团队里的小王和小李都在用同一个 AI Agent 平台。
小王输入:「帮我总结一下今天群里的讨论。」
Agent 调用了 fast/small 模型做意图识别,然后用 medium 模型读取了 200 条消息,生成了摘要。耗时 3 秒,花费 0.02 元。
小李输入了完全相同的指令。
Agent 却调用了 large/reasoning 模型,不仅做了摘要,还自动关联了小李上周的项目文档,识别出了三个待办事项,并推送到了他的日历。耗时 12 秒,花费 0.15 元。
同样的输入,完全不同的执行路径。
这不是 bug,而是一个成熟的 Agent 系统应该具备的能力——根据用户画像、历史行为、任务上下文,动态决策每一步该用什么模型、什么工具、注入多少上下文、以什么并发度执行。
当你的 Agent 只有 100 个用户时,这些问题还不明显。你可以手动调几个规则,给 VIP 用户分配更好的模型,给普通用户限流。靠人肉运维,系统也能跑。
但当用户量从 100 涨到 10 万、100 万,当模型供应商从 1 家变成 10 家,当工具调用从几个 API 扩展到上百个——靠人写规则来调度,系统会直接崩溃。
不是因为规则写不出来,而是因为规则的组合空间是指数级的:
- 7 种任务类型 × 5 个复杂度等级 × 10 个模型 × 4 种用户画像 × 3 种上下文策略 = 4,200 种路由组合
- 这还只是单节点决策。如果任务被分解为 3-5 个子节点,每个节点独立路由,组合数直接爆炸到 百万级
没有人能手动维护百万级的路由规则表。
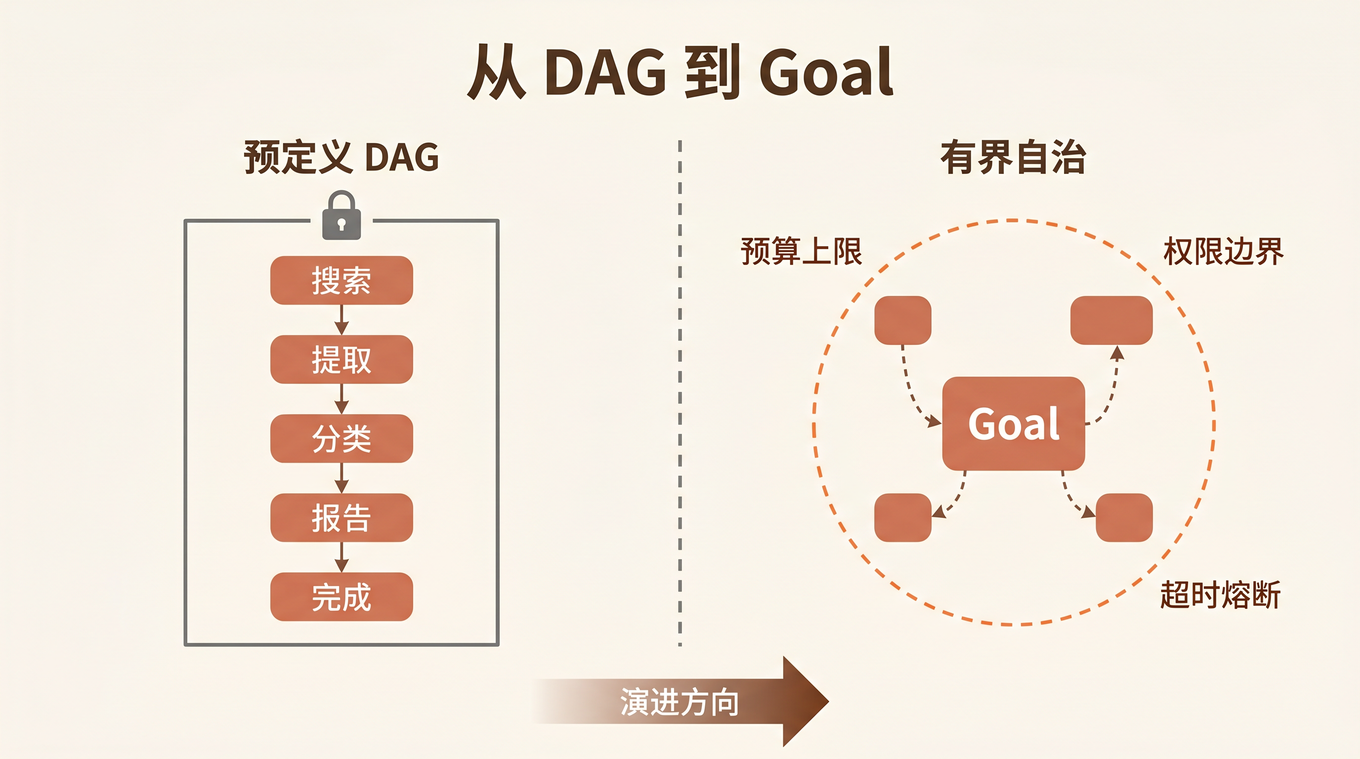
大多数 Agent 框架把执行路径写死在代码里:先调用 A 模型,再调用 B 工具,最后返回结果。这在 demo 阶段没问题,但一旦面向规模化用户,就会暴露三个致命问题:
- 成本失控——所有用户都用最强模型,简单任务也在烧钱,规模化后月账单直接六位数
- 体验一刀切——新手和专家拿到相同的结果,没有人觉得「懂我」,留存率上不去
- 无法进化——系统上线后不会从用户反馈中学习,规则越写越多,越用越僵化
这篇文章,我们来拆解如何构建一个动态路由决策系统(Dynamic Routing Decision System, DRDS)——一套端到端的自进化引擎,让 Agent 的执行路径真正做到千人千面,并且在规模化下持续学习、自动优化。
核心观点:自进化不是 Agent 的「加分项」,而是规模化后的「必选项」。
[Read More]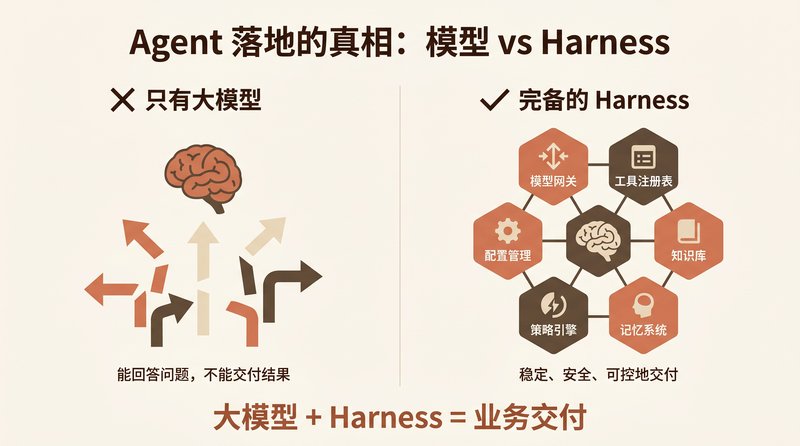 从只有大模型到完备 Harness:7 个组件缺一不可
从只有大模型到完备 Harness:7 个组件缺一不可