上个月一个前同事找我吃饭。他在某大厂做了八年后端,刚被裁。手里有两个选择:去创业公司做 Agent 工程师,或者自己干。
他问我:「自己干的话,我该做什么?」
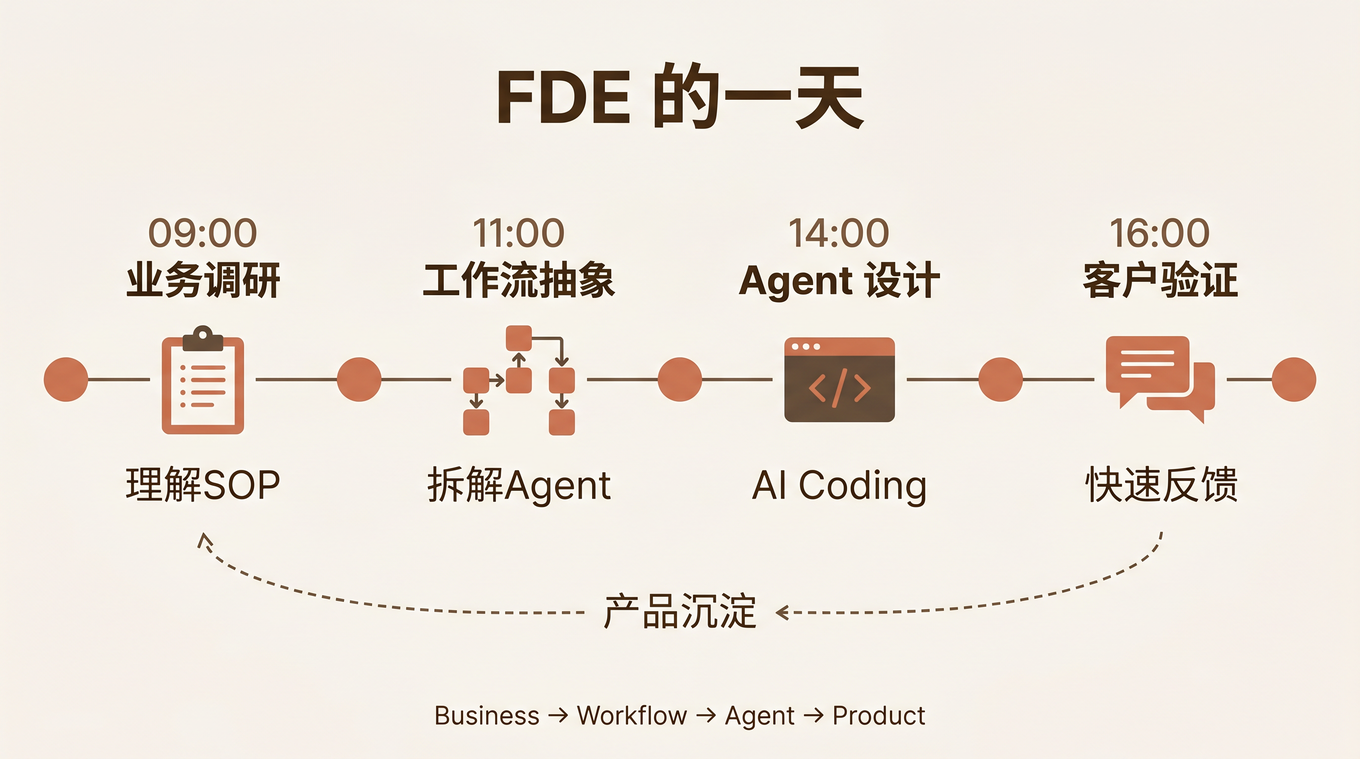
我说:你做过钉钉 FDE 那种到客户现场交付 Agent 的项目吗?
他说没有,只在公司内部做过。
我说:那你差的就是三个项目。做完三个,你就可以一个人开公司了。
他愣了一下:「三个就够了?」
够了。但不是随便三个。
上个月一个前同事找我吃饭。他在某大厂做了八年后端,刚被裁。手里有两个选择:去创业公司做 Agent 工程师,或者自己干。
他问我:「自己干的话,我该做什么?」
我说:你做过钉钉 FDE 那种到客户现场交付 Agent 的项目吗?
他说没有,只在公司内部做过。
我说:那你差的就是三个项目。做完三个,你就可以一个人开公司了。
他愣了一下:「三个就够了?」
够了。但不是随便三个。
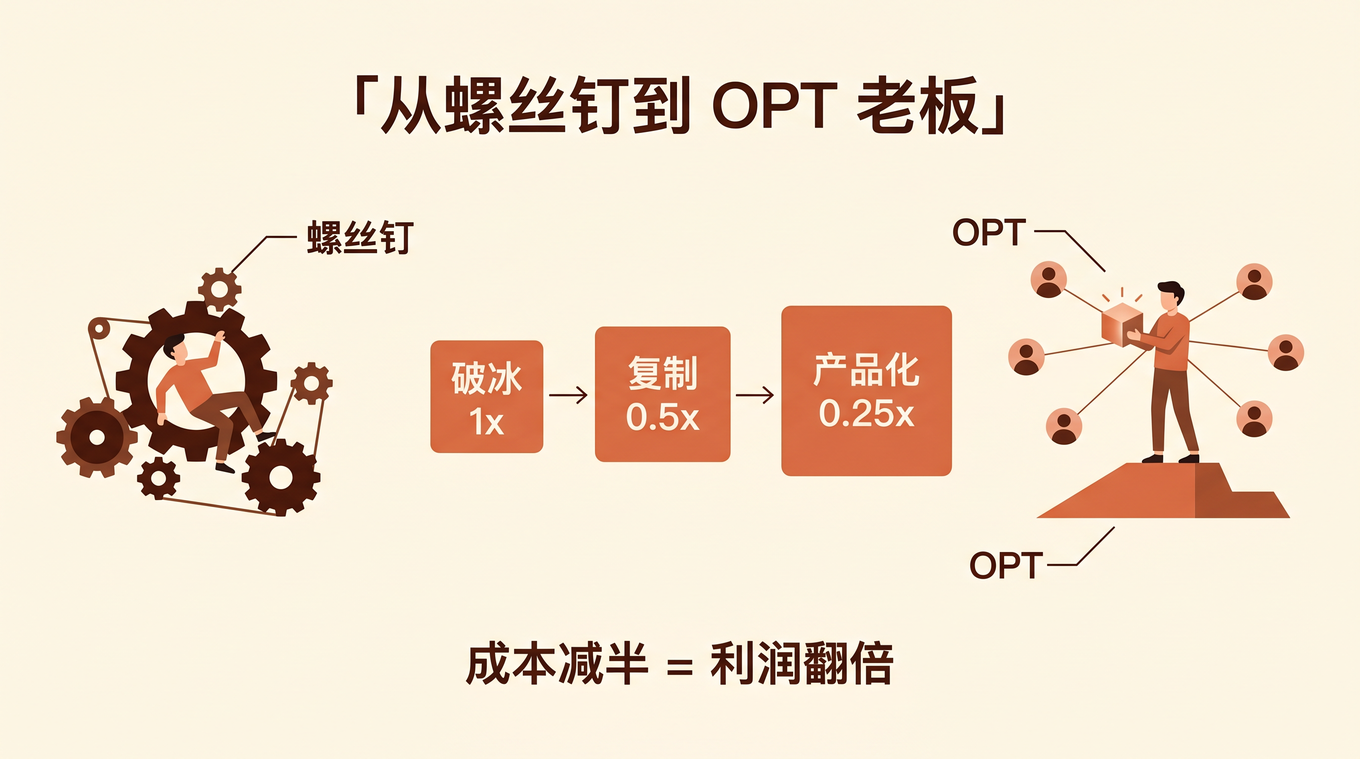
接着 销售流程 AI 化系列 的汽配分销商案例讲。
上一篇讲的是理念:解决方案对象、拜访质检、履约 SOP 编译。这一篇讲落地:FDE 到客户现场,怎么用基础设施在一天内把这些理念变成可运行的 Agent。
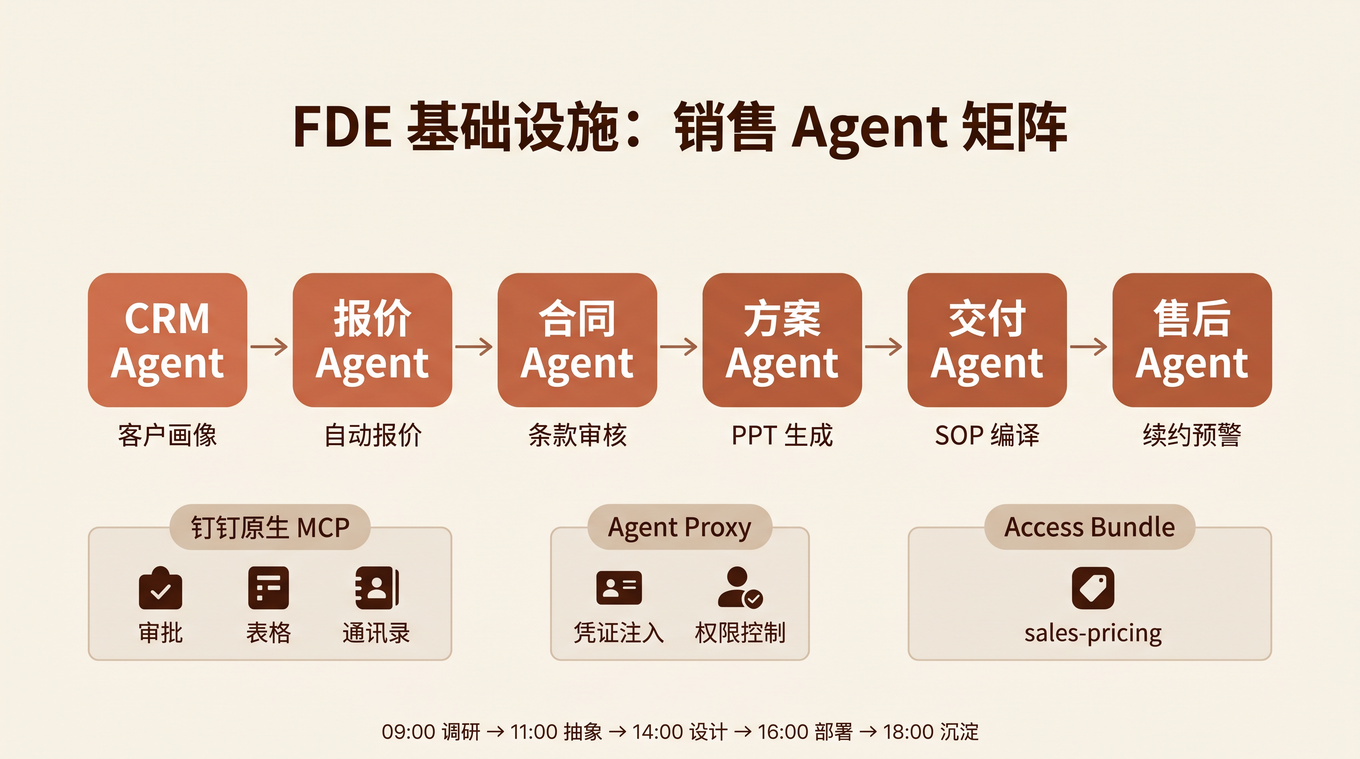
老周(售前)和小林(FDE)一起到了汽配客户现场。客户有 200 家门店,销售团队 30 人,每天处理 50+ 客户咨询、20+ 报价单、10+ 合同审批。
问题是:销售流程全靠人肉,信息散落在微信、Excel、邮件里,老周那份 80 页 PPT 签完单就死了。
周一早上,#platform-eng 频道。
Leo 发了一条消息:「checkout 今早变慢了,有人遇到吗?」
Dana 秒回:「我也是。」然后她 @了 Claude:「查一下今早部署的 diff,对比延迟数据,找出原因。」
接下来六分钟里发生的事,值得每个做 Agent 架构的人仔细看一遍。
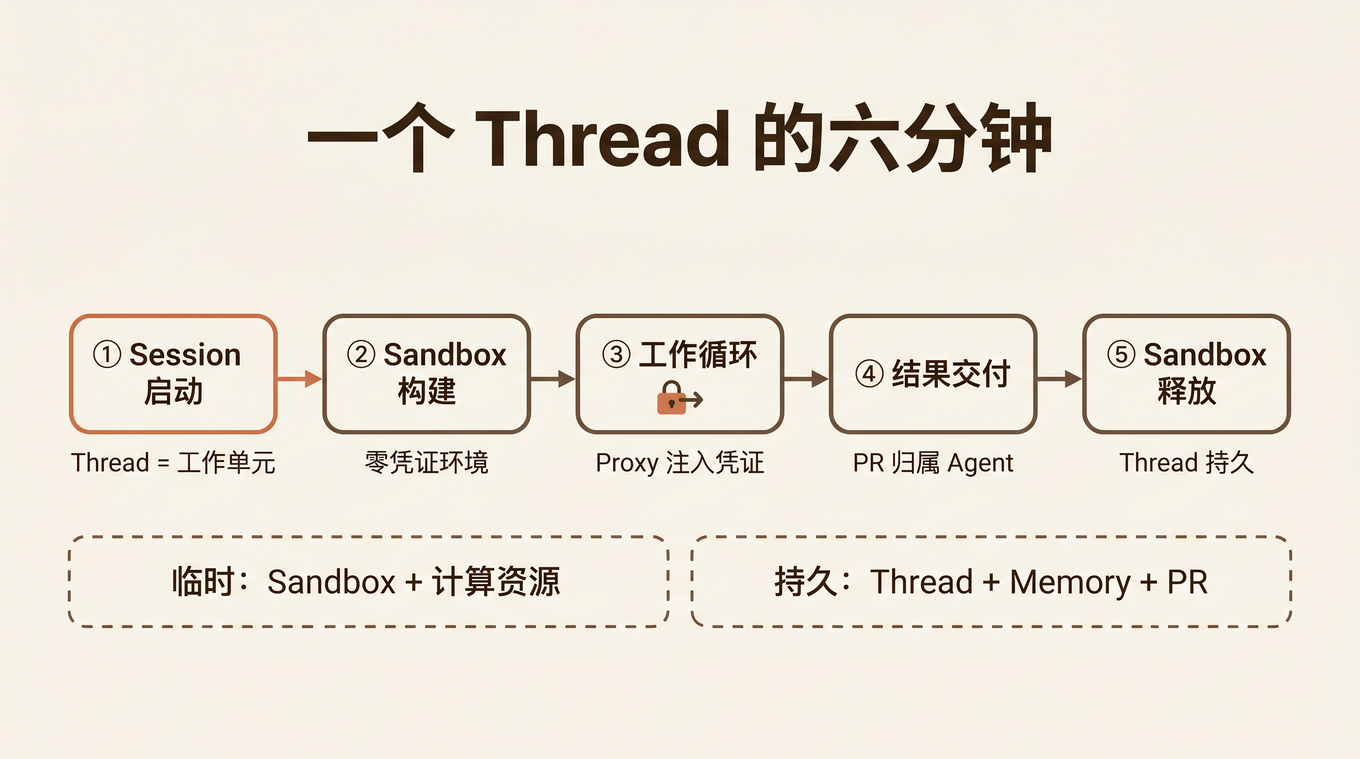
9:02 Dana @Claude — Session 启动
9:02 Claude: "is thinking..." — 沙箱构建中
9:03 Claude 贴出 checklist:
✅ 拉 Datadog p99 延迟数据
✅ 对比 deploy 4f2c1 和 main 的 diff
⏳ 本地复现慢查询
⏳ 开 PR 修复
9:04 Sam 中途加入:「顺便查一下是不是和上周缓存改动有关?」
9:06 Claude: 已确认是 4f2c1 引入的 N+1 查询,PR #382 已开,CI 跑着
六分钟。从发现慢查询到 PR 开出。
[Read More]周一早上,运营群里有人 @了运营 Agent:「帮我看看上周退款率为什么涨了」。
Agent 开始干活。它先查了 AI 表格里的退款明细,又调了客服工单系统的投诉分类,接着跑了一段 SQL 算出各渠道的退款占比,最后生成一份带趋势图的分析报告发到群里。整个过程 40 分钟,中间还主动追问了一句:「要不要把退款金额 > 500 的单独拉出来?」
报告质量不错。但安全团队事后审计时发现了三个问题:
read:all,理论上 Agent 可以读任何人的工单。这是一个典型场景,我在不同企业里见过不同程度的版本。
在 Claude Tag 的 Agent Identity:为什么这是 Agent 时代的 OAuth 中,我讨论了 Agent 为什么需要自己的身份。这篇接着往下走: 当 Agent 进入钉钉群,权限、凭证、审计这套架构具体怎么设计?
周一早上九点,小林到了客户的运营部。
他不是来做产品演示的,也不是来签合同的。他的工牌上写的是「Forward Deployed Engineer」——一个在钉钉内部新设立的岗位,外部还没有对应的职称。
上周客户提了一个需求:「每天有 20 个人整理会议纪要,能不能用 AI 提效?」
普通工程师听到这句话,想到的是做一个会议纪要工具。
小林想到的是:
会议
↓
纪要
↓
任务拆解
↓
责任人
↓
审批
↓
提醒
↓
知识沉淀
他要做的不是一个纪要工具,而是一个 会议 Agent。
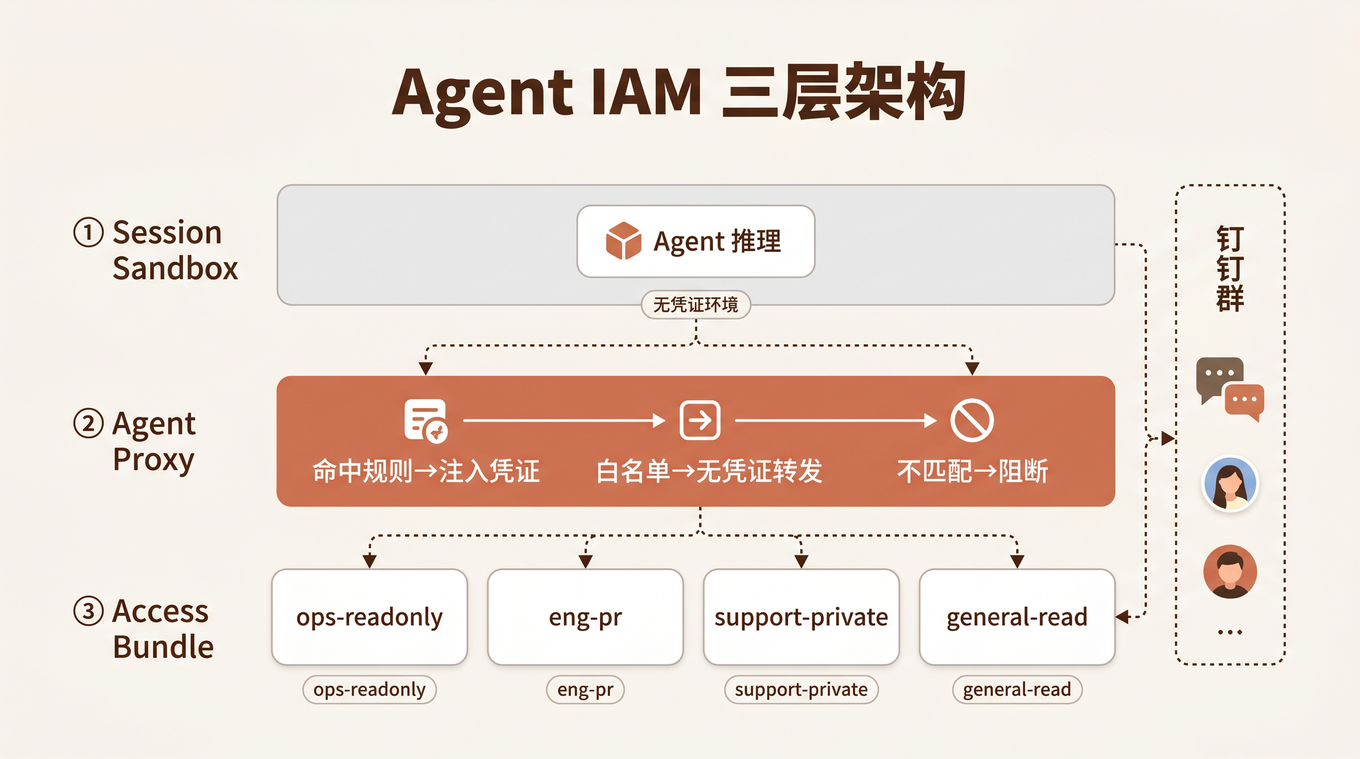
上周,一个同事在工作群里 @了一个 AI Agent,让它分析最近 30 天的客户退款数据。Agent 查了 CRM、翻了工单、跑了 SQL,两小时后在群里贴出一份报告。
事后审计时,安全团队问了一个问题:
「这个操作,日志里记的是谁?」
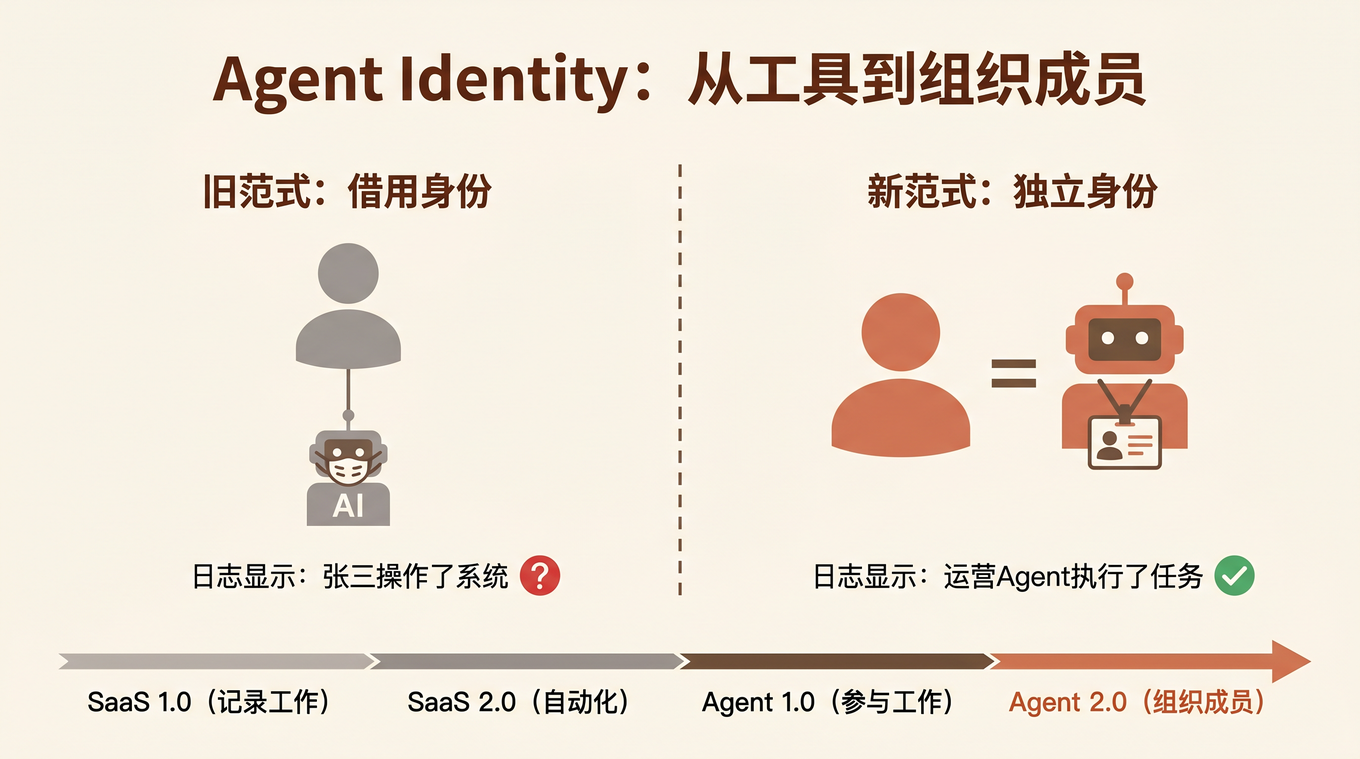
答案是:那个 @Agent 的人。
但实际上,读数据的是 Agent,推理的是 Agent,写报告的是 Agent。人只是说了一句「帮我看看」。
这就是今天几乎所有企业 AI 产品的现状——Agent 没有身份。它在借用人的身份做事。
2026 年 6 月 23 日,Anthropic 发布了 Claude Tag——一个运行在 Slack 里的 AI Teammate。表面上看,它是又一个 Slack 集成。但如果你仔细看它的架构设计,会发现一件有意思的事:Anthropic 正在尝试解决一个行业里很少有人正面回答的问题——
[Read More]Agent 到底是谁?
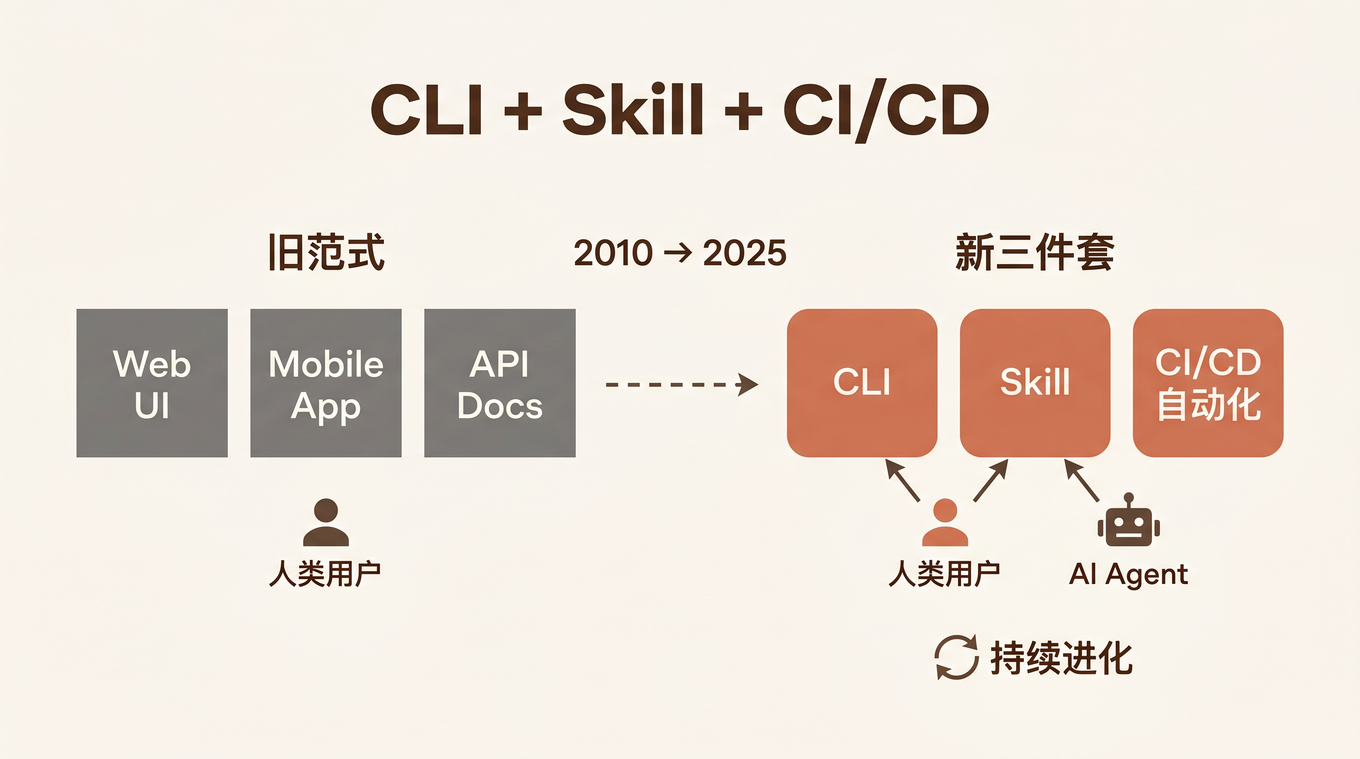
上周五晚上,我在给 ai-notepad 项目加一个功能:让 AI Agent 能自动发现并安装这个项目的 Skill。写完 SKILL.md、落地页、版本同步脚本后,我突然意识到一件事——这套流程已经不是「锦上添花」,而是应用交付的新底线。
如果你今天做一个应用,却没有提供 CLI 和 Skill,就像 2010 年做一个 Web 服务却没有 API 一样——用户(包括 AI Agent)根本用不了你。
上个月,一个做汽车零部件的朋友找我吐槽。他们花了大半年选了一个「国内最好的大模型」,又花了三个月搭了一套 Agent 系统,目标是让质检流程自动化。结果上线两周,业务部门集体退货。
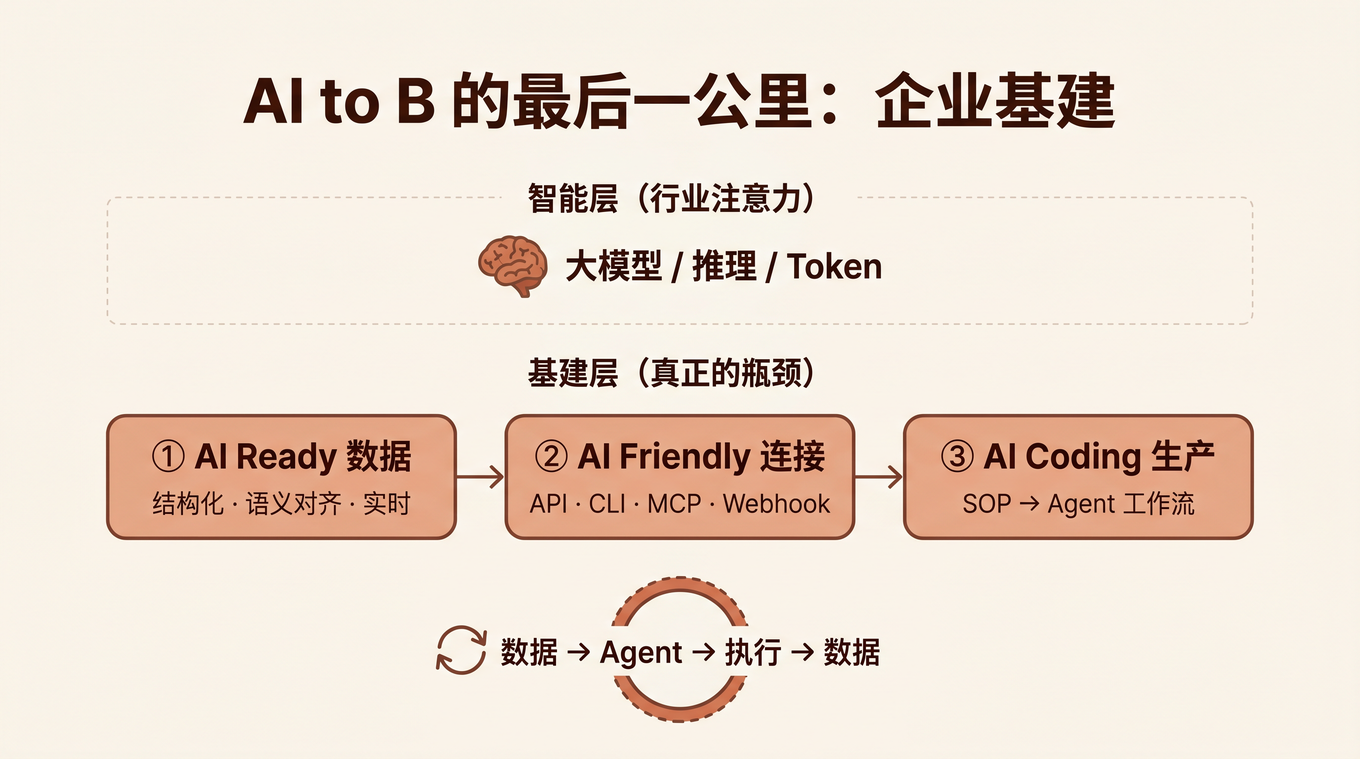
原因不是模型不够聪明。是 Agent 读不懂他们的质检数据——散落在 MES 系统、Excel 表格和钉钉群聊里的检测记录,格式不统一、字段不对齐、状态不可机读。Agent 也调不动他们的审批系统——OA 只有 Web 界面,没有 API,RPA 模拟点击三天两头因为页面改版而崩掉。
他说了一句让我印象很深的话:「我们的 AI 项目,死在了数据治理和系统对接上——这两件事,跟模型半毛钱关系都没有。」
上周,一个做 HR 的朋友给我发了张截图——某 SaaS 产品的面试评估表界面,问我:「这个东西,你们悟空能做吗?」
我没回答能不能做。我问她:「你手上有没有一个你已经在用的、类似的东西?哪怕是 Excel。」
她说有,一个用了两年的 Excel 模板,里面有公式、有下拉选项、有自动算分。
我说:「把它给我。」
拿到之后我想:如果我对悟空说一句 /goal 复制这个 Excel 模板的功能,生成一个钉钉 AI 表格工作流,面试评估表自动算分,结果推送到群聊——悟空能不能跑通?
技术上完全可以。dws CLI 有 AI 表格的建表、写数据命令,有审批流的提交命令,有群消息的发送命令。数据统一存在钉钉平台上,悟空通过 CLI 就能访问。整个路径是通的。
问题不在技术。 问题在于:当每个 HR、每个运营、每个项目经理都看到「我也想要一个那样的东西」,这种需求的总量是无限的。谁来供给?
[Read More]上周和一个做制造业的朋友吃饭。他的工厂有一条产线质检流程,沉淀了八年的 SOP,写在 47 页 Word 文档里,涵盖了从来料抽检到成品出货的 23 个检查节点。
他说:「这套流程是我们最值钱的资产之一。但执行全靠人——培训一个质检员要三个月,离职率 30%,新人上来又得重新学。」
我问他:「你想过把这套 SOP 变成 AI 驱动的工作流吗?」
他愣了一下:「谁来帮我做这个?我手下的 IT 团队连 ERP 都维护不过来。」
这就是当下最大的供需错配: 企业最有价值的资产是沉淀多年的 SOP,但没有人把它变成可执行的数字员工。
[Read More]