上个月,我发现一个跑了 3 周的定时任务每天都在用 Claude Sonnet 4 做一件极其简单的事——搜索两条关键词、整理成表格、发给我。每次消耗约 8000 token,成本 $0.12。换成 GPT-4o-mini,同样的任务 2000 token 就够,成本 $0.003。
3 周 × 每天 $0.12 = $2.52。换成 mini 只要 $0.06。
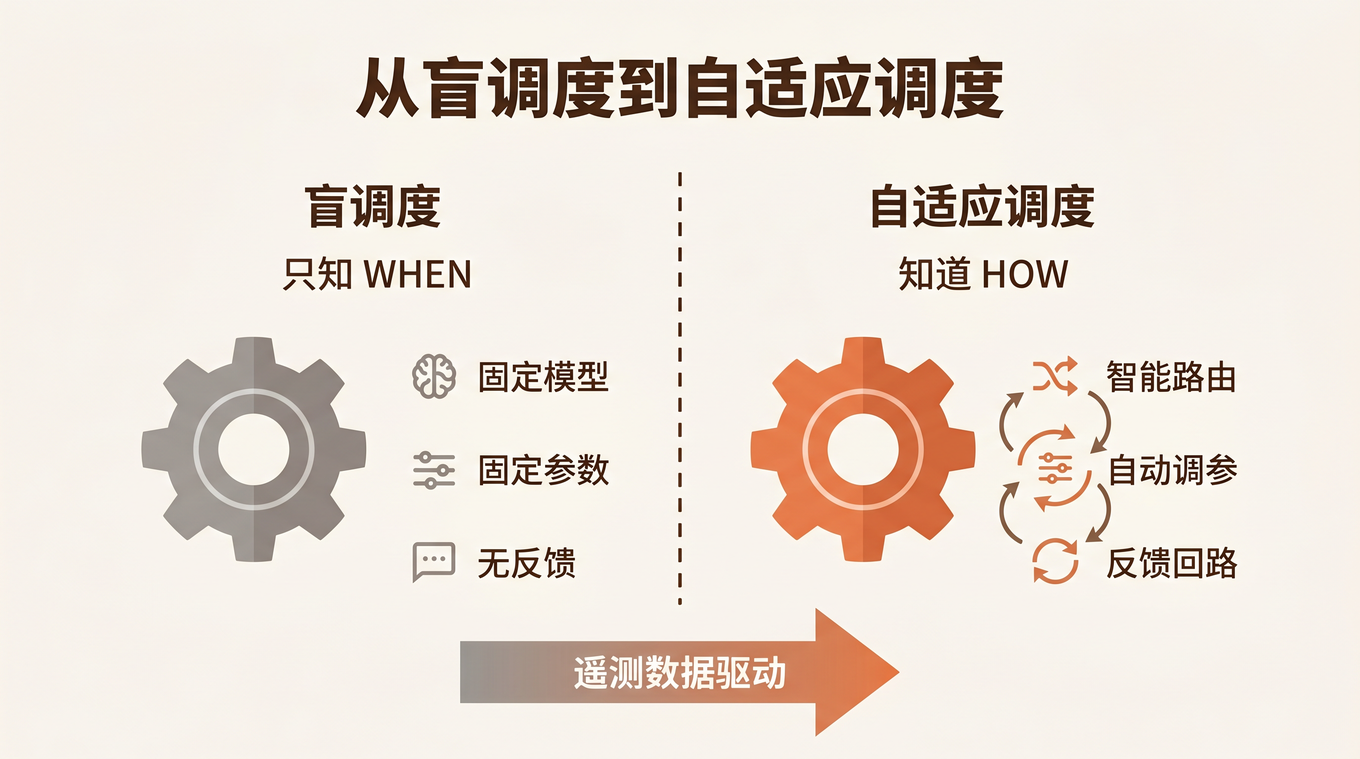
这不是模型的问题,也不是调度器的问题——是 调度器和模型选择之间缺了一层。你的 cron 系统知道什么时候该跑这个任务,但完全不知道该用什么模型、多少推理深度来跑。