2023 年 3 月,一个名叫 Toran Bruce Richards 的开发者发布了 AutoGPT,两周内 GitHub Star 突破 10 万。他在 README 里写道:「给 AI 一个目标,它自己规划、自己执行、自己反思。」不需要你画流程图,不需要定义任务依赖——完全自治。
三个月后,Richards 的 GitHub Issues 页面变成了大型翻车现场。一个被反复引用的案例:用户让 AutoGPT「研究人工智能的历史」,Agent 搜索了 10 篇文章,保存,然后又搜索了 8 篇,再保存,然后检查自己保存的文件,然后重新搜索……无限循环,API 费用烧了几十美元,一事无成。AutoGPT 的 GitHub 仓库里记录了超过 200 个类似的 infinite loop issue。
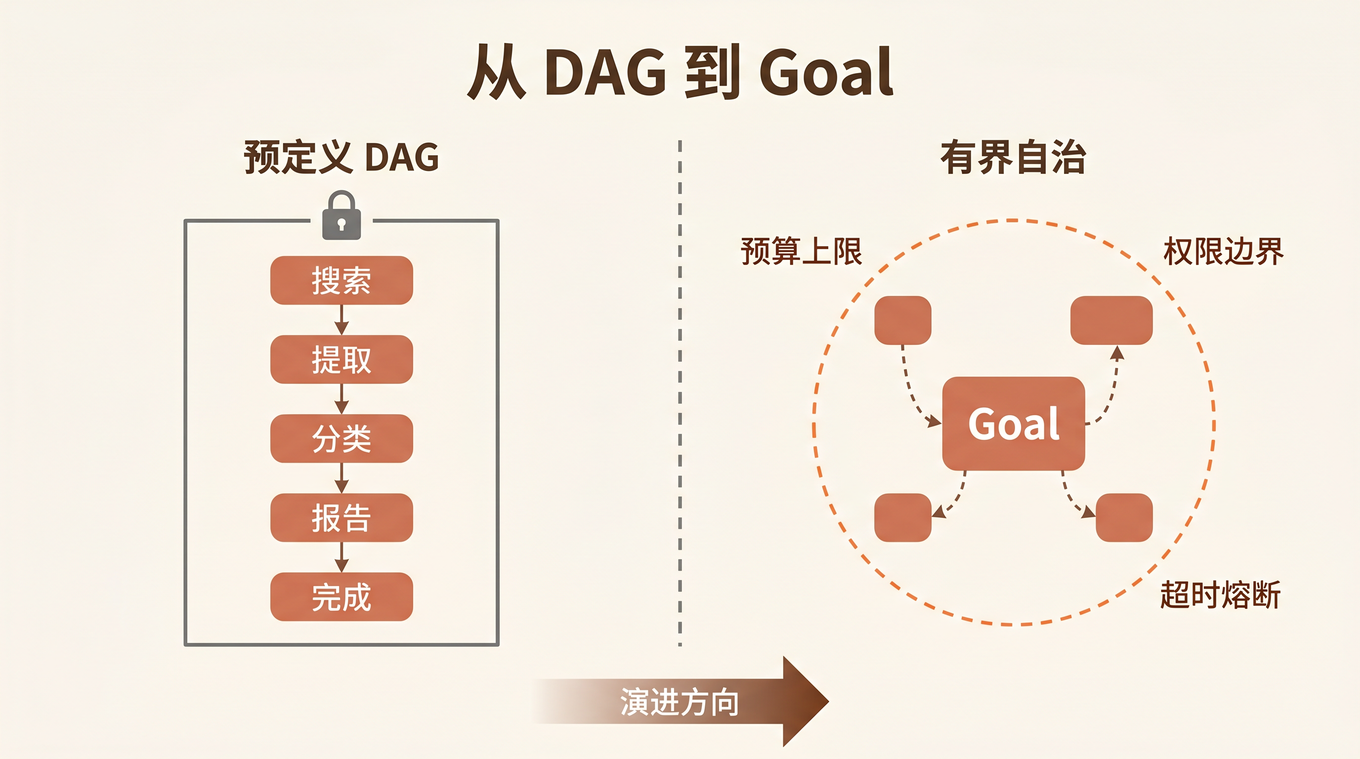
AutoGPT 的失败让行业得出了一个看似正确的结论: Agent 需要预定义的执行图。于是 LangGraph 成了 2026 年最受欢迎的 Agent 框架——62% 的开发者选择了它,正是因为它提供了精细的状态机控制和可预测的执行路径。
但我跟很多在用 LangGraph 的团队聊过,他们私下都在抱怨同一件事: 画图太痛苦了。 每增加一个能力,就要重新设计图的拓扑结构;每遇到一个边界情况,就要加一条边和一个条件分支。开发者的时间,一半花在写 Agent 逻辑,另一半花在维护那张 DAG。
这就引出了一个真正的问题:DAG 是答案吗?还是我们在 AutoGPT 的阴影下过度矫正了?