6 月 9 日下午,我对 AI 说了一句「分析下本项目」。
4 秒后,它给了我一份完整的项目分析报告:13 个 JS 文件、6773 行代码、技术栈拆解、架构特点、功能清单。然后我说「在登录页面加个多语言切换」,它改了 3 个文件,跑了测试,commit,push,部署。全程我没打开过编辑器。
这不是一个 demo。这是一个跑在生产环境的全栈应用——带 CRDT 实时协同编辑、PWA 离线支持、三语国际化、OAuth 登录、AI 代理 Edge Function。35 次 commit,从 2 月到 6 月,每一行代码都是 AI 写的。
这不是 Vibe Coding
先划清一条线。
Vibe coding 是「告诉 AI 你想要什么,然后接受它给你的东西」。结果通常是一个能跑的 prototype,经不起第二轮审视。
我做的事情不一样。我扮演的角色是 产品驾驶员——我知道我要什么功能、什么交互、什么视觉风格,但我完全不碰代码。AI 是执行者,我是决策者。区别在于:
- Vibe coder 说:「帮我做一个笔记应用」
- 产品驾驶员说:「协同编辑不点保存就保存了,这不对,需要用户点保存」
前者给出方向,后者给出 判断。
我在 LLM 押注在 Coding Agent 上是正确的 里写过,当每个人都能写代码,IT 系统的瓶颈不再是技术,而是想象力。这篇想进一步说的是: 想象力不够,还需要判断力——知道什么该做、什么不该做、什么时候 AI 的方案是对的、什么时候它在「正确地实现错误的思路」。
一个真实项目的全程复盘
项目是什么
ai-notepad,一个 AI 驱动的个人笔记应用。部署在 hugozhu.site/notes。核心功能:
| 功能 | 技术实现 |
|---|---|
| 笔记 CRUD | Supabase PostgreSQL + RLS 策略 |
| 实时协同编辑 | Yjs CRDT + CodeMirror 6 + Supabase Realtime |
| AI 助手 | Anthropic/OpenAI/OpenRouter → Edge Function 代理 |
| 离线支持 | IndexedDB + Service Worker + 后台同步队列 |
| 国际化 | 自建轻量 i18n(中/英/日) |
| 认证 | Supabase Auth(邮箱/Google/GitHub OAuth) |
| 修订历史 | before/after diff + AI 摘要 |
13 个 JS 文件,零框架,零构建步骤。最大的文件 app.js 有 1276 行。
时间线
项目跨越 4 个月,但真正密集的开发集中在 3 天:
2026-02-05 初始搭建:全栈应用 + Supabase 后端
2026-02-06 离线优先:IndexedDB + Service Worker
┄┄ 4 个月空窗 ┄┄
2026-06-05 补充测试 + 子路径部署
2026-06-08 协同编辑(Yjs + CodeMirror)+ CI/CD
2026-06-09 i18n + 登录页语言切换
2026-06-10 一天之内:footer + 版本号自动更新 + 协同编辑
cancel bug(4 轮修复)+ 还原按钮 + 头像
+ Claude 风格主题 + OpenRouter 集成
6 月 10 日那天,12 个小时,15 次 commit。每次从需求描述到部署上线不到 10 分钟。
我的工作方式
打开终端,用自然语言下指令。AI 改代码、跑测试、提交。我的角色在三个身份之间切换:
产品经理:定义功能需求
「编辑页面上增加一个按钮:还原,点击后从数据库里加载内容」
QA 工程师:手动验证、发现 bug
「编辑共享笔记后点取消,再次打开笔记,内容还是编辑后的,应该是编辑前的」
设计师:调整视觉细节
「头像大小减少到一半」→「头像可以再大点,到 30px」
我从来没打开过 VS Code。甚至没有看过 AI 生成的大部分代码。我通过 行为 来判断代码质量——按钮点了有没有反应、取消后内容有没有恢复、切换语言后界面有没有刷新。
这和 Claude Code 自动修正的原理 里描述的 Agent Loop 异曲同工:反馈循环驱动修正。只不过在这个场景里,反馈不是来自编译器的报错,而是来自 人的判断。
协同编辑 Cancel Bug:AI 的四轮试错
这是整个项目里最有教学意义的一段经历。
问题描述很简单:协同编辑模式下,用户编辑内容后点「取消」,再次打开笔记,编辑过的内容还在——应该恢复到编辑前的状态。
我花了 4 轮才让 AI 修好这个 bug。每一轮,AI 都「正确地实现了一个错误的方案」:
第 1 轮:阻止自动保存
AI 的分析是「编辑器有 auto-save,取消时应该阻止它」。它删掉了 doc.on('update') 里的 persistDebounced() 调用。听起来合理。但问题还在——因为 之前 的自动保存已经把脏数据写进了数据库。
第 2 轮:从数据库拉最新数据
AI 在打开编辑器时加了一个 SELECT content, crdt_state FROM notes 查询,确保从 DB 读最新数据。但我测试后发现:DB 里的 content 也是脏的——之前的 auto-save 同时写了 content 和 crdt_state。
第 3 轮:清除 crdt_state
AI 在取消时清除 crdt_state,让下次打开从纯文本 content 恢复。我测试后报告:「能看到 [collab] cancelled: crdt_state cleared,但内容还是取消编辑前的内容」。因为 content 字段也是脏的。
第 4 轮:保存基线快照
AI 终于在打开编辑器时保存了一份 baseline(content + crdt_state),取消时调用 restoreBaseline() 把 DB 恢复到打开时的状态。这次对了。
打开笔记 → 保存 baseline(content, crdt_state)
编辑内容 → 实时广播给协作者(不写 DB)
点保存 → flush() 写入 DB
点取消 → restoreBaseline() 恢复 DB
再次打开 → 从 DB 读取,内容是编辑前的 ✓
这 4 轮揭示了一个关键规律: AI 擅长实现方案,但不擅长判断方案是否正确。每一轮的实现都是完美的——代码逻辑清晰、没有 bug、通过了测试。但方案本身是错的,因为 AI 只看到了代码层面的因果关系,没有看到 用户意图 层面的因果关系。
「取消 = 丢弃修改」这个语义,AI 不会自己推导出来。它需要人告诉它。
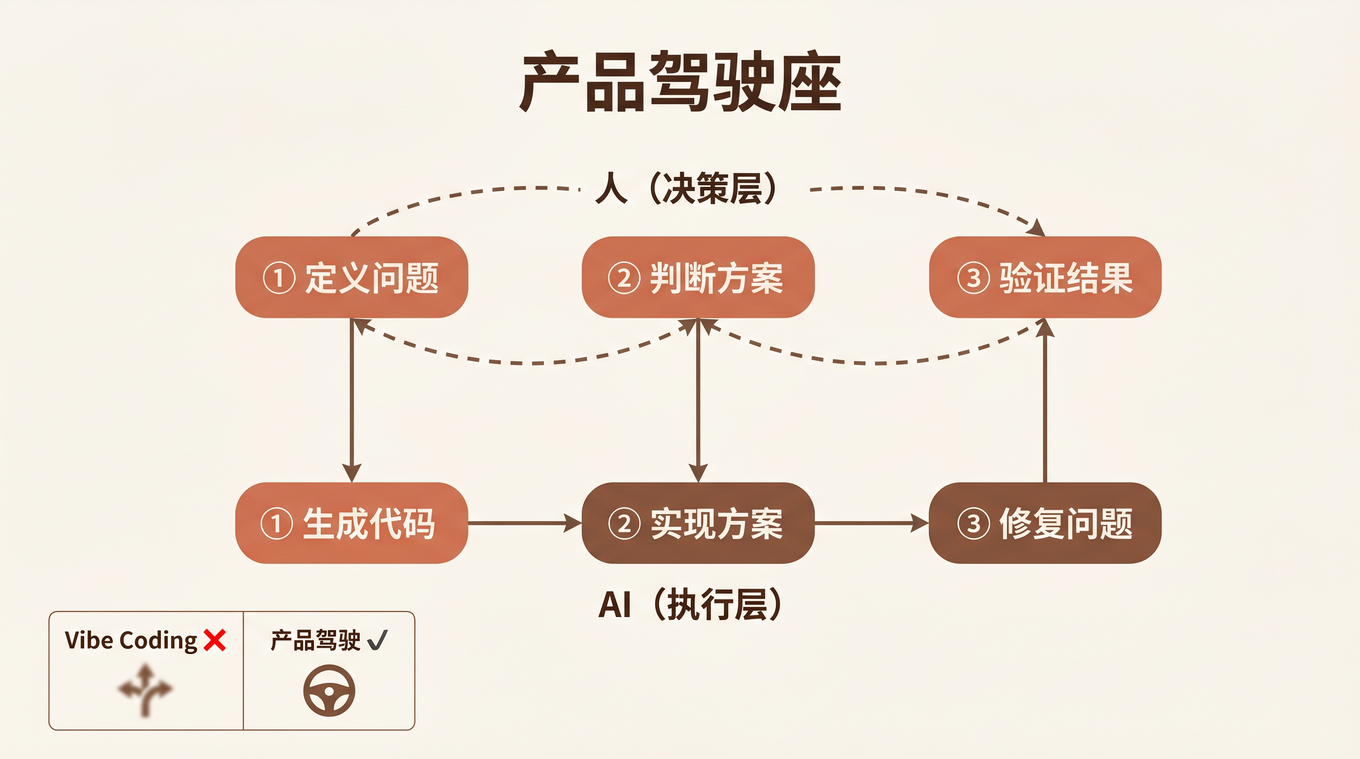
「驾驶座模型」:AI 编程中人的真正角色
从这次项目经历中,我提炼了一个框架:
┌──────────────────────────────────────────┐
│ 产品驾驶座 (Human) │
│ │
│ ① 定义问题 ② 判断方案 ③ 验证结果 │
│ 「做什么」 「对不对」 「行不行」 │
└──────────┬───────────┬───────────┬───────┘
│ │ │
▼ ▼ ▼
┌──────────────────────────────────────────┐
│ AI 执行层 │
│ │
│ ① 生成代码 ② 实现方案 ③ 修复问题 │
│ 怎么写 怎么写好 哪里不对 │
└──────────────────────────────────────────┘
三个核心分工:
1. 人定义问题,AI 生成代码
我从不说「在 showList() 函数里加一段 supabase.update()」。我说「编辑共享笔记后点取消,再次打开笔记,内容还是编辑后的,应该是编辑前的」。问题的定义决定了方案的空间。
2. 人判断方案,AI 实现方案
协同编辑的 cancel bug 修了 4 轮,不是因为 AI 代码写得不好,而是因为前 3 轮的方案方向不对。AI 每一轮都在忠实执行一个错误的思路。人的判断力是打破循环的关键。
3. 人验证结果,AI 修复问题
我不看代码,我测行为。「点取消 → 再打开 → 内容恢复了吗?」这个验证步骤,AI 自己做不了。它需要一双用户的眼睛。
这和 给 Web Agent 一个 Terminal 就够了 里的发现一致:harness 应该消失,人应该聚焦在意图层而不是实现层。在 AI 编程场景里,「harness」就是 IDE——你不需要打开它。
对 AI 驱动工作流应用的启发
从这一个项目出发,我看到几个可以迁移到更广泛场景的规律:
1. AI 是无限速度的初级工程师
AI 的代码执行速度,在我的体验中大约是人的 50-100 倍。但它不知道「取消应该丢弃修改」这种产品常识。把它当作一个执行力极强、理解力中等的初级工程师——你说得越清楚,它做得越好;你说得越模糊,它越容易「正确地做错事」。
2. 反馈循环的速度决定产品质量
这次项目里,从「发现问题」到「修复部署」的循环是 5-10 分钟。传统开发里这个循环可能是 1-2 天。 循环越短,试错成本越低,产品质量越高——因为你可以承受更多轮迭代。Cancel bug 修了 4 轮,在 40 分钟内完成。如果是传统开发,可能需要一周。
这本质上就是 Loop Engineering 讨论的核心:AI Agent 工程的演进方向,就是让反馈循环越来越短。从人驱动每一步,到人只定义终点、Agent 自己找路径,反馈循环的速度是衡量协作效率的核心指标。
3. 测试是 AI 编程的安全网
项目有 8 个自动化测试,每次 commit 前 AI 会跑 npm test。有一次 prettier 重新格式化了代码导致测试匹配失败,AI 自己发现了并修复。测试不是给 AI 看的,是给你看的——它告诉你 AI 的改动有没有破坏已有功能。
4. 产品决策不可委托
这是最重要的一条。AI 可以帮你写代码、跑测试、部署上线,但它不能帮你决定:
- 头像应该是 18px 还是 30px
- 主题色应该是紫色还是陶土色
- 取消应该保存还是丢弃
- AI 模型应该用 Claude 还是 Gemma
这些决策定义了产品是什么。 委托出去,你就不是在做产品,你是在做随机生成。
升维问题
如果一个非程序员可以通过自然语言对话构建一个带实时协同编辑的生产级全栈应用,那「软件工程师」这个角色的核心竞争力到底是什么?是写代码的能力,还是定义好问题的能力?
你在用 AI 编程时,有没有遇到过「AI 正确地实现了错误方案」的情况?你是怎么发现的?欢迎留言讨论。