上周和一位做 Notion 类产品的创业朋友 Hugo 深聊。他们团队 5 个人,技术栈很现代:Rust 后端 + CRDT 协作引擎 + React 前端。全员配了 Cursor/Copilot,编码效率确实起飞了。
但他抛出一个让我后背发凉的数据:
“写代码快了 10 倍,但端到端交付只快了 2 倍。剩下的时间差,全耗在给 AI 擦屁股上。”
他给我看了一个真实案例。新人小李接到任务:“新增一个代码块类型,支持语法高亮和行号。”
没有 Harness 的灾难:
- 小李让 Agent 生成代码(5 分钟,看起来完美)
- Agent 不知道团队半年前从"嵌套 JSON"迁移到"扁平化 parent_id"的架构决策,生成了嵌套方案
- 小李没看出来(新人不懂历史),提交 PR
- CI 失败:循环引用检测拦截(嵌套结构在协作同步时会死锁)
- 小李让 Agent 修复,Agent 为了绕过检测,直接改了权限校验逻辑(越界)
- 老王 Review 时发现 3 个深层问题:CRDT 冲突策略不对、离线同步没考虑、权限模型被破坏。打回。
- 反复 3 轮,耗时 2 天。老王叹气:“还不如我自己写。”
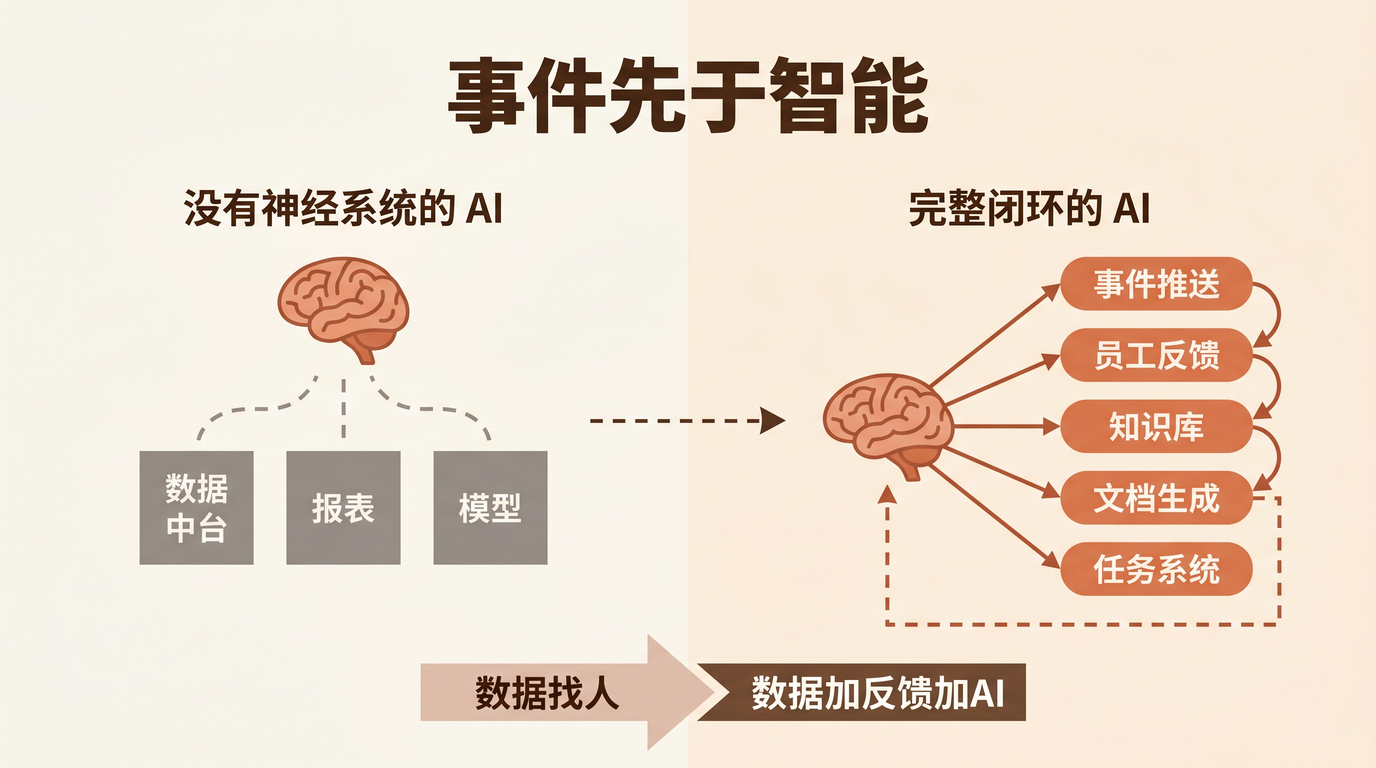
问题本质:AI 把编码压缩了,但把 隐性知识的缺失放大了。
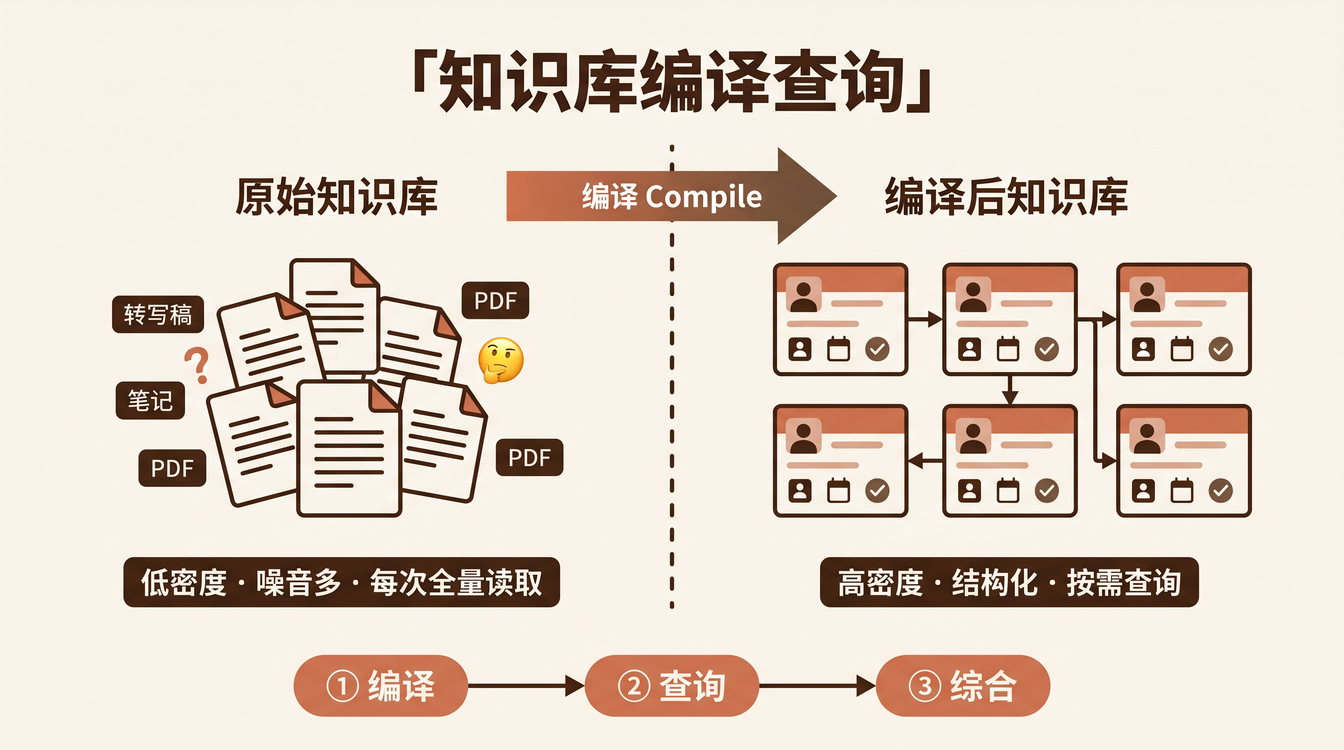
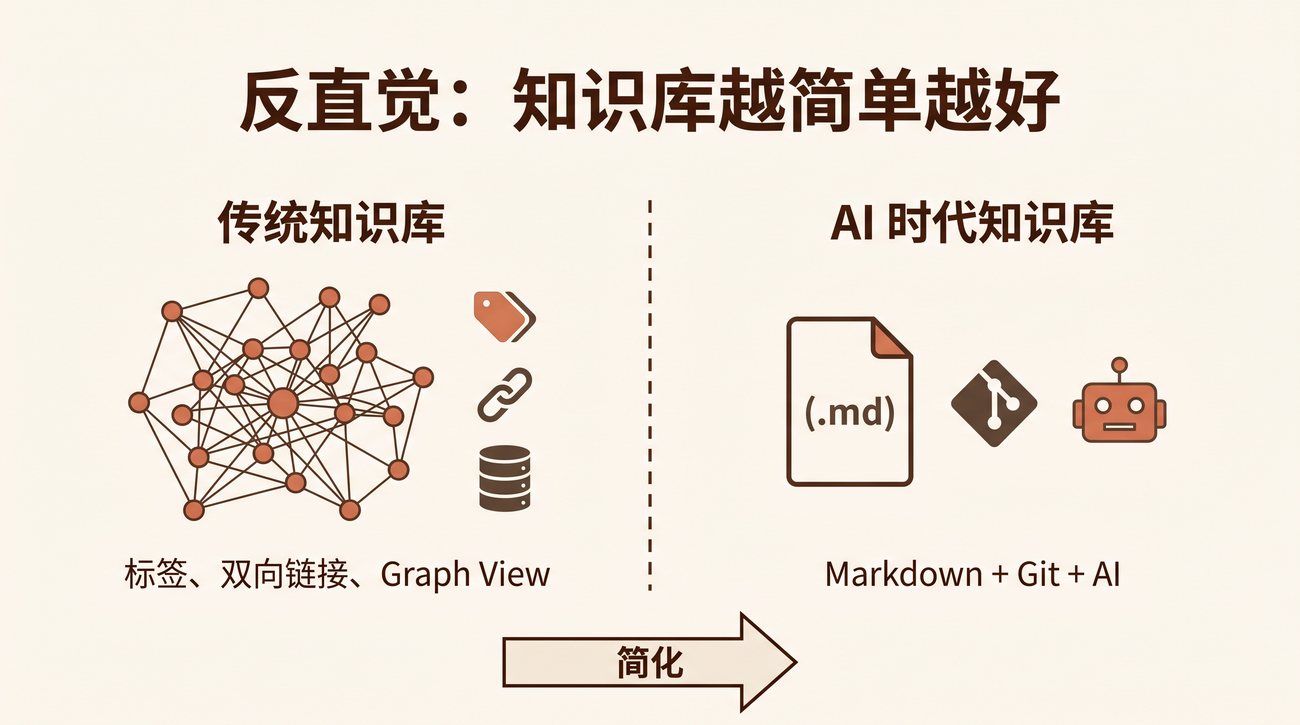
过去靠"问老王"填补的架构决策、历史坑位、协作潜规则,AI 一概不知道。阿里技术许晓斌称之为 人肉中间件现象:员工沦为 AI 与业务系统间的手工搬运工。腾讯技术工程则指出:Harness 不是目的,知识才是护城河。
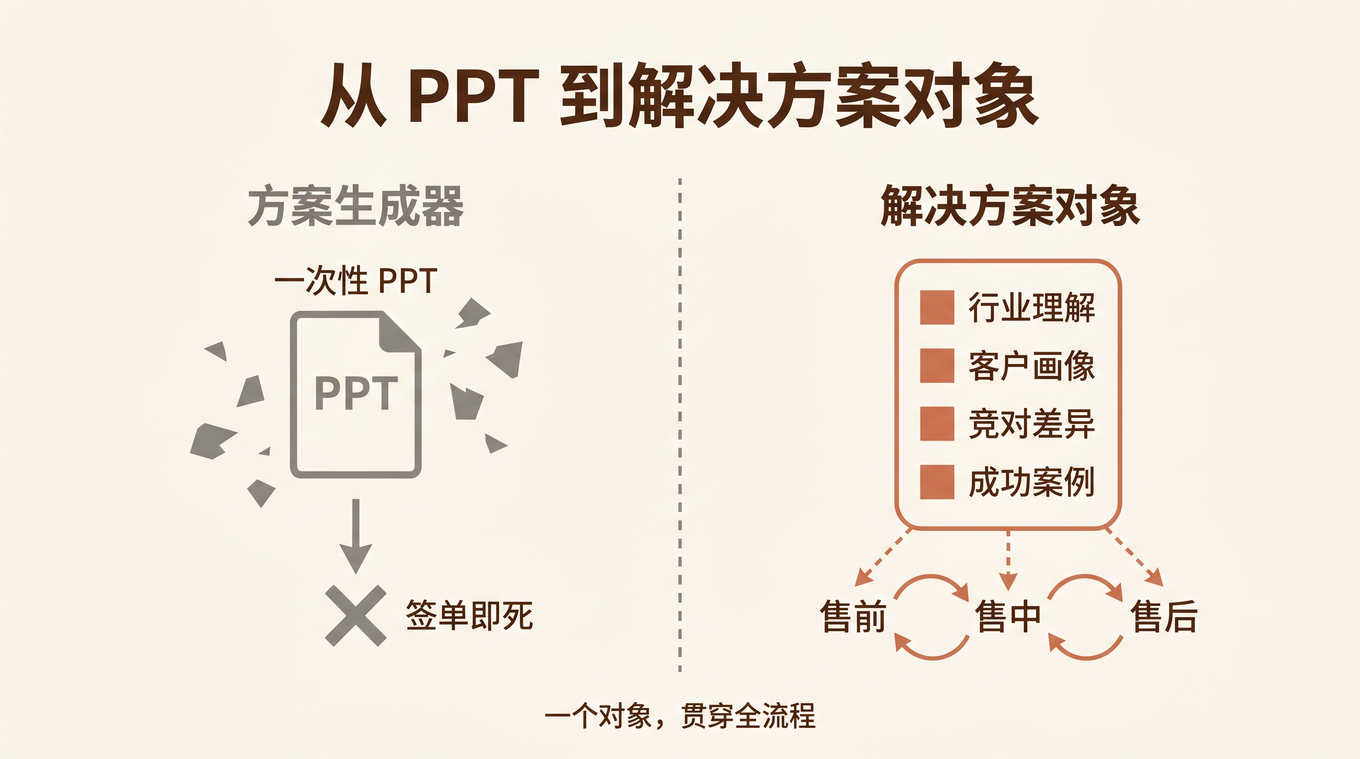
这篇文章,就以这个 5 人 Notion 团队为案例,完整拆解他们如何用 三层架构(组织 × 资产 × 工程) 构建 Harness 系统,把"给 AI 擦屁股"变成"AI 自主交付",实现知识复利。
[Read More]