上个月,一个做汽车零部件的朋友找我吐槽。他们花了大半年选了一个「国内最好的大模型」,又花了三个月搭了一套 Agent 系统,目标是让质检流程自动化。结果上线两周,业务部门集体退货。
原因不是模型不够聪明。是 Agent 读不懂他们的质检数据——散落在 MES 系统、Excel 表格和钉钉群聊里的检测记录,格式不统一、字段不对齐、状态不可机读。Agent 也调不动他们的审批系统——OA 只有 Web 界面,没有 API,RPA 模拟点击三天两头因为页面改版而崩掉。
他说了一句让我印象很深的话:「我们的 AI 项目,死在了数据治理和系统对接上——这两件事,跟模型半毛钱关系都没有。」
行业的注意力放错了地方
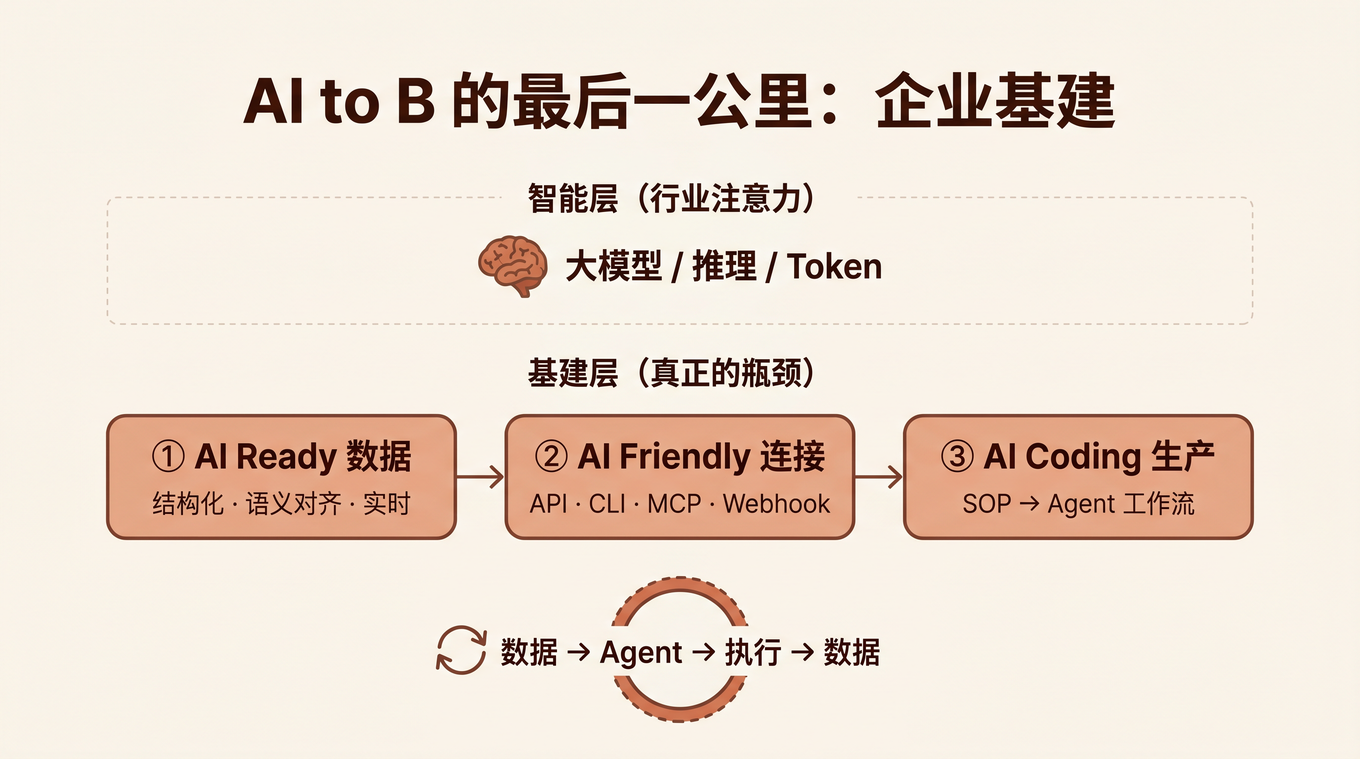
过去两年,AI to B 的叙事几乎被一个主题垄断: 模型能力。参数规模、推理速度、Benchmark 排名、每百万 Token 的价格——所有注意力都集中在「智能层」。
这不是错的,但远远不够。对企业而言,大模型、推理能力和 AI Coding 解决的是「智能」问题——Agent 能不能理解、推理、决策。而能否真正跑通最后一公里,取决于企业是否具备 AI Ready 的业务数据 和 AI Friendly 的系统连接能力。
因为 Agent 本质上不是聊天,而是在企业业务系统中感知、决策和执行。没有结构化的数据供理解,没有标准化的接口供调用,再强的模型也只能停留在对话层——能聊,不能干。
我在 基础设施比模型更重要 里引用过 Stripe Minions 的案例:Stripe 的 AI Agent 之所以能每周产出 1300 个 PR,不是因为用了什么特殊的模型,而是因为 Stripe 在 LLM 出现之前就为人类工程师建好了成熟的基础设施。同一个逻辑在企业场景里成立,只是「基础设施」的含义不同——对 Stripe 来说是代码树和构建系统,对制造企业来说是业务数据和系统连接。
三层演进:从 ERP+CRM+OA 到 业务系统+数据层+Agent 层
传统企业的 IT 架构,核心三件套是 ERP + CRM + OA。每个系统有一个精美的 Web UI,每个流程都需要人去点击、填表、审批。这套体系对人类用户已经足够好了,但对 AI Agent 来说几乎完全不可用。
我在 AI 时代的企业数字化 里把这个矛盾拆成了三根支柱——工作 Agent 化、知识 AI Ready 化、软件 CLI 化。两年过去了,这个判断没有变,但行业实践把它推进了一步。今天看,企业 IT 架构正在发生一个更清晰的演进:
旧基建 新基建
───────── ─────────
ERP + CRM + OA 业务系统 + 数据层 + Agent 层
↓ ↓
人操作 GUI Agent 调用 API/CLI
经验留在人的脑子里 数据沉淀为 Agent 的记忆
流程靠培训传承 工作流由 AI Coding 生成
这不是在原有系统上「加个 AI 功能」——它是一次架构层的重组。新架构有三层:
| 层 | 角色 | 对应 Agent 的什么 |
|---|---|---|
| 业务系统层 | ERP、CRM、MES、OA 等现有系统 | Agent 的执行环境 |
| 数据层 | AI Ready 的结构化业务数据 | Agent 的记忆和上下文 |
| Agent 层 | 由 AI Coding 生成的工作流 Agent | Agent 的决策和执行 |
三层的连接方式是:Agent 从数据层获取上下文(知道发生了什么),通过系统连接层执行业务操作(改变世界),执行结果又沉淀回数据层(积累经验)。这就形成了飞轮。
AI Ready:Agent 的记忆和上下文
回到开头那个汽车零部件厂的案例。他们的质检数据长什么样?
- MES 系统里有结构化的检测记录,但字段命名是 2008 年建系统时定的,跟现在的业务术语对不上
- 质检员在钉钉群里发的手写备注——「这批料回料比例偏高,注意注塑温度」——是有价值的经验,但对 Agent 来说是不可解析的噪音
- Excel 里的月度汇总报表,格式每个月都不一样,因为是不同的人做的
这些数据对人类来说够用——一个有经验的质检主管能在脑子里把这些碎片拼起来。但对 Agent 来说,这就是混沌。
AI Ready 不是传统意义上的「数据治理」。 传统数据治理的目标是给人做报表——数据仓库、BI 看板、ETL 流水线。AI Ready 的目标是让 Agent 能直接用这些数据做决策和执行。区别在于:
传统数据治理 AI Ready 数据
──────────── ──────────────
目标:人看报表 目标:Agent 做决策
格式:宽表、星型模型 格式:Agent 可解析的结构化上下文
时效:T+1(昨天) 时效:实时或近实时
粒度:汇总 粒度:保留原始细节和上下文
消费者:BI 工具 消费者:Agent
AI Ready 数据有几个关键特征:
- 语义对齐——字段名、状态码、枚举值跟业务术语一一对应,Agent 读到「状态=3」就知道是「待复检」而不是去猜
- 上下文完整——一条检测记录不只是数值,还附带了当批次的供应商、设备编号、操作员、环境温湿度,Agent 能做关联推理
- 时效可查——每条数据有明确的时间戳和有效期,Agent 能判断「这个标准还有效吗」
- 可寻址——Agent 能通过 API 精确查到它需要的那条数据,而不是被迫扫全表
回到那个汽车零部件厂。他们真正需要做的第一步,不是选更好的模型,而是把质检数据从「人能看懂」升级到「Agent 能看懂」。这一步听起来不性感,但它是 Agent 能不能干活的前提。
AI Friendly:Agent 的手脚和执行器
数据解决的是「Agent 知道什么」,系统连接解决的是「Agent 能做什么」。
我在 AI 时代的企业数字化 里把第三根支柱叫「软件 CLI 化」——Agent 适合通过命令行和 API 跟软件交互,而不是模拟人类的 GUI 点击。这个判断今天依然成立,但行业实践把它扩展了。
今天更准确的说法是 AI Friendly 连接层——不只是 CLI,而是一切让 Agent 能程序化操作业务系统的接口能力:
| 连接方式 | 适用场景 | 例子 |
|---|---|---|
| REST API | 标准化的系统间调用 | ERP 的订单接口、CRM 的客户查询 |
| CLI 工具 | 开发运维类操作 | 部署、配置、数据迁移 |
| MCP Server | Agent 直接调用的工具协议 | 钉钉消息、文件操作、数据库查询 |
| Webhook/事件 | 系统主动通知 Agent | 订单状态变更、审批流转到下一步 |
关键不在于用哪种技术,而在于一个原则: 每个 Agent 需要操作的业务系统,都必须有一条程序化的通路。 没有这条通路,Agent 再聪明也只能「纸上谈兵」。
那个汽车零部件厂的 OA 系统就是一个反面教材——只有 Web 界面,没有 API。他们试过 RPA 模拟点击来「连接」,但 RPA 本质上是模拟人的鼠标和键盘操作,页面一改就崩、弹窗一出就卡、并发一高就乱。这不是连接,这是胶带。
AI Friendly 连接层的建设优先级可以这样排:
高优先级:Agent 每天要调用的核心系统(ERP、MES、审批)
→ 必须有稳定 API,不接受 RPA
中优先级:偶尔需要查询的辅助系统(HR、财务)
→ 可以先用只读 API,后续补写操作
低优先级:纯展示型系统(大屏看板、报表门户)
→ Agent 不需要操作,跳过
AI Coding:快速生成 Agent 的生产工具
有了 AI Ready 的数据和 AI Friendly 的连接,还差最后一环: 谁来把数据、连接和业务逻辑组装成可执行的 Agent?
答案是 AI Coding。
我在 工作流即软件,软件即 Agent 里区分了 AI Coding 的两条路径——路径 A 是帮程序员更快地写新系统,路径 B 是把已验证的 SOP 重构为 Agent 工作流。路径 B 的需求规模远大于路径 A,因为每个企业的 SOP 数量远大于需要从零开发的系统数量。
在企业基建的语境下,AI Coding 的角色更清晰了: 它是将企业工作流快速生成 Agent 的生产工具。
输入 生产工具 输出
───────── ───────── ─────────
SOP(业务规则) ┐
├────→ AI Coding Agent ────→ Agent 工作流
AI Ready 数据(上下文)┤
│
AI Friendly 连接(手脚)┘
传统做法是什么?业务部门写需求文档 → IT 部门评审 → 排期开发 → 测试上线。一条 SOP 从需求到系统,少则三个月,多则一年。而且一旦上线,改起来又是一轮。
AI Coding 把这个周期压缩到几天甚至几小时。不是因为 AI 写代码更快(虽然确实更快),而是因为它跳过了传统软件开发的大部分摩擦——需求对齐、架构评审、排期等待。业务人员描述 SOP,AI Coding Agent 直接生成可执行的 Agent 工作流,连接 AI Ready 数据和 AI Friendly 系统接口。
我在 100% AI Coding 工程实践 里展示过一个极端案例:12000 行生产代码、7 个数据库 migration、7 个 Edge Function,100% 由 AI 生成,总 Token 费 500 元人民币。那个案例是面向消费者应用的。在企业内部,同样的能力用在 SOP-to-Agent 上,规模只会更大——因为 SOP 的数量远多于需要从零开发的系统。
飞轮:从数据到 Agent 再到数据
把三层基建拼在一起,一个完整的企业 AI 飞轮就成型了:
业务数据(AI Ready)
↓ 提供上下文
工作流(SOP 编码)
↓ AI Coding 生成
Agent(决策 + 执行)
↓ 调用 AI Friendly 连接
执行结果(自动写入系统)
↓ 沉淀为
数据(持续积累)
↓ 反哺
Agent 持续进化(越用越准)
这个飞轮跟互联网产品的增长飞轮不一样。互联网飞轮靠用户量驱动——用户越多,数据越多,推荐越准,用户更多。企业 AI 飞轮靠 **执行轨迹 **驱动——Agent 执行得越多,留下的轨迹数据越丰富,SOP 优化越精准,Agent 下一次执行得越好。
飞轮的关键齿轮有三个:
- 数据层提供记忆——Agent 不是从零开始理解业务,而是带着历史上下文做决策。那个汽车零部件厂的质检 Agent 如果能读到过去三年的检测记录,它就能判断「这批回料比例偏高」到底是异常还是在历史容忍范围内
- 连接层提供执行力——Agent 不只是建议,而是直接操作业务系统。检测到异常 → 自动触发复检工单 → 自动通知质检主管,全程不需要人切换系统
- AI Coding 提供迭代速度——SOP 变了,Agent 能在几小时内跟着变,而不是等三个月的排期。质检标准更新了?AI Coding 重新生成 Agent 工作流,当天上线
任何一个齿轮卡住,飞轮就转不起来。这就是为什么「只买最好的模型」解决不了问题——模型只是 Agent 的大脑,大脑没有记忆(数据)和手脚(连接),什么都做不了。
一个判断
如果让我给正在做 AI 战略的企业一个优先级建议,不是「选最好的模型」,也不是「找最牛的 AI 团队」,而是:
先建 AI Ready 数据层,再建 AI Friendly 连接层,最后用 AI Coding 把 SOP 变成 Agent。
这三步的顺序很重要。数据是地基——没有地基,Agent 就是空中楼阁。连接是通路——没有通路,Agent 只能纸上谈兵。AI Coding 是加速器——它把前两步的成果变成可执行的 Agent,并且让迭代速度从「季度」变成「天」。
有人会说:模型切换也有成本——prompt 工程要重写、评估体系要重建、团队要重新适应。这没错。但模型切换的成本是「周级」的(换个 API endpoint、调几轮 prompt),而数据治理和系统连接的重建成本是「年级」的。优先级的本质不是哪个不重要,而是哪个的重置成本更高。先做重置成本高的事。
模型?在最容易被替换这个意义上,它确实是最轻的一层。今天用 GPT,明天换 Claude,后天可能用国产模型——只要数据和连接是你的,模型是可插拔的。
未来三年,衡量一个企业 AI 化水平的标准,不是「用了什么模型」,而是「有多少业务数据是 AI Ready 的,有多少系统连接是 AI Friendly 的,有多少 SOP 已经变成了 Agent」。
你们公司的 AI 项目,卡在了哪一层?欢迎留言讨论。