周五下午 4 点。你打开钉钉,你的 D 群里「本周的重点事项」消息已经发了 24 小时。16 位负责人被 @,每个人的进展回复散落在三个地方:有人私聊你说了三段话,有人在群里回了一个 emoji,还有人到现在一个字没发。
你要整理的,是一份让所有人都看得懂、能 action 的结构化进度报告。
手动做这件事需要 2-3 小时(经验估算)。你打开 16 个单聊窗口 + 群聊消息列表,翻来翻去。做得再仔细,也跑不掉三个 bias: recency bias ——最后看到的记得最清, salience bias ——写了一大段的人得到最多篇幅,写了三个字的人被一笔带过。 survivorship bias ——没回复的人直接消失在你的视野里,而不是被明确标记。
我手动做了这件事好几个月。然后写了一个 Agent Skill 文件——不到 200 行的 Markdown,把你的工作流程像岗位说明书一样写清楚。跑起来之后的效果不是「更快了」,而是 总结质量比手动好:每条来源可溯源、16 人全覆盖、没回复的标 ⚠️ 而不是消失。从 12 人扩到 16 人时,只改了 4 行映射表。
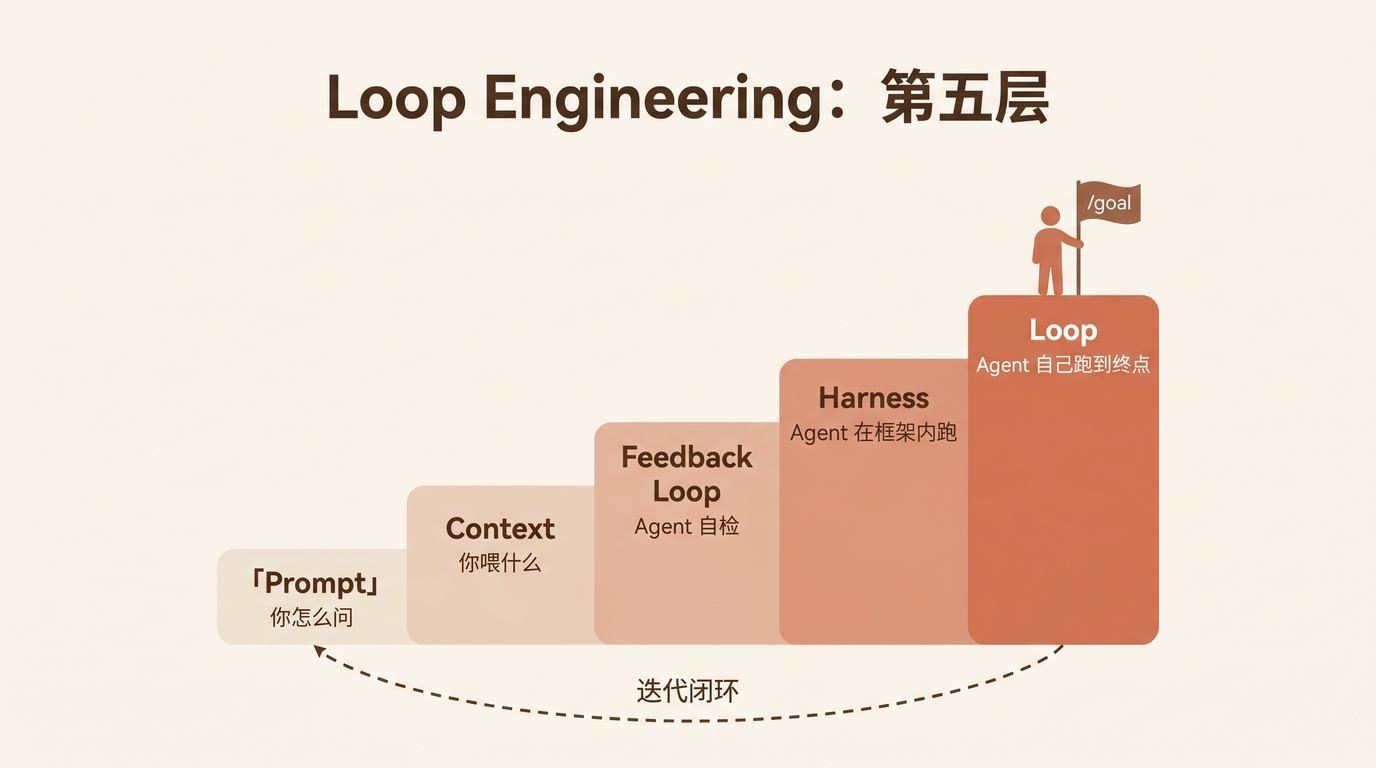
这篇文章讲的就是这个案例——以及如何把 Loop Engineering(让 Agent 自主跑到终点的工程方法)从写代码的场景,搬到管理协调的场景。
这个工程能落地,最关键的工具是 钉钉 DWS(DingTalk Workspace CLI)。DWS 是 Agent 与钉钉的统一接口层,它的设计让钉钉对 Agent 友好、对开发者友好。无论你使用哪款 Agent——OpenClaw、Hermes、OpenCode、悟空、MuleRun、WorkBuddy——都能通过 DWS 应用这套 AI 驱动的管理方法。Agent 是 fungible 的,接口层才是杠杆。
| 对比维度 | 手动汇总 | Agent Skill |
|---|---|---|
| 耗时 | 2-3 小时(经验估算) | Agent 运行约 10 分钟 + 人工审阅约 5 分钟(基于实际运行经验) |
| 覆盖率 | 高概率遗漏 1-3 人 | 16 人全覆盖,未回复显式标 ⚠️ |
| 可溯源性 | 凭记忆,无法定位原文 | 每条标注「单聊 MM-DD HH:MM」来源 |
| 扩展性 | 增加 4 人 = 多翻 4 个窗口 | 改 4 行映射表 |
| 一致性 | 受情绪/疲劳影响 | 相同输入 ≈ 相同输出 |