6 月 5 日,我在 Cursor 里写了一句:「帮我基于 Supabase 做一个带 AI 辅助编辑的笔记应用」。AI 读了一下,开始生成代码。我切到浏览器,打开 localhost:3000,一个能用的 Markdown 编辑器已经跑起来了。
6 月 16 日,我换成了 OpenCode,模型用 Qwen3.7-Max。代码生成质量很稳,但 Token 成本大幅下降——后面算账时会看到这个数字有多夸张。12 天后,这个应用已经上线了实时协作编辑、离线同步、四种登录方式、批注系统、CLI 工具、三种语言的国际化——总共 12,000 行生产代码,7 个数据库 migration,7 个 Edge Function。
我没写一行代码。 每一行都是 AI 写的,包括那个用 Yjs CRDT 实现的多人实时协作编辑器。
这不是一个 demo,不是 tutorial,是部署在 Docker 里、每天在用的产品。之前在 我写了一行代码,AI 写了剩下 6773 行 里讨论过 100% AI Coding 时人的角色——产品驾驶座。这篇换个角度: 哪些架构决策做对了,哪些让 AI 的效率从「能用」变成了「快得离谱」。
做了什么
先看看这个叫 AI Notepad 的东西到底有什么功能:
| 功能 | 说明 |
|---|---|
| AI 辅助编辑 | 选中文字 → 摘要 / 扩展 / 润色 / 翻译 / 语法修正 / 标签生成 |
| Markdown 编辑器 | 实时预览 + 185 种语言代码高亮 + JSON 折叠树 |
| 实时协作编辑 | Yjs(CRDT)+ CodeMirror 6,多人同时编辑同一篇笔记 |
| 离线优先 | IndexedDB 本地存储 + 自动同步队列 + 指数退避重试 |
| PWA | 可安装为原生应用,Service Worker 缓存 |
| 多端认证 | 邮箱密码 + Google OAuth + GitHub OAuth + 钉钉 OAuth |
| 国际化 | 中文 / English / 日本語,零构建 i18n 方案 |
| 公开发布 | 一键生成公开 URL,支持登录门控 + IP 限流 |
| 批注系统 | 公开发布页选中文本添加批注,跨元素精确高亮 |
| 版本历史 | 每次保存记录 diff + AI 自动生成摘要 + 学习习惯 |
| CLI 工具 | 终端管理笔记:增删改查、搜索、发布 |
| Dark Mode | CSS 变量主题切换,localStorage 持久化 |
这不是一个功能列表练习。每一项都在线上运行。
技术亮点:CRDT 协作编辑
这个功能值得单独说。多人实时协作编辑是分布式系统问题——业界的标准方案是 Operational Transform(Google Docs)或 CRDT(Figma、Linear)。AI Notepad 选了 Yjs(CRDT),因为它的冲突解决是确定性的,不依赖中心服务器。
但 Yjs 原生的 WebSocket provider 需要一个专门的 y-websocket-server。我没有——我只有 Supabase。所以 AI 写了一个 自定义 provider,用 Supabase Realtime broadcast channel 做传输层:
用户A 编辑文本
↓
Y.Doc 生成 CRDT update(Uint8Array)
↓
自定义 provider → base64 编码
↓
Supabase channel.send({ type: "broadcast", event: "update", payload: ... })
↓
用户B 收到 → fromBase64() → Y.applyUpdate()
↓
CodeMirror 光标同步(awareness 协议,同一通道)
关键设计:每个用户加入时先发送自己的 state vector(当前文档状态的摘要),其他人收到后回复增量 update。这个「握手」过程让新用户能快速同步到最新状态,而不需要拉取完整文档历史。
AI 用 496 行代码实现了这一切——包括 CRDT 同步、awareness 协议(光标颜色和位置)、显式保存按钮、以及基于 Y.PermanentUserData 的逐字符作者追踪。
数据说话
git log 不会说谎:
$ git log --format="%H" --since="2024-01-01" | wc -l
114
$ git log --all --format="%ai" | awk '{print $1}' | sort -u
2026-02-05 # 项目初始化
2026-02-06 # 离线支持
2026-06-05 # 主体开发开始
2026-06-08 ~ 2026-06-16 # 主力开发期
$ wc -l js/*.js styles.css index.html
9301 total
$ wc -l supabase/functions/*/index.ts supabase/migrations/*.sql
2852 total
114 次提交,12 个活跃开发日,12,153 行生产代码,1 个贡献者。
如果用传统方式评估这个工程量:
| 模块 | 传统评估(人时) |
|---|---|
| 认证系统(4 种登录方式 + RLS) | 80-120 |
| CRUD + 分页 + 搜索 + 标签 | 60-80 |
| AI 集成(6 种 action + Edge Function) | 40-60 |
| 实时协作(Yjs + CodeMirror + 自定义 provider) | 160-240 |
| 离线同步(IndexedDB + 队列 + 重试) | 80-120 |
| PWA + Service Worker | 20-30 |
| 国际化(3 语言 + 运行时切换) | 40-60 |
| 发布系统 + 批注 + 版本历史 | 120-160 |
| CLI 工具 | 20-30 |
| 测试(unit + integration + E2E) | 80-120 |
| CI/CD + Docker 部署 | 40-60 |
| UI/UX 设计与实现 | 80-120 |
| 合计 | 820-1100 人时 |
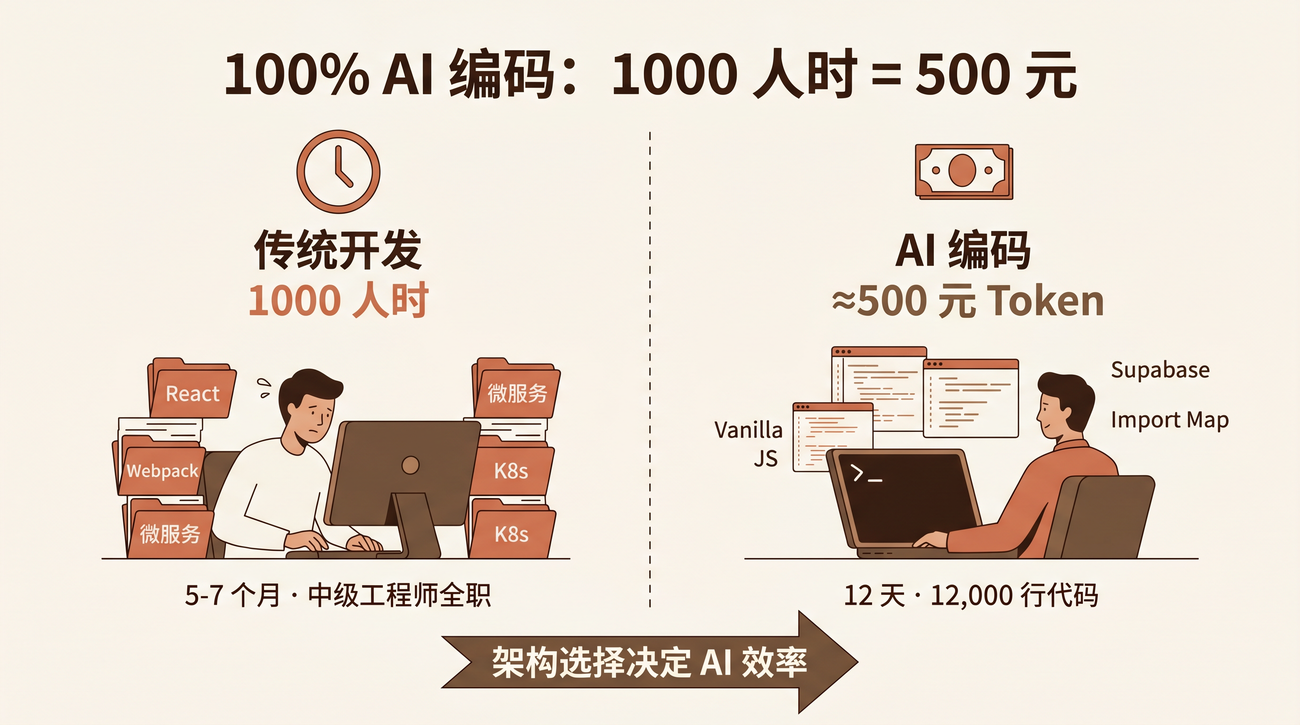
820-1100 人时,按每天 8 小时有效编码算,是 100-140 个工作日——一个熟悉这些技术的中级工程师大约 5-7 个月的全职工作。(这是基于项目复杂度的经验估算,不是精确度量。一个高手如果用对了技术栈,可能会更快;一个不熟悉 CRDT 和 IndexedDB 的工程师则可能更慢。)
实际花了 12 天。但要诚实说:这 12 天不是「输入一句话就完事了」。我做了架构决策、产品设计、需求拆解、线上验证。人做的是 架构师 + 产品经理 + QA,AI 做的是 工程师。
AI 调试循环:git log 里的真实节奏
回看批注系统的 5 个修复提交,能看到 AI 的「写 → 测 → 修」循环:
11:47 feat: add annotation system (DB schema + edge function) # 第一版
11:52 feat: add annotation system for public pages # 前端实现
12:07 fix: prevent selection clearing on mousedown # 第一坑
12:11 fix: include note.id in pub-note query # 参数漏了
64 分钟内,AI 交付了完整的批注系统(数据库 + Edge Function + 前端交互),然后连续修了 2 个 bug。这个节奏在全项目重复出现——功能交付快、bug 修复快、但偶尔会在边界条件上犯错(批注高亮跨元素选择的问题就经历了 4 次修复提交)。
这不是「AI 一次性写对」的故事,是「AI 快速交付 + 快速迭代」的故事。 架构选择让这个迭代循环足够快:改一行代码,刷新浏览器,看结果。
做对了什么
回头看 git log,有几个决策是转折点。
决策一:不选框架
这是最重要也最反直觉的决定。AI Notepad 的前端没有 React、Vue、Svelte——用的是 Vanilla JavaScript,没有构建步骤,没有 webpack、vite、esbuild。
index.html # SPA shell
styles.css # 1,956 行,单文件
js/
config.js # 冻结的配置对象
supabase.js # Supabase 客户端
auth.js # 认证逻辑
notes.js # 笔记 CRUD
ai.js # AI 服务
offline.js # 离线同步
app.js # 主应用(orchestrator)
renderers.js # app.js 的 UI 扩展
auth-ui.js # 认证 UI 扩展
ai-ui.js # AI 侧边栏扩展
为什么?因为 框架是给人类设计的抽象。React 的 hooks 规则、依赖数组的闭包陷阱、组件生命周期的心智模型——这些都是人类程序员经过多年训练才形成的直觉。AI 不需要这层抽象,反而会被它干扰。
一个没有构建步骤的项目,AI 的「编辑 → 保存 → 浏览器刷新」循环是 秒级 的。换成 React 项目,HMR 失败时 AI 要排查编译错误、理解组件树、处理状态提升——每一层都在消耗 token 和时间。
决策二:AGENTS.md 作为项目记忆
在仓库根目录放一个 AGENTS.md,告诉 AI 这个项目的全部上下文:
# AI Agent Instructions
## Project Overview
AI Notepad — a PWA notepad with AI-assisted editing...
## Architecture
(文件清单和每个文件的职责)
## Commands
pnpm install / pnpm test / pnpm lint / pnpm format
## Coding Conventions
- No build step
- No imports/exports — global variables
- ESLint + Prettier
## Key Patterns
(代码模式、命名约定、常见错误)
这个文件 770 行,但价值无法估量。AI 每次开始工作前先读这个文件,就能在 30 秒内理解整个项目——文件结构、代码风格、测试命令、部署流程、最近的变更。没有这个文件,AI 每次都要从头「探索」代码库,浪费大量时间和 token。
关键原则: 让上下文文件比代码本身更容易被 AI 理解。
决策三:Supabase 全家桶
AI 最怕什么?拼凑多个独立服务的粘合代码。
AI Notepad 的后端只用了一个服务——Supabase:
- PostgreSQL:7 个 migration 文件,RLS 策略
- Auth:邮箱密码 + Google + GitHub + 钉钉 OAuth
- Edge Functions:7 个 serverless 函数(AI 代理、发布页、批注、注册、健康检查)
- Realtime:协作编辑的 broadcast 通道
- Storage:未使用(笔记纯文本 + Markdown)
一个 config.js 文件就能初始化整个后端:
const CONFIG = Object.freeze({
SUPABASE_URL: 'https://xxx.supabase.co',
SUPABASE_ANON_KEY: 'eyJ...',
DEFAULT_AI_PROVIDER: 'anthropic',
MAX_NOTE_SIZE: 100000,
// ...
})
// generated by hugo AI
如果后端拆成 Express + PostgreSQL + Redis + JWT 中间件 + Nginx——AI 要在多个仓库、多个端口、多种配置间跳转,上下文切换成本指数增长。
决策四:Import Map 替代 Bundler
CodeMirror 和 Yjs 是 ES Module 包,通常需要 bundler。但 bundler 意味着配置文件、依赖解析、tree-shaking 调试——这些 AI 不擅长。
解决方案:HTML 原生 import map:
<script type="importmap">
{
"imports": {
"yjs": "https://esm.sh/yjs@13.6.20",
"@codemirror/state": "https://esm.sh/@codemirror/state@6.4.1",
"@codemirror/view": "https://esm.sh/@codemirror/view@6?external=@codemirror/state"
}
}
</script>
<!-- generated by hugo AI -->
?external= 参数强制所有包共享同一个 @codemirror/state 实例——这是 AI 花了最多时间调试的一个坑。但关键是: import map 就写在 HTML 里,AI 直接编辑就行,不需要配置 webpack externals 或 vite optimizeDeps。
决策五:三层次测试让 AI 自我验证
tests/
test.js # 12 个单元测试(Node assert + JSDOM)
integration.test.js # 15 个集成测试(node:test + fake-indexeddb)
e2e/notes.spec.js # 6 个 E2E 测试(Playwright Test)
$ pnpm test:all
三层次测试的意义不是测试覆盖率——而是给 AI 一个 「我能自己验证」 的闭环:
- 单元测试:AI 改了一个函数后跑
pnpm test,秒级反馈 - 集成测试:改了数据层逻辑后跑
pnpm test:integration,验证 IndexedDB 离线同步 - E2E 测试:上线前跑
pnpm test:browser,Playwright 打开真实浏览器点一遍 CRUD
没有测试的 AI Coding 就像闭着眼开车——AI 写完代码不知道对不对,只能靠人工验收,效率立刻掉 80%。
决策六:17 行 Dockerfile
FROM nginx:1.27-alpine
RUN rm /etc/nginx/conf.d/default.conf
COPY nginx.conf /etc/nginx/conf.d/app.conf
COPY index.html manifest.json sw.js styles.css /usr/share/nginx/html/
COPY js/ /usr/share/nginx/html/js/
EXPOSE 80
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD wget -qO- http://127.0.0.1/ >/dev/null 2>&1 || exit 1
CMD ["nginx", "-g", "daemon off;"]
# generated by hugo AI
没有构建步骤,所以没有多阶段构建。没有 node_modules,所以没有依赖安装。静态文件直接 COPY 进 nginx,完事。
GitHub Actions 负责推到 GHCR,SSH 到服务器 pull + restart。整个部署链路对 AI 来说是完全透明的——它能看到 .github/workflows/deploy.yml 的每一行,知道改了什么会影响部署。
什么时候不该这么做
诚实地说,Vanilla JS 无构建方案有明确的天花板:
- 超过 20,000 行前端代码:全球变量命名冲突成为真实问题,prototype 扩展模式开始难以追踪
- 复杂状态管理:当需要 undo/redo、时间旅行调试、或跨组件深层状态共享时,没有框架的状态管理会很快失控
- 多人协作开发:这个项目只有我一个贡献者(AI 替我写)。但如果 3-5 个人同时改代码,global variable 的模式需要严格的模块划分和代码审查
- 需要 SSR 或 SSG:比如博客、CMS、电商站——这些场景 Next.js / Astro 的抽象价值大于构建成本
AI Notepad 是单用户全栈应用,规模适中,架构简单——恰好落在 Vanilla JS + AI Coding 的甜区。
AI Coding 的真正杠杆
回到开头的问题:为什么 12 天能做 5-7 个月的工作量?
不是因为模型聪明。是因为架构选择让 AI 在每个环节的效率损失最小化:
| 传统架构 | AI 瓶颈 | 本项目选择 | AI 效率 |
|---|---|---|---|
| React/Vue 组件化 | 编译、状态管理、生命周期 | Vanilla JS | 直接编辑文件,秒级刷新 |
| 多服务后端 | 配置粘合、端口调试、类型同步 | Supabase 全家桶 | 一个 config 搞定 |
| Webpack/Vite | 配置文件、依赖解析 | Import Map | 写在 HTML 里,所见即所得 |
| 微前端 / monorepo | 跨仓库上下文 | 单仓库 + AGENTS.md | AI 30 秒理解全局 |
| K8s / serverless 编排 | 部署黑盒 | 17 行 Dockerfile | AI 能看到全部 |
| 人工 QA | AI 改完不会自验 | 三层次自动测试 | pnpm test:all 一键全验 |
AI Coding 的杠杆不在模型,在架构。
当你选择技术栈时,不要只问「哪个框架最流行」或「哪个数据库性能最好」。多问一句: 这个选择,对 AI 友不友好?
下一个你启动的项目,也许该把「AI 可操作性」和「系统性能」放在同等重要的位置来评估。毕竟,写代码的已经不只是你了。
你在 AI Coding 实践中遇到过什么架构坑?欢迎留言讨论。