周五下午 4 点。你打开钉钉,你的 D 群里「本周的重点事项」消息已经发了 24 小时。16 位负责人被 @,每个人的进展回复散落在三个地方:有人私聊你说了三段话,有人在群里回了一个 emoji,还有人到现在一个字没发。
你要整理的,是一份让所有人都看得懂、能 action 的结构化进度报告。
手动做这件事需要 2-3 小时(经验估算)。你打开 16 个单聊窗口 + 群聊消息列表,翻来翻去。做得再仔细,也跑不掉三个 bias: recency bias ——最后看到的记得最清, salience bias ——写了一大段的人得到最多篇幅,写了三个字的人被一笔带过。 survivorship bias ——没回复的人直接消失在你的视野里,而不是被明确标记。
我手动做了这件事好几个月。然后写了一个 Agent Skill 文件——不到 200 行的 Markdown,把你的工作流程像岗位说明书一样写清楚。跑起来之后的效果不是「更快了」,而是 总结质量比手动好:每条来源可溯源、16 人全覆盖、没回复的标 ⚠️ 而不是消失。从 12 人扩到 16 人时,只改了 4 行映射表。
这篇文章讲的就是这个案例——以及如何把 Loop Engineering(让 Agent 自主跑到终点的工程方法)从写代码的场景,搬到管理协调的场景。
这个工程能落地,最关键的工具是 钉钉 DWS(DingTalk Workspace CLI)。DWS 是 Agent 与钉钉的统一接口层,它的设计让钉钉对 Agent 友好、对开发者友好。无论你使用哪款 Agent——OpenClaw、Hermes、OpenCode、悟空、MuleRun、WorkBuddy——都能通过 DWS 应用这套 AI 驱动的管理方法。Agent 是 fungible 的,接口层才是杠杆。
| 对比维度 | 手动汇总 | Agent Skill |
|---|---|---|
| 耗时 | 2-3 小时(经验估算) | Agent 运行约 10 分钟 + 人工审阅约 5 分钟(基于实际运行经验) |
| 覆盖率 | 高概率遗漏 1-3 人 | 16 人全覆盖,未回复显式标 ⚠️ |
| 可溯源性 | 凭记忆,无法定位原文 | 每条标注「单聊 MM-DD HH:MM」来源 |
| 扩展性 | 增加 4 人 = 多翻 4 个窗口 | 改 4 行映射表 |
| 一致性 | 受情绪/疲劳影响 | 相同输入 ≈ 相同输出 |
管理工作流为什么「永远做不好」
管理者的日常工作中,有一类动作重复出现,且几乎永远做不好。它们的共同特征是:
- 定期发生:每周汇总进度、每月 check OKR、每季做项目健康度盘点
- 多信息源:从 N 个人的单聊 + 群聊 + 文档 + 项目管理工具中收集
- 结构化输出:最终产物是一张表、一份报告、一个状态仪表盘
这类工作的本质不是创造,而是 信息搬运 ——从 N 个地方把信息找出来,按固定的格式重新组装。
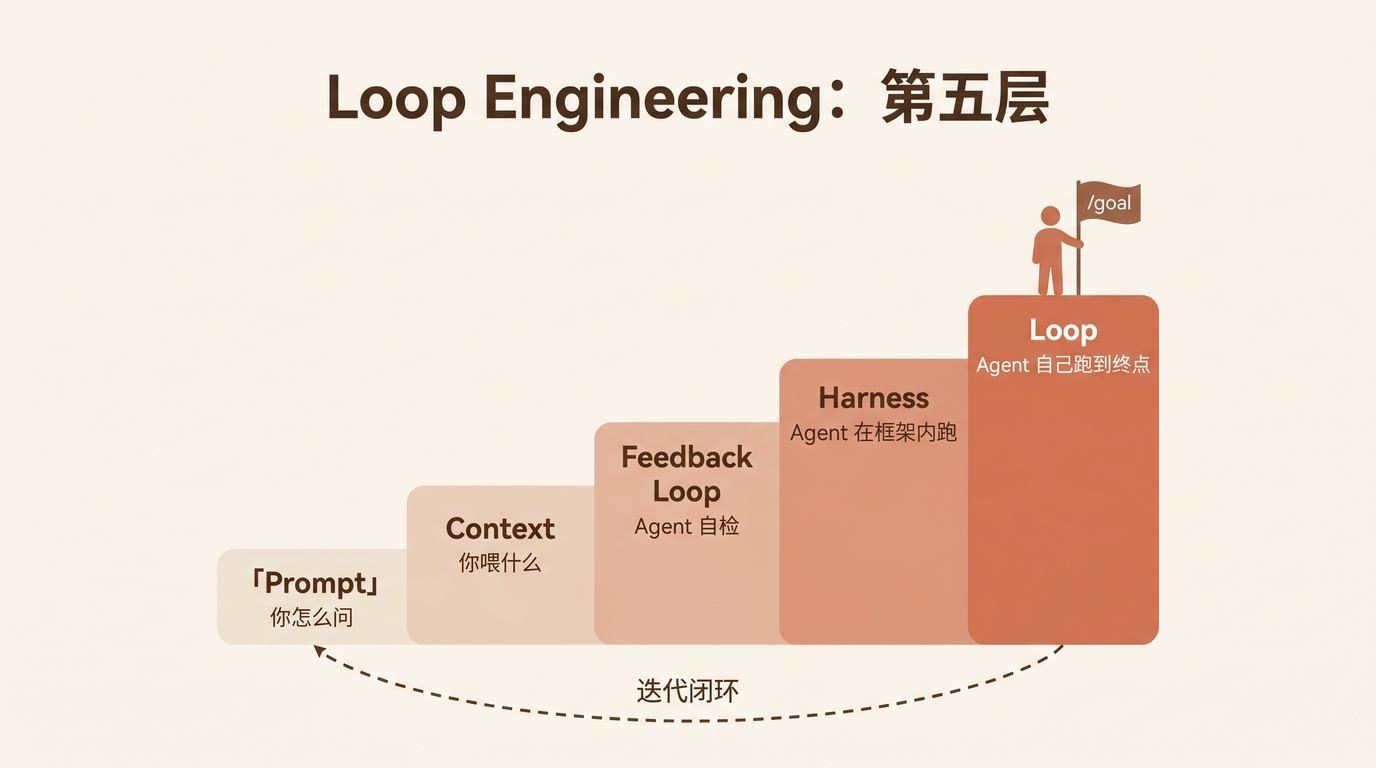
AI 能帮忙吗?理论上当然能。但大多数管理者使用 AI 的方式停在第一层:
Level 1: Prompt 一次性提问
「帮我总结一下本周进度」——然后自己把内容贴给 AI
每次都要重新教 AI 你的团队结构、输出格式、质量要求
这跟用 AI 当搜索引擎没有本质区别。每次都手动编排,每次都从头开始。
第二层是写自动化脚本——cron job + API 调用 + 数据处理。但编程门槛拦住了大多数管理者,而且脚本死板脆弱,团队一变就挂。
第三层,是这篇文章要说的事: Agent Skill Loop。
Level 1: Prompt — 每次手动提问,每次重新教
Level 2: 脚本自动化 — 写代码编排,脆弱且需要编程能力
Level 3: Agent Skill Loop — 写一份「岗位说明书」,AI 自己执行完整流程
把三层放在一起看:
| 维度 | Level 1: Prompt | Level 2: 脚本 | Level 3: Skill Loop |
|---|---|---|---|
| 每次执行成本 | 高(重新教 AI) | 低(自动运行) | 低(Agent 自动执行) |
| 编程门槛 | 无 | 高 | 无(写 Markdown) |
| 组织变更适应 | 每次重新教 | 改代码 | 改映射表 |
| 累积知识 | 无 | 有限 | 强(Skill 积累组织知识) |
| 适用者 | 所有人 | 工程师 | 管理者 ← |
什么是 Loop Engineering
Loop Engineering 的核心思想用一句话概括(来自 Geoffrey Huntley 的 Ralph Loop 实践):
The loop’s intelligence is in the loop, not in the agent. The agent is fungible. The loop is what makes it autonomous.
翻译给管理者的版本: 不要每次都教 AI 做事,而是写一份结构化的「岗位说明书」,让 AI 每次都按照这份说明书执行。
在 coding agent 领域,Loop Engineering 已经落地:你给 AI 一个目标(goal)和一个验证条件(怎么算「完成了」),AI 自己反复迭代直到满足条件。Anthropic 的 Boris Cherny 说:「I don’t prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.」——我的工作不再是给 AI 写 prompt,而是设计让 AI 自己运转的 loop。
管理协调场景完全适用同样的范式,只是目标不同——不是「让所有测试通过」,而是「让 16 个人中每个人的进度都被结构化为可追溯的格式」。
这个范式转换的价值不是更快,而是更好。后面展开。
在 用「好同事」模型理解人与 AI 的协作 中,我提出过一个类比:好的 AI 协作不是「下指令 - 收结果」的命令链,而是「给足上下文 - 让它自己做判断」的同事关系。Skill 就是把这个理念工程化了——你写一次说明书,AI 每次都带着完整的组织上下文干活。
管理者的第一个 Skill 长什么样
Agent Skill 本质上是一个 Markdown 文件(SKILL.md),用结构化的方式向 AI 描述一项工作的完整流程。你可以把它理解为一份岗位说明书——你写一次,AI Agent 每次都照着执行。
我的「每周进度汇总」Skill 核心结构如下:
文件头:告诉 AI 什么时候用这个 Skill
---
name: weekly-progress
description: |
D群每周重点事项进度汇总。
Use when user asks to "汇总周进度", "跟进重点事项", "本周进度",
"weekly progress", "pull progress from D群".
Orchestrates chat + aisearch skills to collect progress
from 16 responsible owners, then writes a structured
markdown summary to the work log wiki.
version: '1.0.0'
---
# generated by hugo AI
关键是 description 里的触发词。Agent 看到「汇总周进度」,就知道该加载这个 Skill。
流水线:9 步完整流程
┌─────────────────────────────────────────────────────────┐
│ 9 步工作流水线 │
├─────────────────────────────────────────────────────────┤
│ │
│ ① 定位本周计划 │
│ └─ 在D群中找到本周重点事项消息,提取任务清单 │
│ ↓ │
│ ② 解析负责人列表 │
│ └─ 从 @mentions 中提取所有负责人(当前 16 人) │
│ ↓ │
│ ③ 查找负责人身份 │
│ └─ 通过 AI 搜索获取每位负责人的 userId / chatId │
│ ↓ │
│ ④ 并行拉取 16 路单聊 ← 核心价值:16 人同时发起 │
│ └─ 从本周计划发布时间起,拉取每人与你的单聊记录 │
│ ↓ │
│ ⑤ 补充群聊消息 │
│ └─ 有些进度反馈在群聊中,需筛选补充 │
│ ↓ │
│ ⑥ 汇总生成进度报告 │
│ └─ 按统一格式输出,标注来源、标记 ⚠️ / ✅ │
│ ↓ │
│ ⑦ 写入工作日志 Wiki │
│ └─ 按财年/季度/月/周编号存档 │
│ ↓ │
│ ⑧ 发送 → 需用户确认 │
│ ⑨ 催办未回复者 → 需用户确认 │
│ │
└─────────────────────────────────────────────────────────┘
注意 ⑧ 和 ⑨ 的设计: 对外动作(发消息、催办)必须由人确认。Agent 完成了所有信息收集和整理,但最终是否发出,管理者拍板。这是 human-in-the-loop 在管理场景的正确位置。
人员映射表:缓存避免重复查询
Skill 中缓存了每位负责人的身份信息,这样后续执行时不用每次都重新查找:
| 花名 | userId | chatId |
|------|--------|--------|
| P | 080xxx | D5Mext... |
| D | — | DdcJr...HTT... |
| X | 112xxx | DYiS9... |
| Q | 034xxx | DQs2R... |
| ... | ... | ... |
这张表的价值是 累积知识。第一次运行时 Agent 需要逐个查找 16 人的身份信息。后续运行直接用缓存,除非组织变动才需要更新。这就是 Skill 和一次性 prompt 的本质区别——Skill 会积累,prompt 每次归零。
输出模板:Agent 按照什么格式交付
## <花名>
**来源:** 单聊 MM-DD HH:MM ~ HH:MM
- **<事项1>:** <进展描述>
- **<事项2>:** <进展描述>
这个模板强制 Agent 对每个事项单独说明进展,而不是笼统地说「XX 在推进」。同时, 来源 字段让管理者能一眼看到这份信息从何而来——不是凭空生成的,是有对话记录支撑的。
为什么 Agent 做得比人好
这是这篇文章最违反直觉的部分。大多数人以为 AI 帮管理者的方式是帮你写文档、润色 PPT(内容生成)。但进度汇总这件事上,AI 不只是更快——它做得比人好。
消除三种系统性偏差
手动汇总是 有损压缩。你不可避免地会:
- 给最后看到的信息更大篇幅(recency bias)
- 给写得长、写得有感染力的人更多篇幅(salience bias)
- 忘记那些没回复的人,而不是主动标记他们的沉默(survivorship bias)
Agent 不存在这些问题。16 人逐一遍历,每人一个 section,没回复的显式标注 ⚠️。不是 Agent 比你有同理心,而是 结构化的流水线天然强制全覆盖。
「没回复」是一种有价值的输出
手动汇总时,没回复的人通常就消失了——报告里不会有「XX 未反馈」这一条。但 Agent Skill 的输出模板里有一段专门的区域:
## ⚠️ 仍需跟进
- **汇报人 M** — 未反馈,已标记
- **汇报人 N** — 仅群聊确认 emoji,无实质回复
沉默本身就是一种信号。Skill 把这个信号显式化了——管理者一眼就能看到谁需要跟进,而不是在潜意识里「忘了这个人」。
这个设计对应的管理原则是 对人不提要求,就是对组织不负责——Agent 的 ⚠️ 标记,等价于管理者给每个 owner 设定的 显式期望:你必须反馈,不反馈会被记录和追踪。
每条汇总可溯源
输出模板里的 来源: 字段不是装饰。它的实际作用是对话双方都知道 Agent 引用的原始材料是什么:
## 汇报人 A
**来源:** 单聊 06-30 14:22 ~ 16:05
- **客户定制需求:** 已完成首批 3 个客户对接,预计 0708 提测
- **性能优化:** CPU 占用从 45% 降到 22%,已灰度验证
管理者看到的是 A 自己的原话提炼,不是管理者的二次转述。A 本人收到这份汇总时,也能确认「对,这是我说的」。这避免了管理者在整理时无意间添加自己的理解和判断——保留原始信号,减少信号失真。
Agent 的汇总原则也很克制:「以负责人自己发送的文字为准,不添加主观评价。保留关键时间节点(如 0708 = 7 月 8 日)。保留具体数据(如「对标 99.5%」「增长 170%」)。」这些规则,手动整理时其实你也想做,但 16 个人的信息量让你很难每次都做到。Agent 没有「累了想偷懒」的时刻。
并行采集无信息泄露
16 路单聊同时拉起。手动翻聊天记录时,你很容易在 A 的对话里看到 B 的消息然后顺手去回复,20 分钟后忘了自己看到 A 的哪一段了。Agent 不会。每条消息都被处理,不会因为你的注意力被别的事情打断而丢失。
坑和限制
这个 Skill 不是万能的,有几个地方你必须知道:
信息质量取决于输入质量。 如果负责人在单聊里只发了「收到」和 emoji,Agent 提取不出有用的进展信息。这和人肉整理的限制一样——巧妇难为无米之炊。Agent 能做的是把「没回复」这件事显式标记出来,而不是假装它不存在。
不适合一次性或低频任务。 如果你的团队只开一次复盘会,写个一次性 prompt 就够了。Skill 的价值来自重复使用——写一次,跑无限次。低于每月一次的动作,投入产出比不高。
需要基础工具链支撑。 这个案例依赖钉钉 CLI(dws)能拉取单聊和群聊消息。如果你的 IM 工具没有对应的 API,Skill 无法落地。好消息是,主流的企业 IM 工具(钉钉、飞书、企微、Slack)都在快速补齐这个能力。
敏感信息需要权限控制。 Agent 会读取 16 人的私聊记录,SKILL.md 里缓存了 userId 和 chatId。这些是敏感信息,Skill 文件本身需要权限管控,不能随便 share。
Skill 即组织配置
Skill 不只是一份「怎么用 AI」的说明书,它是 组织知识的持久化载体。它会随时间增值。
最有说服力的例子:团队从 12 人扩到 16 人时的实际变更。git diff 只有这些行:
- Orchestrates ... 12 responsible owners ...
+ Orchestrates ... 16 responsible owners ...
- 从本周计划消息中提取所有 @ 的人员,典型 12 人:
- A、B、C、D、E、F、G、H、I、J、K、L
+ 从本周计划消息中提取所有 @ 的人员,典型 16 人:
+ A、B、C、D、E、F、G、H、I、J、K、L、M、N、O、P
+| M | — | DRiPy... |
+| N | — | DqnA1... |
+| O | — | DbWFl... |
+| P | — | DFWni... |
4 行映射表加 2 行描述更新。完事。
对比手动做法:你需要记住新增了 4 个人,找到他们的联系方式,记住他们的 chatId,更新你的心理模型和整理模板,每次整理时多覆盖 4 个人。全靠脑子。下次换一个实习生来帮忙整理?又要重新教一遍。
这就是 Skill 和 prompt 的本质区别: Skill 积累组织知识,prompt 每次归零。 我在 SKILL.md 不是文档,是编译器 中写过:Skill 把隐性的协调知识编译成 Agent 可执行的指令,组织变动时只需更新编译输入,不需要重新教 Agent 一切。
当这 4 位新同事离开、又有人补进来时,我只需要再改 4 行映射表。Agent 的其余 8 步流水线完全不用动。
你的管理动作能写成 Skill 吗
这个 weekly-progress 案例是具体的,但模式是通用的。三个特征同时满足的协调动作,都适合写成 Agent Skill:
| 特征 | 你的场景里有吗? |
|---|---|
| 定期执行 | 每周 / 每月 / 每季固定要做 |
| 多信息源 | 需要从 3 个以上的系统或对话中收集数据 |
| 结构化输出 | 最终产物是报告、表格、状态列表等固定格式 |
三个特征齐备的协调动作,可以用同一个 Loop 模式套:
┌──────────────────────────────────────┐
│ Agent Skill Loop │
│ │
│ Cron 触发 │
│ ↓ │
│ 采集 N 个信息源 │
│ ↓ │
│ 结构化汇总(按 Skill 指定的格式) │
│ ↓ │
│ 分发 / 存档 │
│ ↓ │
│ ⚠️ 异常 → 等管理者确认后动作 │
│ │
└──────────────────────────────────────┘
下面是三个其他管理场景,都可以套用同样的 Skill 模式:
OKR 月度 check-in
触发:每月 1 号 / cron
输入:团队 OKR 数据 + 各 owner 单聊记录
流程:提取 KR 当前值 → 对比上月 → 标记红黄绿 → 生成偏离分析
输出:结构化 OKR 仪表盘 + ⚠️ 偏离项 + owner 原话引用
跨项目风险扫描
触发:每周一 / cron
输入:N 个项目群的最近一周消息
流程:提取风险词(延期/阻塞/缺人/紧急) → 按项目聚合 → 标红
输出:风险清单表格 + 严重程度判断 + 建议行动
会议纪要 + action items 追踪
触发:会后 1 小时 / webhook
输入:会议听记(转写文本)
流程:提取决策 → 提取 action items → 匹配负责人 → 生成待办
输出:结构化纪要 + action items 列表 + 自动创建的待办
你不需要会编程。你需要做的是:
- 识别 你每周重复做的 3 个协调动作
- 写一份 Markdown,描述步骤、信息源、输出格式、特殊处理——就像你在写一份交给新助理的岗位说明书
- 让 AI Agent 每次都按这份「说明书」执行
一个升维问题
如果你能把自己每周 2-3 小时的协调类工作编码为 Agent Skill,省下来的时间,你会用来做什么?
大多数管理者的直觉反应是「多做几件事」。但真正值得问的问题是: 当信息搬运这件事被系统接管后,管理者剩下的不可替代价值是什么?
我倾向于认为答案是三件事: 判断 (这个进度是正常的还是危险的)、 决策 (要不要在某个节点介入)、 人 (1:1 里对方没说出口的那个问题)。
这三件事,Agent 目前都做不了。但它能把你的时间从搬运腾给这三件事。
你每周有多少时间花在信息搬运上?如果这部分被 Agent 拿走,你会把时间投到哪?欢迎留言讨论。