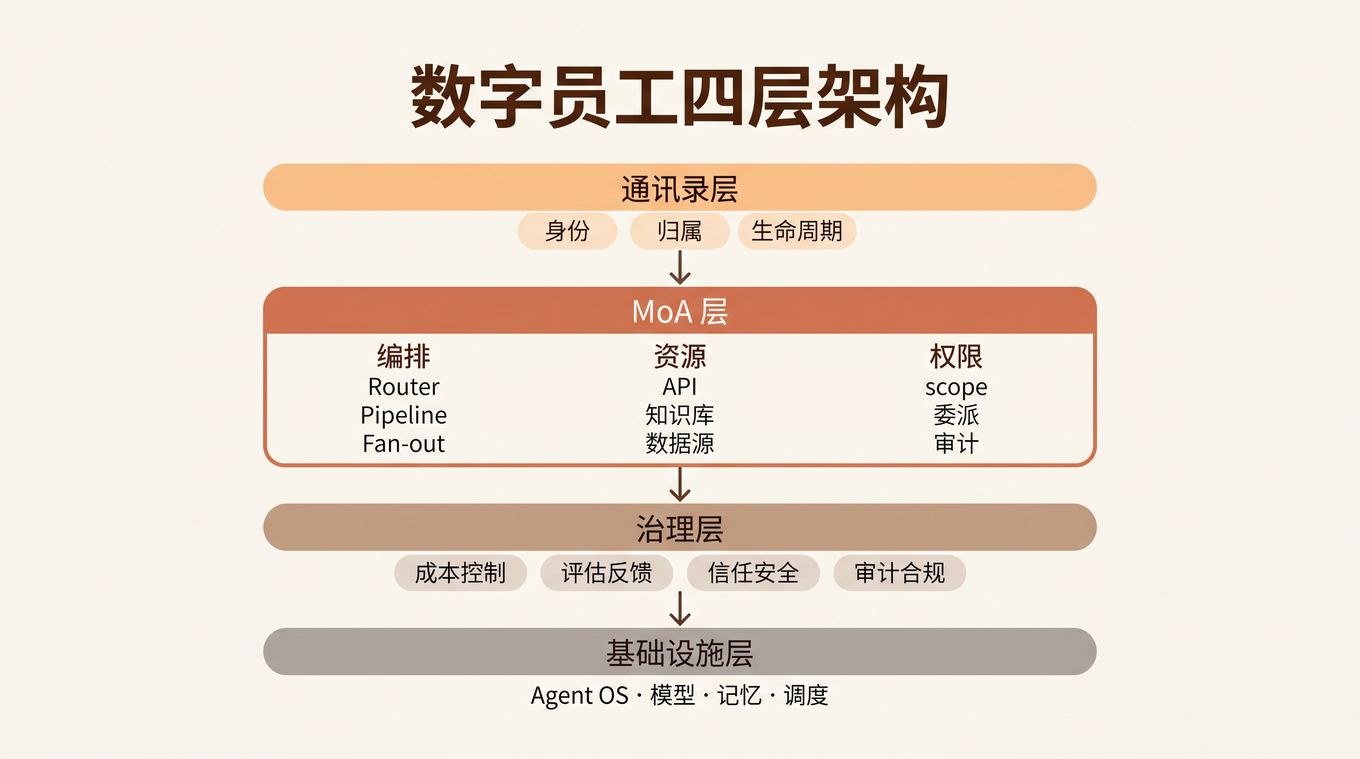
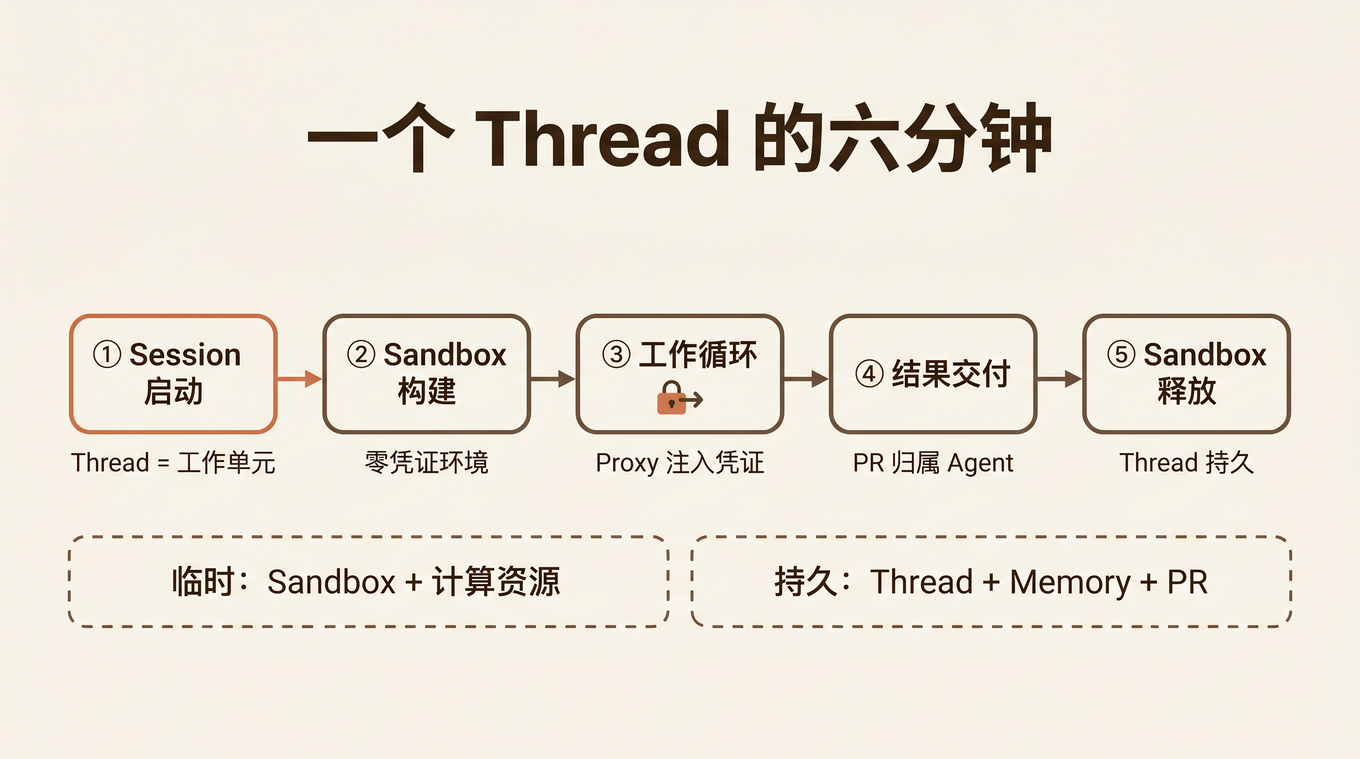
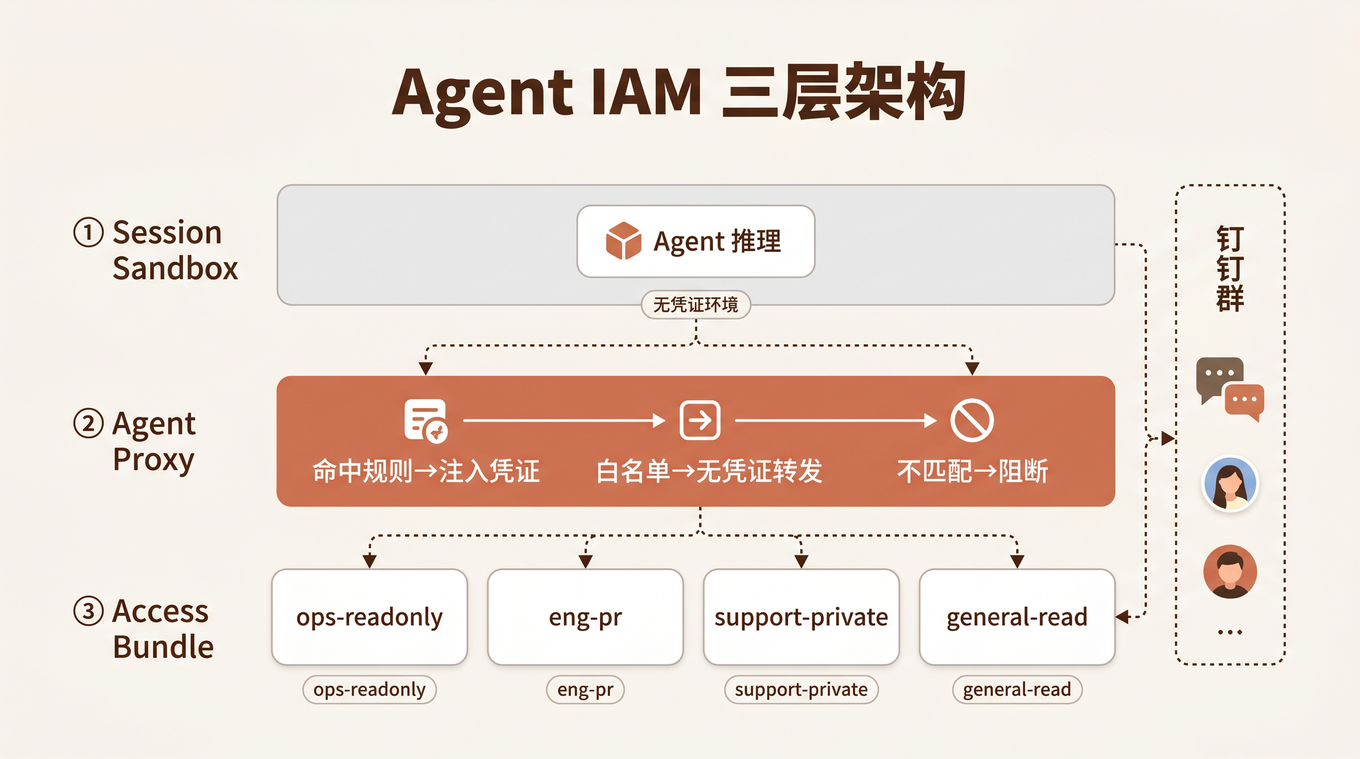
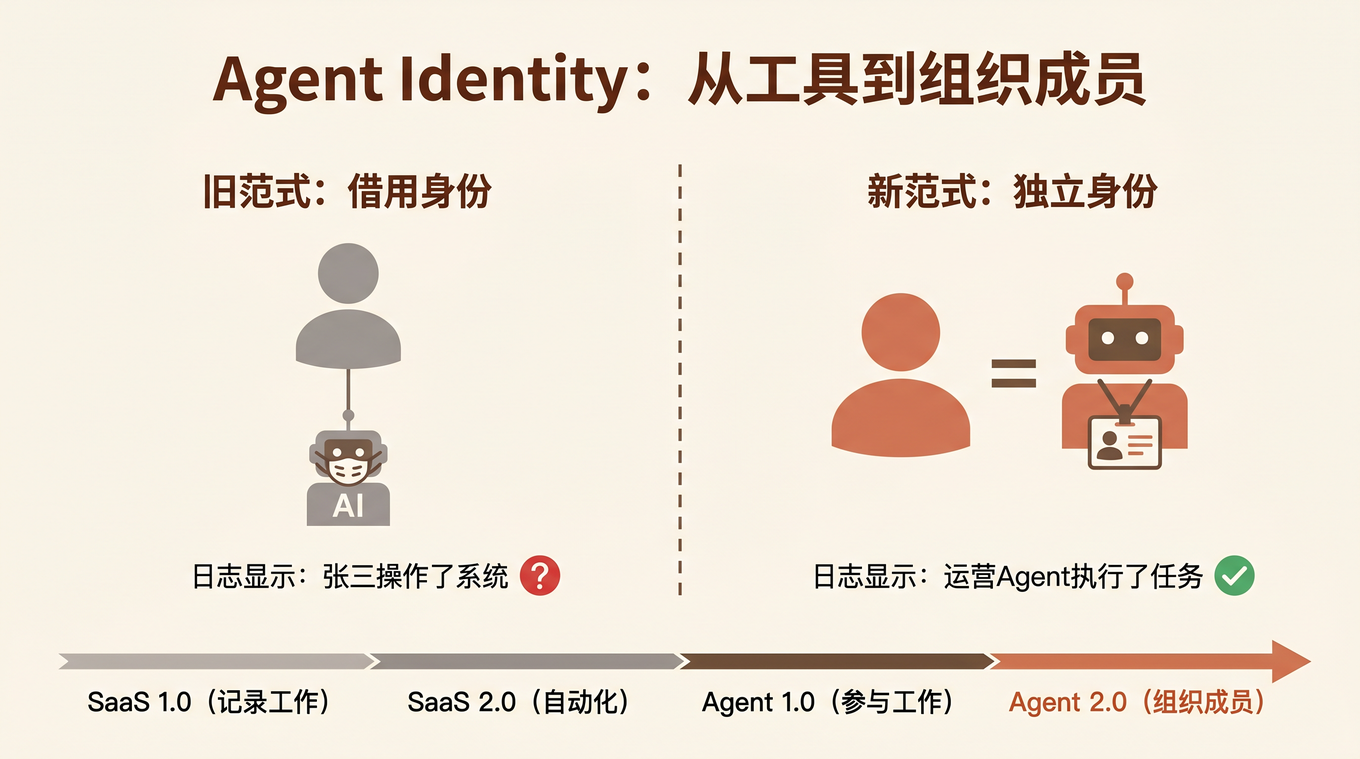
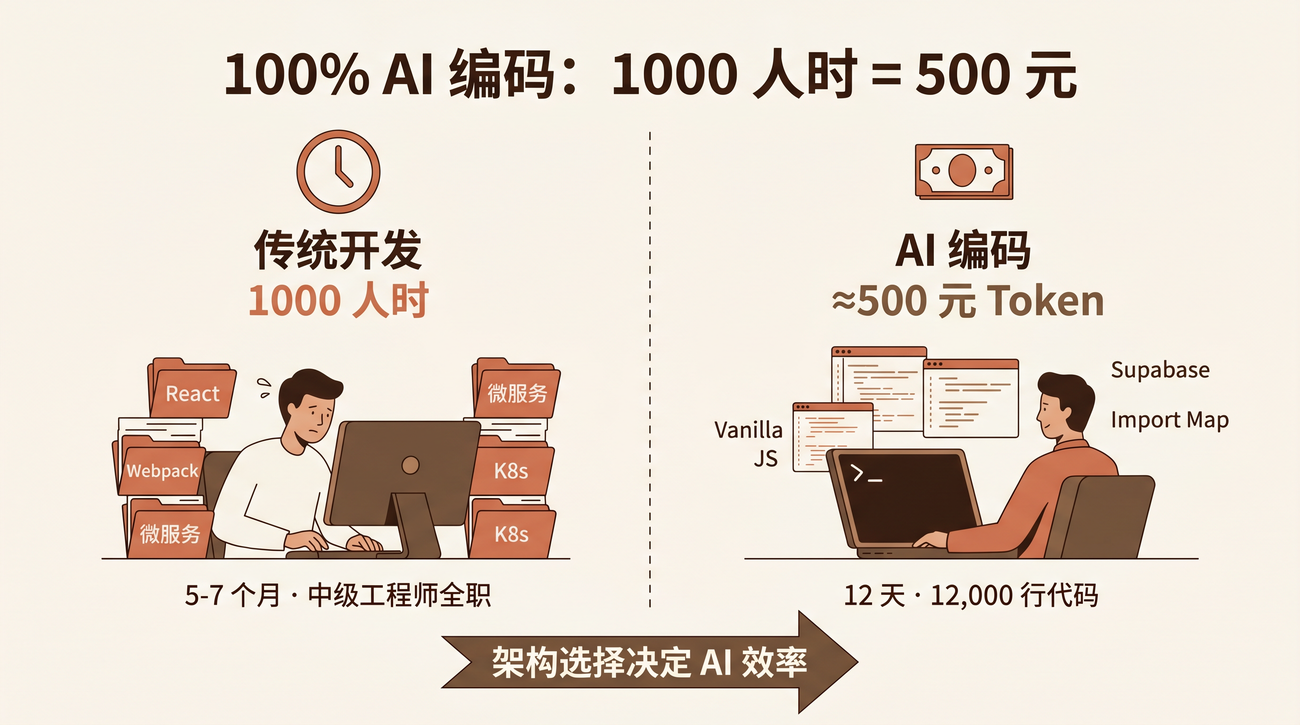
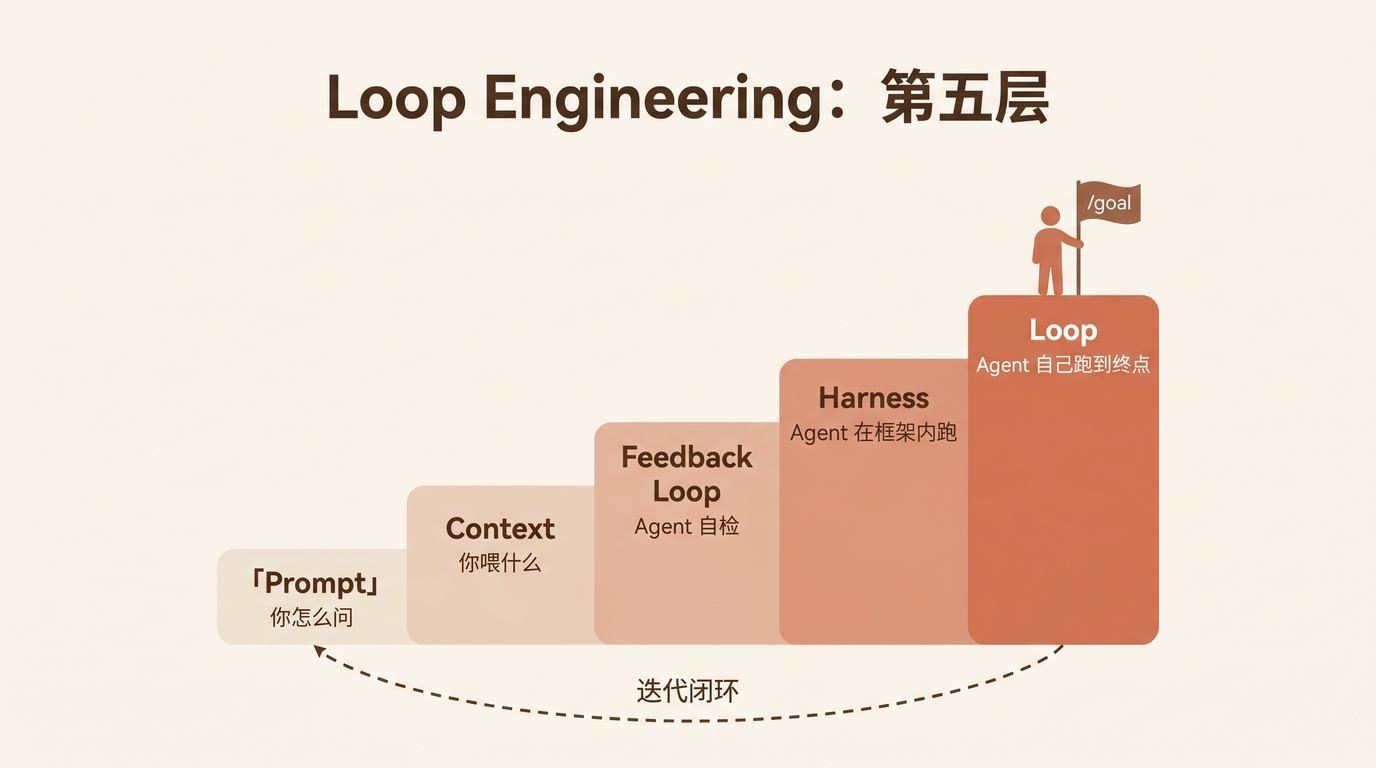
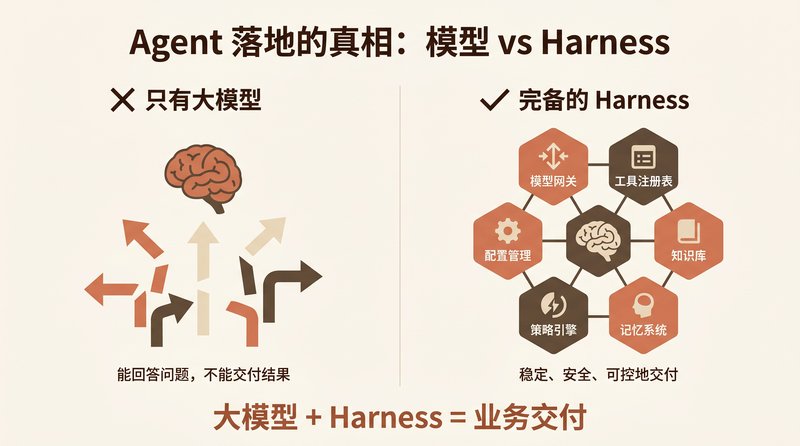
 从只有大模型到完备 Harness:7 个组件缺一不可
从只有大模型到完备 Harness:7 个组件缺一不可
上周我让 Agent 帮我写了一篇博客。
它从我的 wiki 里读了 5 篇历史文章做去重分析,生成初稿后自己跑了一轮对抗性评审打了 18 分,然后用 Gemini 生了一张配图、resize 到 1360px 以下、压缩成 948KB 的 PNG,再跑了一遍中文排版修复,最后 commit 推到 GitHub,等 CI 构建完成后自己验证了上线 URL。
整个过程我做了三件事:选了一个标题方向,补了两处内容,说了三次「发布」。
这套流水线跑了 4 篇博客(#290 到 #293),每篇都是这个流程。它不是 demo,是真实的生产管线。
但我回头看这套东西的时候,发现一个问题: 我搭出来的不是一个 Agent,是一个 Harness。
[Read More]