每周一早上,我在董事群发一条消息,列出 16 位高管本周的重点事项。
接下来一周,我靠记忆和同事的自觉来掌握进度。有人及时反馈,有人到周五才想起有这回事,有人直接忘了。
上周五,我试了一下让 AI Agent 帮我跟。结果超出预期。
![]()
每周一早上,我在董事群发一条消息,列出 16 位高管本周的重点事项。
接下来一周,我靠记忆和同事的自觉来掌握进度。有人及时反馈,有人到周五才想起有这回事,有人直接忘了。
上周五,我试了一下让 AI Agent 帮我跟。结果超出预期。
![]()
我的桌面上常年跑着两个 Agent。
一个是 OpenCode,配了 GLM 5.2,专职写代码。它的 Server API 挂在远端机器上,通过 HTTP Basic Auth 暴露端点,我可以在任何地方给它发任务。另一个是 Hermes Agent,配了 Qwen 3.7 Max,管我的知识库、笔记、博客——它认识我写的每一篇文章,记得我的每一个偏好。
它们不在同一台机器上,不用同一个框架,甚至不知道对方的「进程」在哪里。但它们每天都在钉钉上协作——有时候单聊发任务,有时候在群里 @ 对方。
上个月我让 Hermes 写一篇关于 Harness 工程的博客。它从知识库里检索素材、搭好大纲、写好正文,但缺一段能跑的 Python 示例代码。Hermes 没有犹豫,直接在钉钉群里 @ OpenCode:「帮我写一个 Agent 反馈循环的 Python 实现,要求用 dataclass + Protocol,带类型注解。」OpenCode 花了 40 秒生成代码,跑通了测试,把结果贴回群里。Hermes 拿到代码,整合进文章,发布。
整个过程,我没有切过一次窗口。
[Read More]上周三晚上 10 点,我的钉钉弹出一条单聊消息。
不是同事发的。是我的数字员工:「今天帮你整理了 12 篇知识库笔记,其中 3 篇和上周发布的博客有观点冲突,需要你确认是否更新。另外,昨天你让我跟进的那个技术方案,对方已经回复了,我把要点整理好了,你看下?」
我花了 30 秒看完,回了两个字:「更新。」
然后它就去执行了。
[Read More]上个月面试一个候选人,简历很漂亮,做过三年 LLM 应用开发。我问他:「你觉得你做的东西,本质上是在交付什么?」
他说:「交付模型能力。把 LLM 的能力封装成 API,让业务方能用。」
我又问:「如果业务方说,我要一个能自主完成端到端任务的系统,不只是回答问题——你交付的东西能做到吗?」
他愣了一下:「那得加很多工程,不只是调 API。」
我说:对,这就是我今天想聊的——当交付物从「模型能力」变成「自主系统」时,你的工程标准该是什么样。
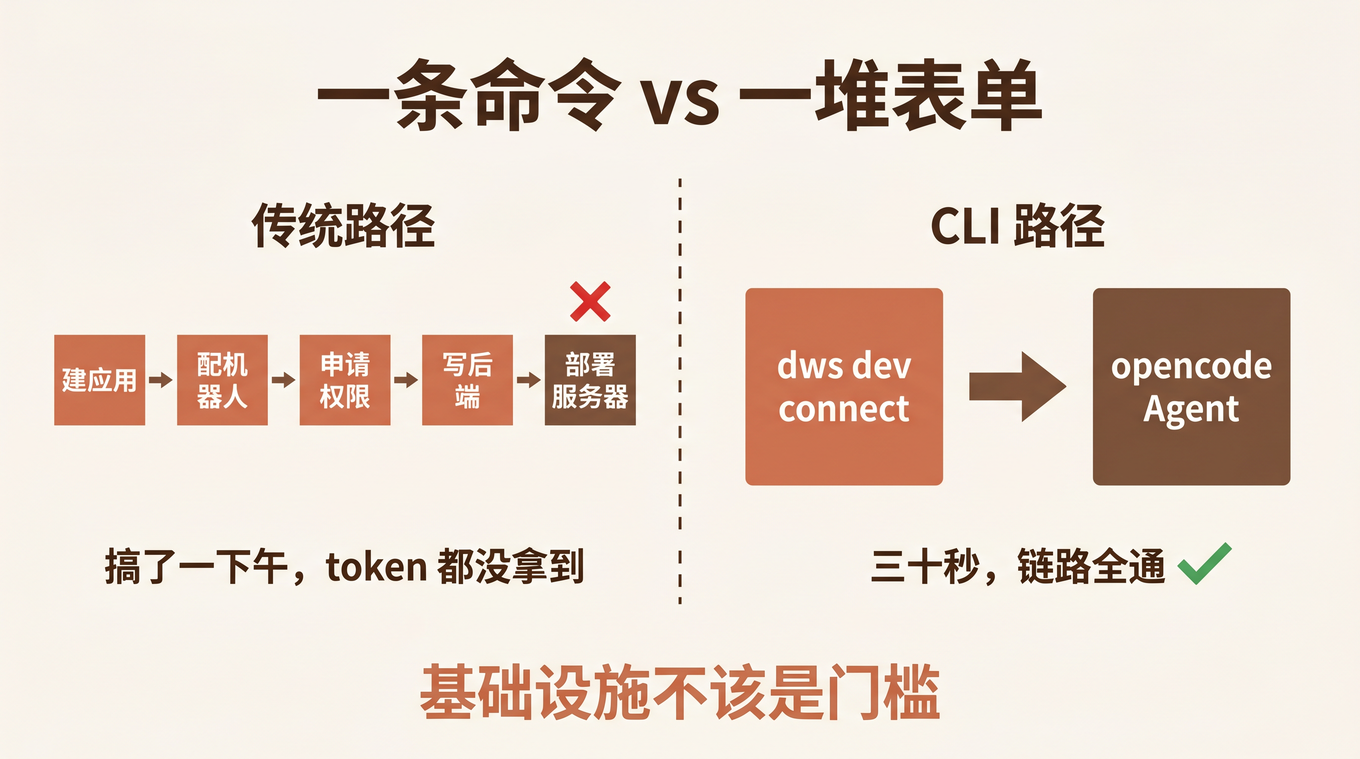
[Read More]上周一个钉钉校招生来找我抱怨。他帮在校的师弟调毕业设计,想做一个「钉钉里 @ 一下机器人,就能让本地 Agent 帮忙跑数据分析、回传结果」的小系统。思路很清楚,卡壳的地方很尴尬——卡在了第一步:钉钉开放平台管理后台。
他注册了开发者账号,进了那个后台,对着「企业内部应用 → 创建应用 → 机器人配置 → 权限申请 → 版本发布」一长串表单发呆,搞了一下午连机器人 token 都没拿到。他来找我吐槽:「是不是还得租个服务器写个后端,机器人才能跑起来?这门槛也太高了吧。」
我把他从那个后台里拽了出来,敲了一条命令给他看:
dws dev connect --channel opencode --unified-app-id <你的应用ID>
三十秒后,他在钉钉里 @ 那个机器人说「hi」,本地 opencode 接到消息、生成回复、回传钉钉,整个链路通了。没有碰管理后台,没有写后端服务,没有租服务器。
这篇文章就是把这个过程从浅到深讲一遍: 先一条命令把通用 Agent 接进钉钉,再用 opencode 本体搭出一个鲁棒、自愈、能实时回传进度的垂直 Agent 协同系统。面向的就是在校同学——你有一台笔记本、会用命令行、装了 opencode,就能跟着跑通。
上个月,一个做消费品牌的朋友找我聊他们的 AI 项目。
他们花了三个月,让技术团队给 CEO 做了一个「数字分身」——能模仿 CEO 的语气给全员发周报、回答战略问题、甚至在新人培训里做公司介绍。演示那天,CEO 本人看了都觉得「挺像我的」。
然后他问了我一个问题:「这个东西,除了我自己觉得好玩,到底该给谁用?」
我说:你做了一个 分身,但你需要的是一个 员工。
他愣住了。
这不是个例。我观察到大量企业在启动 AI Agent 项目时,第一步就搞混了这两个概念——不是因为技术理解不够,而是因为 没有想清楚锚点在哪。
![]()
上周 review 一个团队的代码。他们想做一个能自主修 bug 的 Agent,架构设计得很漂亮,模型选的也是最新的。但 Agent 跑起来后,改完代码就停了——它不知道怎么验证自己改得对不对。
我问他们:「测试覆盖率多少?」
「大概 30%,而且跑得慢,本地跑一次要 15 分钟。」
「日志呢?有结构化日志吗?」
「有,但格式不太统一,有时候打 JSON,有时候打纯文本。」
「Health Check 呢?」
「有个 /ping 接口,返回 200。」
我说:那你的 Agent 改完代码之后,怎么知道改对了?怎么知道部署上去没炸?怎么知道要不要回滚?
他想了想:「只能让人看一眼。」
我说:对,这就是问题所在——你的系统不是为 Agent 设计的,是为人设计的。 人可以用经验判断「这个改动应该没问题」,Agent 不行。Agent 只能依赖 可以调用、可以验证、可以反馈 的能力。
[Read More]上周一个朋友跟我说,他们公司「上线了数字员工」。
我问:干了什么?
他说:在 HR 群加了个机器人,员工可以问请假政策、查工资条、提交报销。
我问:那和三年前上线的 FAQ 机器人有什么区别?
他愣了几秒:「……好像就多了个大模型,回答更像人话了。」
这不是段子。2026 年,钉钉、飞书、企业微信上跑着成千上万个「数字员工」,大多数落地形态惊人地相似: 一个大模型,挂在一个群里,回答预设范围内的问题。 换了个「数字员工」的名字,骨子里还是个聊天机器人。
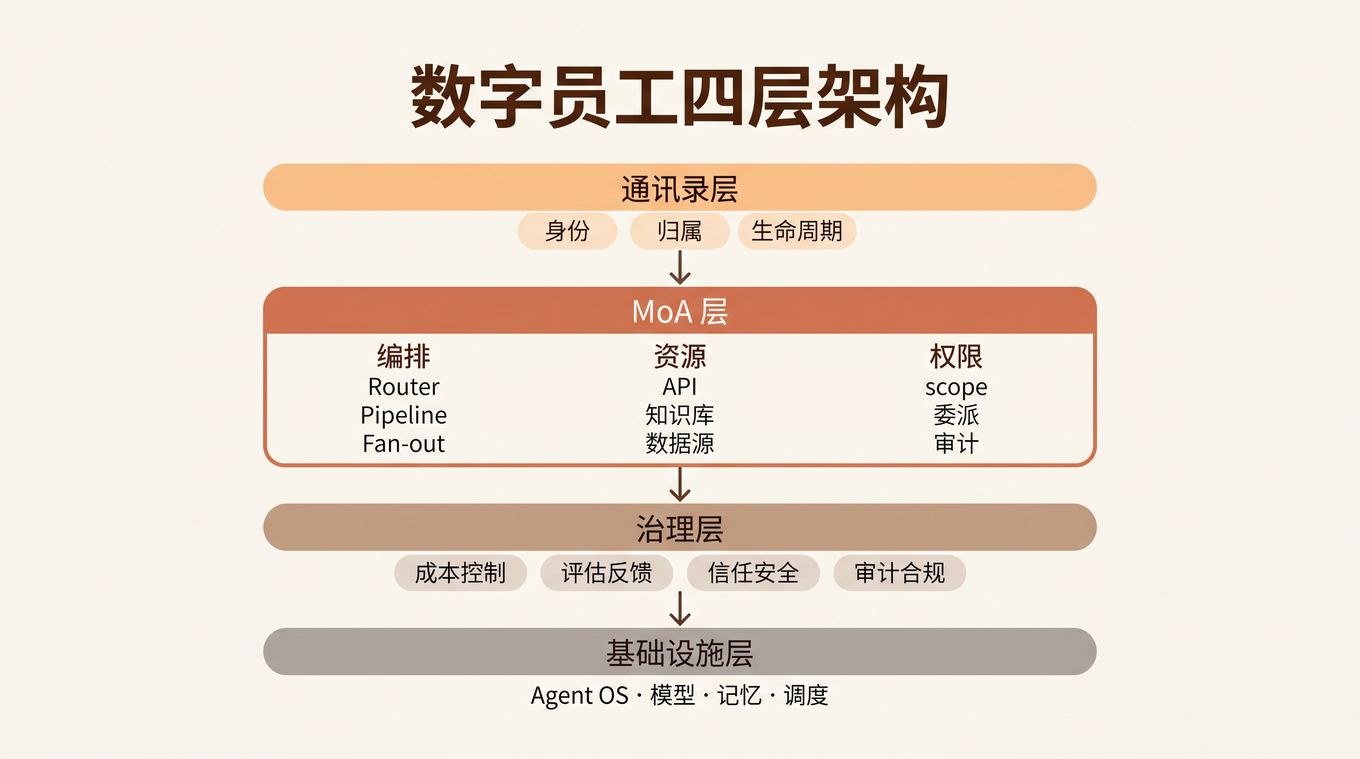
真正的数字员工应该是什么样子?Anthropic 的 Claude Tag 给出了一个方向——Agent 以组织成员身份加入 Slack,有自己的记忆、权限和行为日志。我在 Claude Tag 的 Agent Identity:为什么这是 Agent 时代的 OAuth 中详细分析过这个「身份层」的设计。
但身份只是第一步。把 Agent 的名字写进通讯录,工程量大概只占 10%。剩下的 90% 是什么?
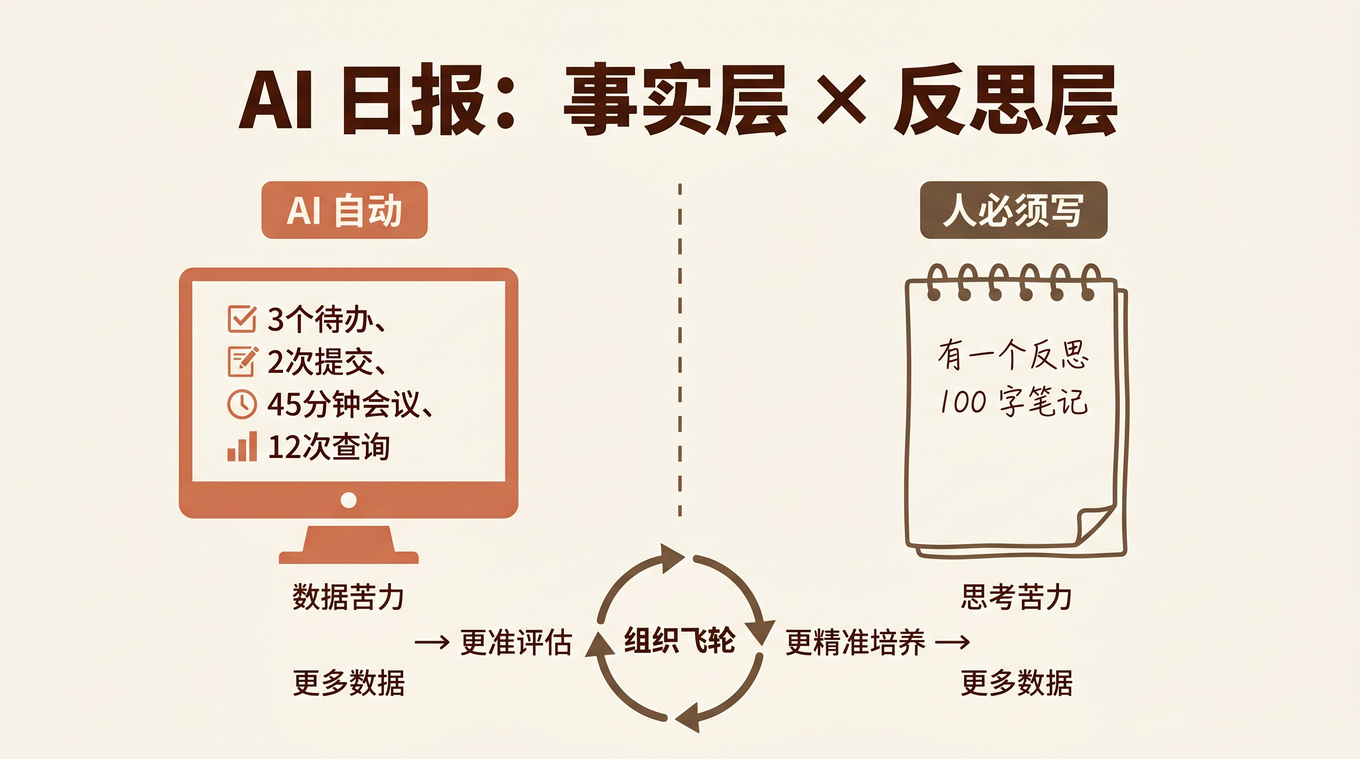
昨天一个校招生在钉钉上问我:「日报能不能让 AI 帮我写?我每天花 30 分钟凑那些东西,感觉像在演戏。」
我没有急着回答「能」或「不能」。因为这个问题的背后藏着一个更大的矛盾——
如果日报真的只是「写给主管看的汇报」,那让 AI 写完全合理,甚至应该让 AI 写。但如果日报的价值远不止于此,那用 AI 替代的可能恰恰是最不该被替代的部分。
问题不是「AI 能不能写日报」,而是: 在一个 AI 能替你写字的时代,人还应该写什么?
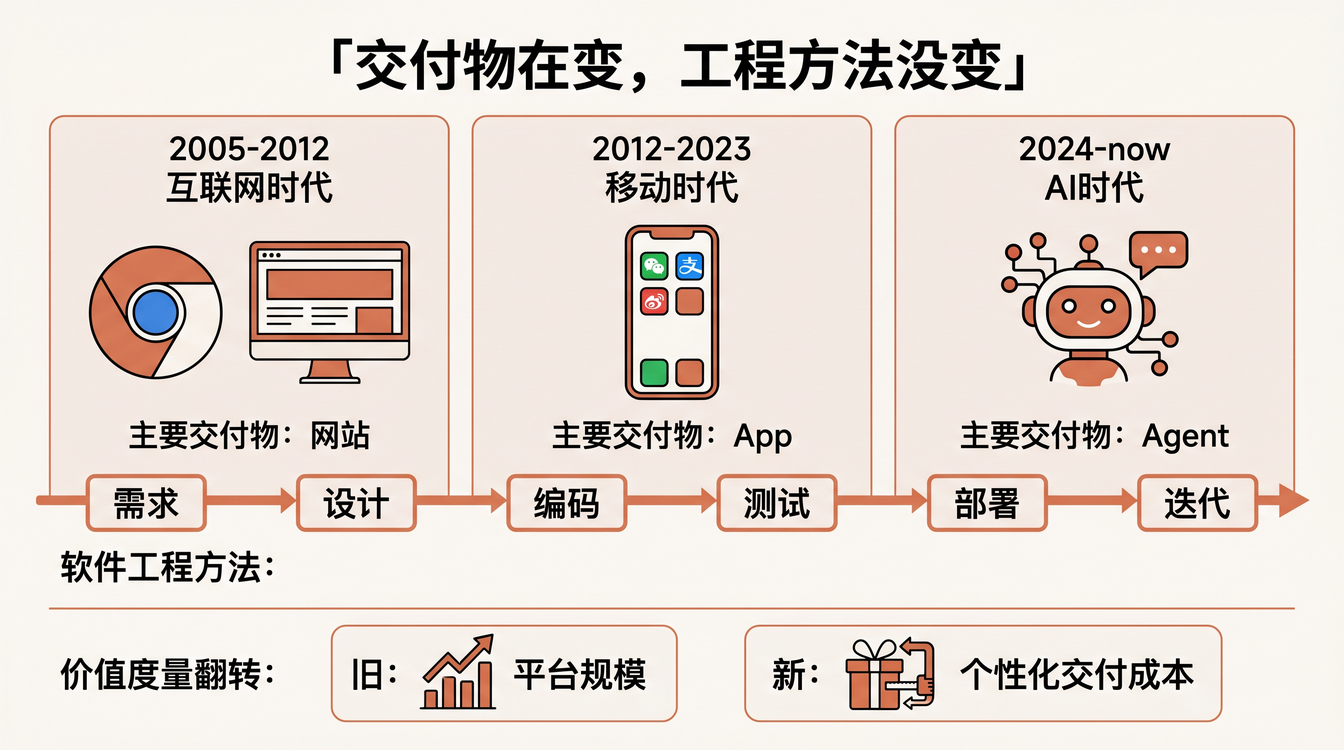
上周和一个做了十五年全栈的朋友吃饭。他最近从大厂出来,拿到两个 offer:一个是去创业公司做 Agent,一个是去传统企业做数字化。他选了后者,理由是「Agent 太新了,不确定性太大」。
我问他:你觉得做网站和做 App 有什么区别?
他想了想:「差不多,都是接需求、写代码、上线、迭代。」
我又问:那做 Agent 呢?
他说:「也是接需求、写代码、上线、迭代。只是交付物从页面变成了 Agent。」
他自己把答案说出来了,但没意识到这句话有多重要。