 → 成功 → update_goal(achieved)
注意 Iteration 6 和 7——这就是 Loop 的价值所在。如果是 Harness 模式,人必须提前编排好「如果项目编码为空 → 查历史记录」的分支逻辑。但 Loop 模式下,Agent 自己发现缺了字段,自己去找。人只需要提供校验 API(Harness 的传感器组件),Agent 自己处理异常路径。
防止 proxy signal collapse 的规则:
# continuation.md — 差旅报销场景
- 必须调用钉钉 API 触发真实校验,不接受「看起来填完了」
- 校验返回 0 error 才算 achieved
- 附件必须 verify 文件 ID 存在且大小 > 0
- 金额总计必须等于各分项之和(防止计算错误)
# generated by hugo AI
性价比:
| 对比 | 人工 | Agent Loop |
|---|---|---|
| 时间 | 15-20 分钟 | 2-3 分钟 |
| 打回率 | ~15%(经验估算) | <3%(校验驱动) |
| Token 成本 | ¥0 | ¥1.2(约 200k tokens) |
| 用户价值 | — | 省 15 分钟 ≈ ¥25(按 ¥100/小时估算) |
¥1.2 换 ¥25,约 20 倍回报 (基于上述估算)。这不是因为 model 变强了,而是因为 loop 把验证成本降到了接近零——钉钉的校验 API 是现成的,Agent 每跑一步都能免费检查。
其他场景
不展开,但每个都满足 Loop Engineering 的三个前提: 目标可验证、复杂度适中、高频。
| 场景 | /goal | 验证方式 | Token 预算 |
|---|---|---|---|
| 会议待办闭环 | 「从会议纪要提取 action items 并跟踪到完成」 | 待办状态全部 = done | 500k-1M |
| 群日报收集 | 「收齐今天全部日报并发汇总」 | 全员已交 + 汇总已发 | 200k-500k |
| CRM 跟进更新 | 「更新 A 客户的最新跟进记录」 | CRM 字段已更新 + 下次提醒已设置 | 100k-300k |
| 招聘流程推进 | 「把候选人 B 推进到二面阶段」 | 面试已安排 + 通知已发 | 300k-800k |
| 审批催办 | 「把超 48 小时未审批的单据催完」 | 全部已 @对应审批人 | 50k-200k |
什么时候不该用
Loop Engineering 不是银弹。三种情况别用:
目标太简单——请个假、发条消息,一次 API 调用搞定。用 loop 是杀鸡用牛刀。
目标太大——「帮我做一个完整的项目方案」。这种 goal 太大,token 预算不可控,proxy signal 太多。拆小了再用。
没有验证手段——「写一篇好文章」。「好」没有客观标准,loop 永远不知道该停。
判断标准: 能用一条命令验证 done 还是 not done,就适合 loop;不能,就不适合。
给 To B 产品团队的建议
先建 Harness,再上 Loop。
没有 Harness 做底座就上 Loop Engineering,等于让 Agent 在没有护栏的高速公路上自动驾驶。我在 把 Bug Fix 变成 AI 训练数据:Harness Engineering 的飞轮效应 中讨论过 Harness 的飞轮效应——好的 Harness 越用越聪明,知识会复利增长。Loop 建立在这个飞轮之上。
你需要四样东西:
- 验证工具——表单校验 API、状态查询 API、文件存在性检查。这是 loop 能停下来的前提
- 安全护栏——token budget 上限、操作白名单、敏感操作确认。这是防止 loop 失控的保险
- 状态可观测——每轮迭代的决策日志、最终审计报告。这是出了问题能追溯的基础
- 优雅退出——卡住了能报 unmet,不要死循环烧 token
Codex 的设计值得参考:update_goal 是结构化 tool call(不是文本声明),五个状态都有明确的语义,budget_limit.md 模板指导 Agent 在预算耗尽时优雅退出——总结进度、列出剩余工作、给出明确的下一步。
一个升维问题
Harness Engineering 时代,工程师的核心能力是 设计 workflow。Loop Engineering 时代,核心能力变成了 定义 done——你能不能用一条可执行的验证条件,把「完成」这件事说清楚?
这其实是一个古老的管理学问题:你能不能把目标从模糊的「把这件事做好」变成可验证的「满足这些条件就算好」?好的管理者一直在做这件事。只不过以前是对人,现在是对 Agent。
你在实际落地中遇到过什么坑?欢迎留言讨论。