周一早上,#platform-eng 频道。
Leo 发了一条消息:「checkout 今早变慢了,有人遇到吗?」
Dana 秒回:「我也是。」然后她 @了 Claude:「查一下今早部署的 diff,对比延迟数据,找出原因。」
接下来六分钟里发生的事,值得每个做 Agent 架构的人仔细看一遍。
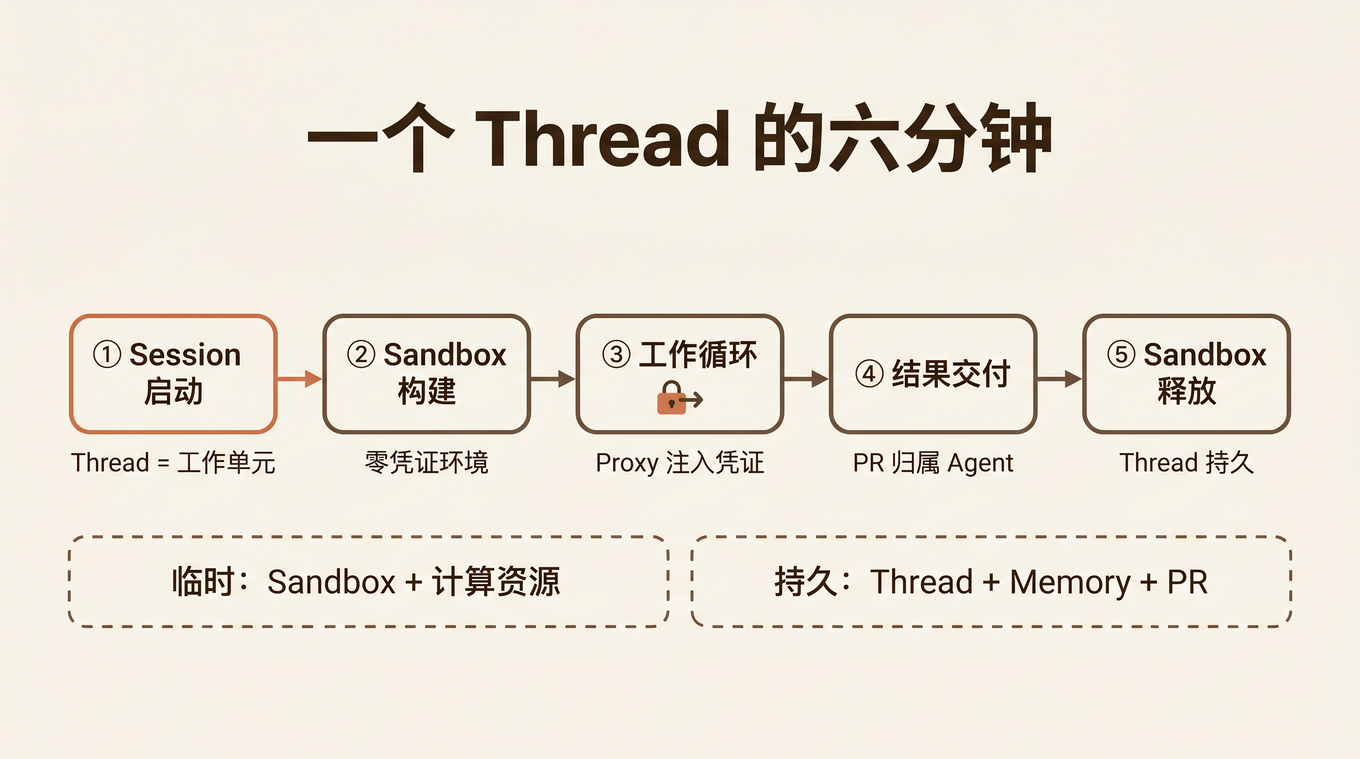
9:02 Dana @Claude — Session 启动
9:02 Claude: "is thinking..." — 沙箱构建中
9:03 Claude 贴出 checklist:
✅ 拉 Datadog p99 延迟数据
✅ 对比 deploy 4f2c1 和 main 的 diff
⏳ 本地复现慢查询
⏳ 开 PR 修复
9:04 Sam 中途加入:「顺便查一下是不是和上周缓存改动有关?」
9:06 Claude: 已确认是 4f2c1 引入的 N+1 查询,PR #382 已开,CI 跑着
六分钟。从发现慢查询到 PR 开出。
但这六分钟里真正有意思的,不是 Claude 有多快,而是 背后发生了什么。如果你拆开 Anthropic 的官方文档(Public Beta,多处标注「may change before GA」),会发现这六分钟里至少经过了五层工程决策——每一层都不是显而易见的。
在 Claude Tag 的 Agent Identity 和 钉钉群里的 Agent IAM 架构 中,我分别讨论了「Agent 为什么需要身份」和「权限架构怎么落地」。这篇换个角度: 从一个 thread 的完整生命周期,拆解 Claude Tag 的 Session 设计——它选择 Thread 而不是 Channel 或 User 作为工作单元,这个决策是怎么同时解决隔离性、协作性和持久性的三角矛盾的。
第一层:Session 启动——一个 Thread 就是一个世界
当 Dana 在 thread 里 @Claude 时,Claude Tag 做了第一件事:为这个 thread 创建一个 Session。
不是为 Dana 创建。不是为 #platform-eng 创建。是为这个 thread 创建。
@Claude 消息
↓
Session 创建(绑定到这个 thread)
↓
沙箱构建(Anthropic 托管的隔离环境)
↓
Claude 开始工作
这个设计选择看起来自然,但它排除了两个同样合理的替代方案:
| 方案 | 绑定到 | 优势 | 问题 |
|---|---|---|---|
| Per-User Session | 用户 | 你的所有 thread 共享上下文,不用重复解释 | 信息泄漏:你处理的 bug A 的细节会出现在你讨论 feature B 的上下文里 |
| Per-Channel Session | 频道 | channel 历史都在,上下文丰富 | 粒度太粗:同一频道里两个并行的 bug 讨论会互相干扰 |
| Per-Thread Session | thread | 精确隔离,协作自然,生命周期清晰 | 每次都要重建上下文——但 Channel Memory 解决了这个问题 |
Claude Tag 选了第三条路。核心判断是: thread 是团队协作的自然工作单元。一个 thread 就是一次讨论、一个问题、一个任务。它开始,它结束,它有明确的完成标准。
这和传统 Agent 框架的 per-conversation session 不同——per-conversation 是「你和 AI 的一次对话」,per-thread 是「一个团队围绕一个问题的一次协作」。区别在于:per-conversation 里只有你和 AI,per-thread 里,thread 里的任何人都能参与。
第二层:沙箱构建——一个没有钥匙的房间
Session 创建后,Anthropic 在自家基础设施上构建一个 隔离沙箱。这是 Claude 执行代码、读写文件、运行工具的地方。
关键设计只有一句话:
沙箱里没有任何凭证。
没有 API Key,没有 OAuth Token,没有数据库密码。Agent 在这个环境里能做的事情——跑 Python、写文件、调工具——全都在一个「干净」的运行时里执行。
┌──────────────────────────────────┐
│ Session Sandbox │
│ │
│ ┌──────────────────────────┐ │
│ │ Claude Runtime │ │
│ │ (推理 + 代码执行) │ │
│ │ 凭证: 无 │ │
│ └──────────┬───────────────┘ │
│ │ 出站请求 │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Agent Proxy │ │
│ │ (凭证边界注入) │ │
│ └──────────┬───────────────┘ │
└─────────────┼────────────────────┘
│ 带凭证的请求
▼
外部服务
为什么?因为 LLM 生成的代码是不可预测的。Agent 可能写一段 curl 命令,可能在 Python 里读环境变量,可能被 prompt injection 诱导去做非预期的事。如果凭证在沙箱里,任何一种情况都可能导致密钥泄漏。
这不是理论问题。我在 当 Agent 有了工牌 中举过钉钉群机器人的真实案例:API Key 写死在环境变量里,Agent 理论上可以读到并输出。Claude Tag 的设计从根本上消除了这个攻击面——不是限制 Agent 不能用凭证,而是让凭证根本不存在于 Agent 的运行环境中。
第三层:Agent Proxy——凭证只在边界出现
沙箱里 Claude 需要查 Datadog 的 p99 延迟数据。它发出一个到 api.datadoghq.com 的请求。
这个请求不会直接到达 Datadog。它先经过 Agent Proxy——沙箱和外部世界之间的唯一出口。
Proxy 做三件事:
出站请求 → Agent Proxy
├─ 命中 Connection Rule → 注入凭证 → 转发
├─ 命中 Allowlist(无 Connection)→ 无凭证转发
└─ 都不命中 → 阻断(host unreachable)
在这个场景里,管理员给 #platform-eng 配置了 Datadog 的 Connection。Proxy 从 write-only 的 Credential Store 里取出 Datadog API Key,在请求到达网络边界时注入,然后转发。
凭证从不进入沙箱。Claude 不知道 API Key 的值。 它只知道「我可以查 Datadog」。
这解决了两个问题:
- 安全:即使 Agent 被诱导输出凭证,它也输出不了——因为它从未拥有过凭证。
- 审计:所有经过 Proxy 的请求都有日志。你可以看到 Claude 访问了哪些外部服务、用了哪个 Connection、在什么时间。
在 当 Agent 有了工牌 中我详细讨论了 Agent Proxy 的工程实现和钉钉映射方案。这里补充一个细节: Proxy 的 default-deny 设计。沙箱里跑的代码——无论是 Claude 写的 Python 还是 curl 命令——所有出站请求都走同一个 Proxy。目标不在 Connection Rule 或 Allowlist 上的主机,不是「未认证」,而是 完全不可达。
第四层:协作——Thread 里的任何人都能 steer
9:04,Sam 中途加入 thread:「顺便查一下是不是和上周缓存改动有关?」
Sam 没有 @Claude。他只是在 thread 里回复了一条消息。但 Claude 读到了,并且把这个信息纳入了正在执行的工作。
这是 per-thread session 模型的核心优势: thread 里的人天然就是这次工作的参与者。不需要重新 @、不需要重新启动 session、不需要把人加到某个「项目」。你在 thread 里说话,Claude 就听到了。
Dana: @Claude 查一下今早部署的 diff... ← Session 启动
Claude: [checklist] ← 开始工作
Sam: 顺便查一下缓存改动? ← Claude 自动纳入
Claude: 已确认是 4f2c1 引入的 N+1... ← 综合两人输入
对比 per-user 模型:如果 Claude 绑定在 Dana 的 session 里,Sam 的输入要么被忽略,要么需要 Dana 手动转发。这在团队协作里是不可接受的。
Claude Tag 还有一个细节值得注意: 编辑或删除 thread 里的消息不会改变 Claude 已经接收到的内容。没有「撤回」机制——如果你想纠正,需要在 thread 里发一条新消息说明。这个设计选择了简单和可审计,而不是灵活性。
第五层:结果交付——PR 是 Agent 的作品,不是人的
9:06,Claude 在 thread 里贴出结果:
已确认是 4f2c1 引入的 N+1 查询。
PR #382 已开,CI 跑着。
[Open session in Claude]
这个 PR 的作者是 Claude GitHub App——不是 Dana,不是 Leo,不是 Sam。在 GitHub 的 commit 历史和 PR 页面上,你能清楚地看到这是 Claude 开的。
这回到了 Agent Identity 的核心:Agent 需要自己的身份,不只是为了审计,还为了 归属清晰。三个月后你 review 这个 PR,看到的是「Claude 在 #platform-eng 的 thread 里根据 Dana 的请求开了这个 PR」,而不是「Dana 开了一个她可能不记得的 PR」。
Claude Tag 还在每条回复的 footer 里放了一个「Open session in Claude」链接。点开可以看到这次 session 的完整记录——每一个 tool call、每一步推理。这是只读的,后续讨论回到 Slack thread 里进行。
Sandbox 销毁,Thread 持久
六分钟后,thread 安静下来。Claude 完成了任务,没人再回复。
这时候发生了什么?
沙箱被释放。 Anthropic 不再为这个 thread 维护计算资源。沙箱里的文件——如果 Claude 没有 push 到 branch 或 post 到 thread 里——就消失了。
但 Thread 还在。 Slack 里的消息、checklist、PR 链接、Claude 的回复——全部持久化。任何人回到这个 thread,都能看到完整的工作记录。
Channel Memory 也还在。 Claude 在这次工作中了解到的信息(比如这个项目的数据库结构、checkout 服务的架构)会被写入 Channel Memory。下次有人在 #platform-eng 里 @Claude 讨论相关问题时,Claude 可以从 Memory 里读取这些上下文,而不是从零开始。
临时 持久
┌───────┐ ┌──────────┐
Session │ 沙箱 │ │ │
│ 文件 │ │ │
└───────┘ │ Thread │
│ 消息 │
┌───────┐ │ PR │
Runtime │ 计算 │ │ 链接 │
│ 资源 │ │ │
└───────┘ │ Memory │
└──────────┘
这是一个干净的分层: 工作单元(thread)是持久的,执行环境(sandbox)是临时的。 知识通过 Channel Memory 跨 session 传递,而不是通过沙箱里的文件。
如果 thread 里有人再发一条消息,Anthropic 会重新构建一个沙箱,Claude 从 thread 历史和 Channel Memory 里恢复上下文,继续工作。新的沙箱和旧的是两个独立环境——它们之间没有直接的状态共享。
Thread = Unit of Work
回头看这个设计,Anthropic 做了一个不显眼但很深的架构决策: 把 Thread 定义为 Agent 的工作单元(Unit of Work)。
这不是显而易见的。大多数 Agent 框架把工作单元定义为:
- 一次对话 (ChatGPT、Claude.ai):人和 AI 的一问一答
- 一个项目 (Devin、某些 IDE Agent):一个代码库里的持续工作
- 一个任务 (Manus、各种 Task Agent):一个明确的 goal + 执行
Claude Tag 选了 一个 thread。为什么这是对的?
| 属性 | Thread | 对话 | 项目 | 任务 |
|---|---|---|---|---|
| 自然边界 | ✓ thread 有明确起止 | ✓ 对话有起止 | ✗ 项目是持续的 | ✓ 任务有起止 |
| 多人参与 | ✓ thread 里任何人可加入 | ✗ 通常单人 | △ 多人但需协调 | ✗ 通常单人 |
| 可见性 | ✓ channel 全员可见 | ✗ 私密 | △ 取决于配置 | ✗ 私密 |
| 粒度 | ✓ 一个问题 = 一个 thread | ✓ 一问一答 | ✗ 太粗 | ✓ 一个目标 |
| 归属 | ✓ 绑定到团队讨论 | ✗ 绑定到人 | △ 绑定到 repo | ✗ 绑定到人 |
Thread 同时满足五个属性。对话缺多人参与和可见性;项目粒度太粗;任务缺多人参与。
有人会反驳:thread 不就是 Slack 的一个 UI 组件吗?换个平台(飞书、Teams、钉钉)就不成立了。这个反驳成立——如果你只看到 UI 层面。但 Claude Tag 的设计不是「把 Agent 放进 thread 这个 UI 组件」,而是把 thread 提升为 系统架构的工作单元。Session 隔离、沙箱生命周期、凭证边界、Memory 作用域、审计归属——所有这些系统级概念都以 thread 为边界。换到钉钉群,等价的工作单元可能是「话题」(topic thread)或「卡片式任务」(一个任务卡片 = 一个 session)。重要的不是 Slack 的 thread 本身,而是 找到你平台上的自然工作单元,然后把所有系统级概念对齐到这个边界上。
更重要的是, thread 是 Slack 里团队工作的自然容器。不需要发明新概念——人们已经在 thread 里讨论问题、跟踪进度、做决策。Claude Tag 做的是把 Agent 嵌入这个已有的工作模式,而不是创造一个新的。
从六分钟看全局
回到开头那六分钟。现在你可以看到完整的图景:
@Claude
│
├─ 1. Session 启动(绑定到 thread,不是人)
│
├─ 2. Sandbox 构建(隔离环境,零凭证)
│
├─ 3. 工作循环
│ ├─ Claude 推理 + 写代码
│ ├─ 出站请求 → Agent Proxy → 注入凭证 → 外部服务
│ ├─ Sam 中途 steer → Claude 自动纳入
│ └─ Checklist 实时更新
│
├─ 4. 结果交付(PR 归属 Claude GitHub App)
│
└─ 5. 沙箱释放(Thread + Memory 持久)
这五步不是 Claude Tag 独有的——任何生产级 Agent 系统都需要类似的 session 管理。但 Claude Tag 的独特之处在于 每一步的边界选择:
- Session 绑 thread,不绑 user → 协作自然
- Sandbox 无凭证 → 安全默认
- Proxy default-deny → 网络隔离
- PR 归属 Agent → 审计清晰
- Sandbox 临时 + Memory 持久 → 正确的关注点分离
在 当 AI Agent 被拉进多个群 中我讨论过 session 隔离的重要性——不同群应该有不同的 Agent 实例。Claude Tag 把这个理念推进了一步:不只是不同群, 同一个群里的不同 thread 也是不同的 session。这是更细粒度的隔离,也是更自然的协作单元。
Claude Tag 还在 Public Beta,官方文档多处标注「may change before GA」。上面拆解的是当前设计的工程逻辑,最终 GA 版本可能有调整。但无论产品怎么演进, Thread = Unit of Work 这个设计选择本身,值得每个做 Agent 系统的人认真思考。
因为大多数 Agent 框架在做的事是「让 Agent 更聪明」——更好的推理、更多的工具、更长的上下文。但 Claude Tag 的六分钟告诉我们, 真正的突破可能不在模型层,而在架构层:你选择什么作为工作单元,决定了你的隔离性、协作性、持久性和审计能力——这些不是功能,是基础设施。
下次设计 Agent 系统时,先问自己一个问题:
我的工作单元是什么?我所有的系统级概念——隔离、权限、记忆、审计——是不是都对齐到了这个边界上?
如果答案是否,那你可能在一个错误的粒度上构建一切。
你的 Agent 系统的工作单元是什么?一次对话?一个项目?还是一个 thread?欢迎留言讨论。