周一早上,运营群里有人 @了运营 Agent:「帮我看看上周退款率为什么涨了」。
Agent 开始干活。它先查了 AI 表格里的退款明细,又调了客服工单系统的投诉分类,接着跑了一段 SQL 算出各渠道的退款占比,最后生成一份带趋势图的分析报告发到群里。整个过程 40 分钟,中间还主动追问了一句:「要不要把退款金额 > 500 的单独拉出来?」
报告质量不错。但安全团队事后审计时发现了三个问题:
- Agent 查退款明细时,用的是 @它那个人的 App Token——这个人恰好是运营总监,有全量数据权限。群里其他人没有这个权限,但他们都看到了报告。
- Agent 调工单系统时,用的是一个 写死在环境变量里的 API Key,这个 Key 的权限范围是
read:all,理论上 Agent 可以读任何人的工单。 - 日志里只记了「运营总监访问了退款表」, 没有记录是 Agent 在执行。
这是一个典型场景,我在不同企业里见过不同程度的版本。
在 Claude Tag 的 Agent Identity:为什么这是 Agent 时代的 OAuth 中,我讨论了 Agent 为什么需要自己的身份。这篇接着往下走: 当 Agent 进入钉钉群,权限、凭证、审计这套架构具体怎么设计?
今天的问题:Webhook 模型撑不住
钉钉群机器人的主流接入方式是 Stream 模式 (长连接 WebSocket)或 Webhook 回调。无论哪种,从系统架构的角度看,今天的群机器人本质上是这样的:
用户在群里 @Bot
↓
钉钉推送消息到 Bot 服务端
↓
Bot 用「应用级 Token」调用钉钉 API
↓
结果发回群里
这个模型有一个根本性的简化: Bot 没有自己的身份边界。
| 维度 | Webhook 模型 | 问题 |
|---|---|---|
| 认证 | 应用级 App-Only Token(2 小时有效期) | 所有群共用同一个 Token,无法区分场景 |
| 授权 | 权限点在开放平台统一配置 | 粒度到 API 级别,不到数据级别 |
| 凭证 | 写死在环境变量或配置文件 | 散落在运行时环境,Agent 能读到 |
| 审计 | 日志记应用名 | 不知道是哪个群、哪次对话触发的 |
当 Bot 只是「收到消息 → 回复一段文本」时,这些都不是问题。但当 Bot 升级为 Agent——能调外部 API、能读写数据、能执行多天任务、能主动巡检——Webhook 模型的每一个简化都会变成安全漏洞。
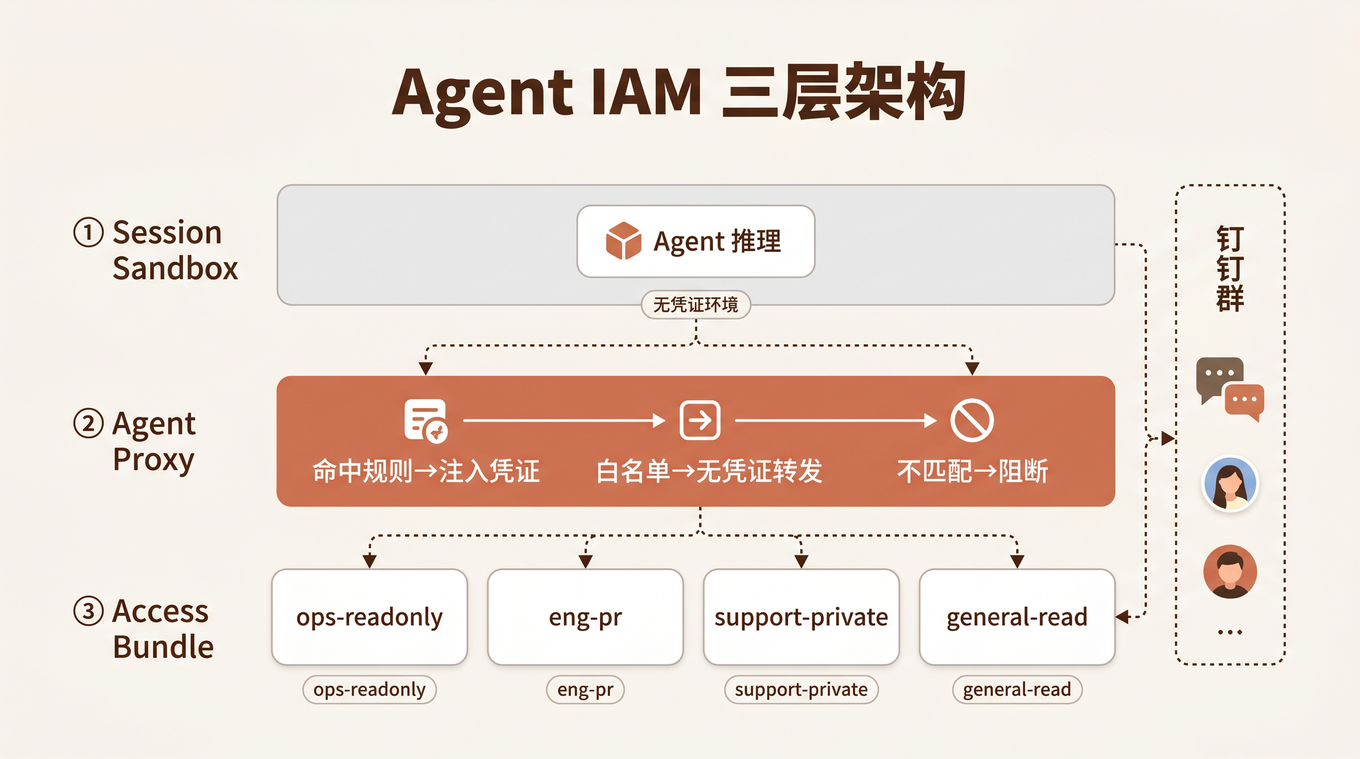
Anthropic 在 Claude Tag 里给出的答案是三层架构: Session Sandbox + Agent Proxy + Access Bundle。我们逐个拆解,然后看怎么映射到钉钉。
三层架构:Claude Tag 怎么做的
第一层:Session Sandbox——执行隔离
Claude Tag 为每个 Slack thread 创建一个 隔离沙箱。沙箱是临时的(任务完成后释放),但关键设计是:
沙箱本身不持有任何凭证。
这意味着 Agent 在沙箱里跑代码、调工具时,运行时环境里没有任何密钥、Token 或密码。Agent 能做的所有「对外操作」,都必须经过下一层。
┌──────────────────────────────┐
│ Session Sandbox │
│ ┌────────────────────────┐ │
│ │ Agent 推理 + 代码 │ │
│ │ (无凭证环境) │ │
│ └────────┬───────────────┘ │
│ │ 出站请求 │
│ ▼ │
│ ┌────────────────────────┐ │
│ │ Agent Proxy │ │
│ │ (凭证边界注入) │ │
│ └────────┬───────────────┘ │
└───────────┼──────────────────┘
│ 带凭证的请求
▼
外部服务 (GitHub, CRM...)
第二层:Agent Proxy——凭证边界注入
Agent Proxy 是沙箱和外部世界之间的 唯一出口。它的规则很简单:
| 出站请求目标 | Proxy 行为 |
|---|---|
| 命中管理员配置的 Connection Rule | 注入该 Connection 的凭证,转发(凭证留在 Proxy,不进沙箱) |
| 在网络白名单上但无 Connection | 无凭证转发 |
| 以上都不匹配 | 直接阻断 (host unreachable) |
凭证存储在一个独立的 Credential Store 里, 写入后不可再读 (write-only setup)。Agent 永远看不到凭证本身,它只知道「我可以访问 GitHub」,但拿不到 Token。
这个设计解决了一个经典问题:Agent 执行代码时,环境变量里不应该有任何密钥。即使 Agent 被 prompt injection 攻击,它也无法泄露凭证——因为凭证根本不在它的运行环境里。
第三层:Access Bundle——按场景打包权限
Access Bundle 是一组权限的打包:Connector(外部系统连接)、Repository(代码仓库)、Skills(能力包)、Standing Instructions(常驻指令)。
管理员创建 Bundle,然后把它绑定到 频道级别:
Workspace Baseline
├── general-read Bundle → 公共频道(只读内部文档 + Issue Tracker)
├── eng-triage Bundle → 工程频道(GitHub Issues + PR + 日志,只读生产)
├── eng-pr Bundle → 工程频道(可开 Branch + PR,不能 Merge)
└── support-private → 客服私有频道(CRM + Ticket,仅限私有频道)
关键设计: 公共频道继承 Workspace Baseline,私有频道可以有独立的 Identity。这意味着不同群里的同一个 Claude,权限可以完全不同。
映射到钉钉:架构怎么落
把这三层映射到钉钉,需要考虑钉钉特有的能力栈。和 Slack 不同,钉钉不只是 IM——它自带 OA 审批、AI 表格、通讯录、工作流、日志。这意味着钉钉的 Agent 运行在一个 天然更丰富的企业上下文 里,但也意味着权限边界更复杂。
有人会反驳:Slack 的第三方集成生态更成熟(MCP 连接器、Slack App Directory),Agent 调外部工具更顺手;钉钉的「全家桶」反而可能让 Agent IAM 更难做——攻击面集中在一个平台上,一旦 Agent Identity 被攻破,泄露的不只是消息,还有审批、表格、考勤。这个担心成立。但反过来看,集中也意味着 治理入口统一——钉钉的管理员后台本来就管着所有数据维度的权限,加一个 Agent Registry 比在 Slack 里协调 20 个第三方 App 的权限要直接得多。
钉钉的认证双轨制
钉钉开放平台有两种 Token:
App-Only Token(应用凭证)
└── Client Credentials Grant
└── 代表「应用自己」
└── 有效期 2 小时,需缓存
User Token(用户凭证)
└── OAuth 2.0 Authorization Code
└── 代表「某个用户」
└── 需要用户授权
今天的群机器人几乎都用 App-Only Token——一个 Token 走天下。这就像整个公司共用一个服务账号,出了事只知道「是那个应用干的」,不知道是哪个场景、哪次对话。
改造方案:Agent Service Account
参照 Claude Tag 的设计,钉钉群 Agent 的认证模型应该从「共用 App Token」升级为 按 Agent 实例注册 Service Account:
┌─────────────────────────────────────────┐
│ 钉钉开放平台 │
│ │
│ ┌─────────────────────────────────┐ │
│ │ Agent Registry(新增) │ │
│ │ │ │
│ │ agent://ops-analysis │ │
│ │ 群: 运营数据群 │ │
│ │ Bundle: ops-readonly │ │
│ │ 凭证: 边界注入 │ │
│ │ │ │
│ │ agent://eng-deploy │ │
│ │ 群: 工程发布群 │ │
│ │ Bundle: eng-pr │ │
│ │ 凭证: 边界注入 │ │
│ └─────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────┐ │
│ │ Agent Proxy Layer(新增) │ │
│ │ │ │
│ │ Connection Rules: │ │
│ │ ops-readonly → AI表格(R) │ │
│ │ ops-readonly → 工单(R) │ │
│ │ eng-pr → GitHub(RW-noMerge) │ │
│ │ │ │
│ │ Credential Store: │ │
│ │ github_token: *** (write-only)│ │
│ │ crm_api_key: *** (write-only)│ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────────┘
用代码来说明这个架构的核心逻辑:
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
class AccessMode(Enum):
READ = "read"
WRITE = "write"
NONE = "none"
@dataclass
class Connection:
"""一个外部系统的连接配置"""
name: str # 如 "crm", "github", "ai-table"
host: str # 出站域名白名单
credential_ref: str # 凭证引用(不存明文)
mode: AccessMode = AccessMode.READ
path_prefix: str = "/" # 可选:限制到特定路径
@dataclass
class AccessBundle:
"""按场景打包的权限集合"""
name: str
connections: list[Connection] = field(default_factory=list)
skills: list[str] = field(default_factory=list)
standing_instructions: str = ""
allowed_domains: list[str] = field(default_factory=list)
@dataclass
class AgentIdentity:
"""Agent 在组织中的身份"""
agent_id: str # agent://ops-analysis
display_name: str # "运营分析 Agent"
department: str # "运营部"
bundle: AccessBundle
memory_scope: str = "channel" # channel | thread | workspace
class AgentProxy:
"""凭证边界注入代理——Agent 和外部世界之间的唯一出口"""
def __init__(self, identity: AgentIdentity, credential_store: dict):
self.identity = identity
self.credential_store = credential_store # {ref: encrypted_credential}
def forward_request(self, target_host: str, path: str, method: str) -> dict:
"""处理 Agent 的出站请求"""
bundle = self.identity.bundle
# 1. 检查是否命中 Connection Rule
for conn in bundle.connections:
if target_host == conn.host and path.startswith(conn.path_prefix):
# 检查访问模式
if method in ("POST", "PUT", "DELETE") and conn.mode == AccessMode.READ:
return {"status": "blocked", "reason": "write_not_allowed"}
# 注入凭证(Agent 永远看不到这个值)
credential = self.credential_store.get(conn.credential_ref)
return {
"status": "forwarded",
"credential_attached": True,
"credential_visible_to_agent": False,
}
# 2. 检查网络白名单
if target_host in bundle.allowed_domains:
return {"status": "forwarded", "credential_attached": False}
# 3. 都不匹配——阻断
return {"status": "blocked", "reason": "host_not_allowed"}
# generated by hugo AI
这段代码展示了核心设计: Agent 发出的请求经过 Proxy 时,Proxy 根据 Connection Rule 决定是否注入凭证、是否放行。Agent 本身永远拿不到 Token。
场景映射:群聊 vs 私聊
和 Claude Tag 一样,钉钉的群聊和私聊应该走 不同的权限语义:
| 维度 | 群聊 Agent | 私聊 Agent |
|---|---|---|
| 身份 | Agent Service Account | 用户个人身份 |
| 凭证来源 | 群的 Access Bundle | 用户的个人连接器 |
| 审计归属 | 人触发 + Agent 执行 | 用户自己 |
| 记忆范围 | 群级共享 | 个人私有 |
| 适用场景 | 协作任务(排障、分析、巡检) | 个人事务(邮件草稿、日程管理) |
这个区分解决了一个常见错误: 为了省事,把个人工具接进了群。一旦工具进入群,群里所有人就可能通过 Agent 间接使用该工具。
用那三个审计问题验证
回到开头的场景,用新架构重新走一遍:
问题 1:Agent 用了运营总监的 Token。
→ 新架构下,Agent 使用自己的 Service Account(agent://ops-analysis),权限来自群的 Access Bundle(ops-readonly), 与 @它的人无关。Bundle 只授权读 AI 表格的退款视图(不是全量数据),报告里的数据范围由 Bundle 决定。
问题 2:工单系统 API Key 权限过大。
→ 新架构下,工单系统的 Connection 配置了 mode: READ 和 path_prefix: /api/v2/tickets?department=ops。即使 Agent 尝试读其他部门的工单,Proxy 会阻断。API Key 存在 Credential Store 里,Agent 看不到。
问题 3:日志没有记录 Agent 操作。 → 新架构下,审计日志同时记录两个主体:
{
"timestamp": "2026-06-29T09:30:00+08:00",
"human_requester": "张三 (运营)",
"agent_executor": "agent://ops-analysis",
"session_id": "ses_thread_abc123",
"action": "query_refund_data",
"data_source": "ai-table://refund_view",
"access_bundle": "ops-readonly",
"result_ref": "report_20260629_001",
"proxy_log": [
{"host": "table.dingtalk.com", "status": "forwarded", "credential": "table_token"},
{"host": "ticket.dingtalk.com", "status": "forwarded", "credential": "ticket_key"},
{"host": "unknown-api.com", "status": "blocked", "reason": "host_not_allowed"}
]
}
人发起,Agent 执行,系统记录。 审计断裂的问题解决了。
使用场景矩阵
不是所有群都需要完整的 Agent IAM。按风险和复杂度分层:
| 场景 | 风险 | Bundle 配置 | 凭证需求 |
|---|---|---|---|
| 内部文档问答 | 低 | general-read:只读知识库 | 无外部凭证 |
| Support Ticket Triage | 中 | support-triage:读工单 + 读 FAQ | 工单系统只读 Key |
| 运营数据分析 | 中 | ops-readonly:读 AI 表格 + 读 CRM | CRM API Key(限定路径) |
| 工程 Code Review | 中高 | eng-pr:读 GitHub + 开 PR | GitHub Token(无 Merge) |
| 生产变更执行 | 高 | prod-deploy:写 K8s + 通知 | K8s SA Token + JIT 审批 |
低风险场景 可以只用 App-Only Token + 权限点控制,不需要完整的 Agent IAM。 中高风险场景——特别是涉及写操作、跨系统、敏感数据的——必须上 Access Bundle + Proxy。
这里有一个实用原则: 权限扩展应该跟着实际工作价值走,而不是为了让配置表格看起来完整。先让 Agent 跑一个具体任务,看审计日志暴露了什么问题,再逐步扩展 Bundle。
高危动作的 Just-in-Time 审批
有些操作不应该被 Bundle 预先授权——比如写生产数据、发外部邮件、修改关键审批。这些需要 实时审批 (JIT Credential Grants):
Agent: 我需要给客户发送退款确认邮件。这需要「邮件发送」权限。
[审批请求已发送给运营总监]
运营总监: [钉钉卡片] 运营 Agent 请求发送邮件权限
目标: customer@example.com
内容: 退款确认模板 #3
[批准] [拒绝] [仅限本次]
Agent: 已发送邮件。审计记录: JIT grant #jit_001, 批准人: 运营总监
Anthropic 的路线图中提到了这个能力,钉钉的 OA 审批流天然适合承载这个交互——审批卡片就是钉钉最成熟的组件之一。
DEAP 平台的「金箍咒」框架
钉钉已有的 DEAP(DingTalk Enterprise AI Platform)提供了 Agent 治理的基础框架——内部叫「金箍咒」: 权限、配额、沙箱、审计 四件套。
| 金箍咒维度 | Claude Tag 对应 | 钉钉现状 | 差距 |
|---|---|---|---|
| 权限 | Access Bundle + Agent Identity | 权限点 + 数据范围 | 缺少 Agent 级 Identity |
| 配额 | Token Spend Limit ($100-$1M) | API 调用频率限制 | 缺少 Token 消费额度 |
| 沙箱 | Session Sandbox (无凭证) | 悟空执行沙箱 | 基本对齐 |
| 审计 | 双轨记录 (人 + Agent) | 应用级日志 | 缺少 Agent 级归因 |
差距主要在两个点: Agent 级 Identity 和 Agent 级审计归因。这两个恰好是 Claude Tag 最有创新性的地方。
好消息是,钉钉的基础设施离落地不远——MCP Server 已经有了(官方 + 社区多个实现),Stream 模式的机器人框架成熟,DEAP 的沙箱和配额能力到位。缺的是在开放平台层面增加 Agent Registry (Agent 身份注册)和 Agent Proxy (凭证边界注入)这两个组件。
一个务实的落地路径
不需要一步到位。按价值递增:
Phase 1(1-2 周):审计先行。 不改权限模型,先给 Agent 的每次操作加上双轨日志——记录 human_requester + agent_executor。这一步零风险,但立刻让审计团队能看到 Agent 在干什么。
Phase 2(1-2 月):Bundle 模板。 为高频场景定义 3-5 个 Access Bundle 模板,替代「所有群共用一个 App Token」。先从只读场景开始(general-read、ops-readonly)。
Phase 3(3-4 月):Proxy 层。 部署 Agent Proxy,把凭证从 Agent 运行时环境里抽出来,改为边界注入。这一步是安全分水岭——从此 Agent 即使被攻击也泄露不了密钥。
Phase 4(4-6 月):JIT 审批 + 记忆治理。 高危操作走审批流,长期记忆加访问控制和保留策略。
写在最后
回到开头那个退款分析的场景。同样的任务,同样的 Agent,同样的结果——但背后的架构决定了:
- 出了事能不能追溯?(审计双轨 vs 审计断裂)
- 凭证会不会泄露?(边界注入 vs 环境变量)
- 权限会不会扩散?(Bundle 隔离 vs 全量继承)
Claude Tag 用三层架构(Session Sandbox + Agent Proxy + Access Bundle)给出了一个参考答案。钉钉有比 Slack 更完整的企业上下文——OA、审批、表格、工作流都在一个平台上——这意味着如果钉钉在 Agent IAM 层面补齐,它的 Agent 协作体验会比 Slack 上的 Claude Tag 更深。
但前提是把 Agent 从「Webhook 机器人」升级为「有身份的组织成员」。
不是更聪明的 Agent,而是 有工牌的 Agent。
你的企业 AI Agent 是怎么处理身份和权限的?是还在借用人的 Token,还是已经有了独立的 Service Account?欢迎留言讨论。